
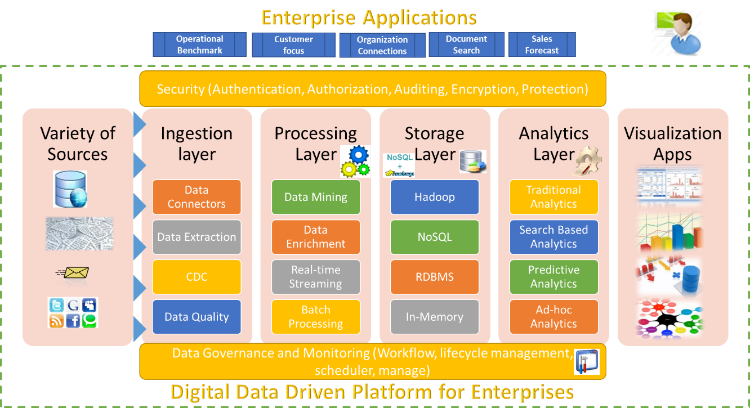
The role of the Enterprise Data Platform is to supply an enterprise with the data needed for analytics, decision making, planning, and communication. In prior articles, we covered the readiness of the Enterprise Data Platform for digital transformation and data ingestion (mechanisms and tools for ingesting various kinds of enterprise data). This article, co-authored with Shirish Joshi, deals the Data Processing and Preparation layer (highlighted in the diagram below), whose job is to prepare the data required for storage and analysis. We will discuss this function in the context of enabling Digital Transformation responsive to the business needs of the organization, i.e., enabling deeper analytics across a wider variety of data in a flexible and agile manner. It is increasingly common for information from various sources to be integrated into a single common organization-wide shared repository (the so-called “Data Lake”); the job of the Processing Layer is to process this “big” data, handling the issues of volume, velocity, and variety. The consumers of the processing layer are the various inhabitants of the Analytics Layer: enterprise data warehouses (Operational Analytics), discovery platforms (Ad-hoc Analytics), Predictive Analytics, and knowledge platforms (Search Analytics).
Capabilities
The Processing Layer needs to have certain capabilities to handle the needs of Enterprise Digital Transformation at scale.
- Mirroring input data in raw storage: The fidelity of the original data is preserved by mirroring the data sources. Dark data is of no use to anyone. Making as much of the data available for further processing is in the interest of the enterprise. Unlike in traditional data processing, discarding extraneous data and applying structure to data comes much later.
- Common, organization-wide repository: Robust, manageable storage for this common data repository is of utmost significance, and will be discussed in the article on the Storage Layer.
- Integration: Data ingested for a particular domain/subject-area is often similar, duplicate, complementary, fragmented, or even conflicting. Comprehensive matching and merging needs to be done to ensure integration of data and arrive at a single version of the truth. Value extraction from the volume-variety-velocity of data without integration and correlation is not possible. In the integration step, various algorithms like entity recognition, de-duplication, and matching serve to co-relate data based on key attributes.
- Transformation: Transformations tailor the data to the needs of the consumers. Lineage preservation is an important part of data governance, and needs to be remembered during transformation. Late transformation is a feature of the Data Lake architecture that allows a flexible and agile data processing pipeline. Transformations may involve operations such as aggregation, mapping, calculating, filtering, or joining.
Components
The components of the Processing Layer are collectively responsible for preparing data. While seemingly straightforward, components in this layer are the key to ensure timeliness and readiness of the data for consumption. The transformation muscle needs to do a lot of heavy lifting to handle data at scale. The following are the major components of this layer.
- Infrastructure: To serve the needs of the agile, growing, and information-hungry organization, Data Governance, Rich Metadata, and Provenance are important supporting infrastructure components of the Data Processing Layer. Strong data quality and governance practices are important to retain the value of the Data Lake as a reservoir. With greater access, greater control and security is required to prevent misuse and abuse.
- Real-time streaming: This component is where data is received in smaller chunks (a few rows, or per second/minute interval), and it reacts to the data as it arrives. The reaction is often the result of applying a set of rules on the arriving data, in the context of the data that has been pre-computed in the data store. Low latencies are required here. Data in this component is characterized by incremental changes (like counters), or events.
- Batch processing: This component is where data transformations happen on a periodic basis. Any heavy-duty or expensive processing happen here, to create data in a format useful for downstream users of the data. Operations are fairly complex in nature (characterized by re-computations or complex aggregations) and typically take place over a very large and growing set of records. Resiliency of storage, scaling large operations, and the ability to restart are pertinent here.
- Data enrichment: Making use of data from multiple sources, and combination of the data after the integration phase, results in data enrichment. Enrichment may be performed using public data sources (like census or map data), data vendors (e.g., Dun & Bradstreet, Bloomberg, Reuters), or social media. Enrichment may also use past transaction data. Typical use cases are profiling, segmentation, and 360 degree view.
- Mining of Single-Subject Area and Cross-Subject Area Data: Single-subject area mining can be performed before the integration step, while cross-subject mining is performed after this step. Mining is carried out on the large volume of data, usually after Batch Processing. This step provides value to organizations especially in areas such as customer support, social media and outreach analysis, recommendation engines, and planning & optimization. Popular mining algorithms include Classification (such as C4.5, SVM, AdaBoost, kNN, Naïve Bayes, CART), Association Analysis (A-priori), Clustering (k-means, Expectation Maximization), and Network Analysis (PageRank). After the ingestion phase, these algorithms are applied as part of the data exploration, data science, or sandbox operations.
Tools and Technologies
| Objective | Desired Solution Characteristics | Sample tools |
| Data Mining | Algorithms at scale | Apache Mahout, Apache Giraph, GraphX |
| Real-Time Processing | Rapid ingestion, quick response, high frequency | Apache Storm, Apache Spark Streaming |
| Batch Processing | Ability to handle range from small transformations to very large re-computations | Apache Pig, Apache Hive,Cascading, Apache Spark,MapReduce |
| Data Enrichment | Combining data from multiple sources at scale | Big Data Editions of ETL tools, and all of the above Batch Processing tools |
Comparisons to the Lambda Architecture model
Nathan Marz (the creator of Apache Storm) in his book “Big Data: Principles and best practices of scalable realtime data systems” has proposed the Lambda architecture, with a Speed Layer, a Batch Layer, and a Serving Layer. The Real-Time Streaming and Batch Processing components correspond to the Speed Layer and Batch layer respectively. The Serving layer corresponds to the Analytics layer.
Conclusion
Organizational processes at innovative enterprises are continuing to become less fragmented and more unified ([Weill 2007], [Ross 2009]). Coordination and replication overheads are being eliminated. As a pre-requisite for business processes to unify, sharing of data and decision making processes is required, often by employing a Data Lake. Digital Transformation through a unified Information Access Platform can be required to give business users, and analytics applications access to all the data of the organization (breadth of data, detailed granularity of data, and historical data). To make this shared data usable, data preparation at scale is needed; and this is the job of the Data Processing Layer.
Dr. Siddhartha Chatterjee is Chief Technology Officer at Persistent Systems. Shirish Joshi is a senior architect at Persistent Systems.
Image Credits: Wikimedia Commons/Paul Frederickson



Find more content about
Big Data (18) digital transformation (49) data integration (2) Data Mining (1) data processing (1)











