
Studying adverse drug reactions in patients due to the presence of certain chemicals is central to drug development in healthcare. Pharmaceutical companies often want to understand the conditions and pre-conditions under which a drug might cause adverse reactions to prevent any harm to the patient.
Understanding the co-occurrence of disease and chemicals in the Electronic Health Record (EHR) of a patient is useful for most pharmaceutical companies. However, EHRs are unstructured in nature and require additional processing to extract structured information such as named entities of interest.
Such extraction can lead to significant savings of manual labor and minimize the time taken to get a new drug to market. Recent advancements in machine learning take advantage of the large text corpora available in scientific literature as well as medical and pharmaceutical web sites and train systems for several NLP tasks ranging from text mining to answering questions.
The specific problem we focused on in our experiments was extracting adverse drug reactions from EHRs using NER. The solution required us to extract key entities such as prescribed drugs with dosage and the symptoms and diseases mentioned in the EHRs. The extracted entities would be processed further downstream to link entities and leverage dictionary-based techniques for flagging any symptoms which could potentially be adverse drug reactions to the prescribed medicines.
Healthcare Named Entity Recognition Tool
The Named Entity Recognition models built using deep learning techniques extract entities from text sentences by not only identifying the keywords but also by leveraging the context of the entity in the sentence. Furthermore, with language model pre-trained embeddings, the NER models leverage the proximity of other words which appear along with the entity in domain-specific literature.
One of the key challenges in training NLP-based models is the availability of reasonable-sized, high-quality annotated datasets. Further, in a typical industrial setting, the relative difficulty in garnering significant time from domain experts and the lack of tools and techniques for effective annotation, along with the ability to review such annotations to minimize human errors, affects research and benchmarking of new learning techniques and algorithms.
To bridge the gap between academic development and industrial requirements, we designed a solution employing transfer learning from pre-trained models while working with subject matter experts to annotate a comparatively smaller dataset.
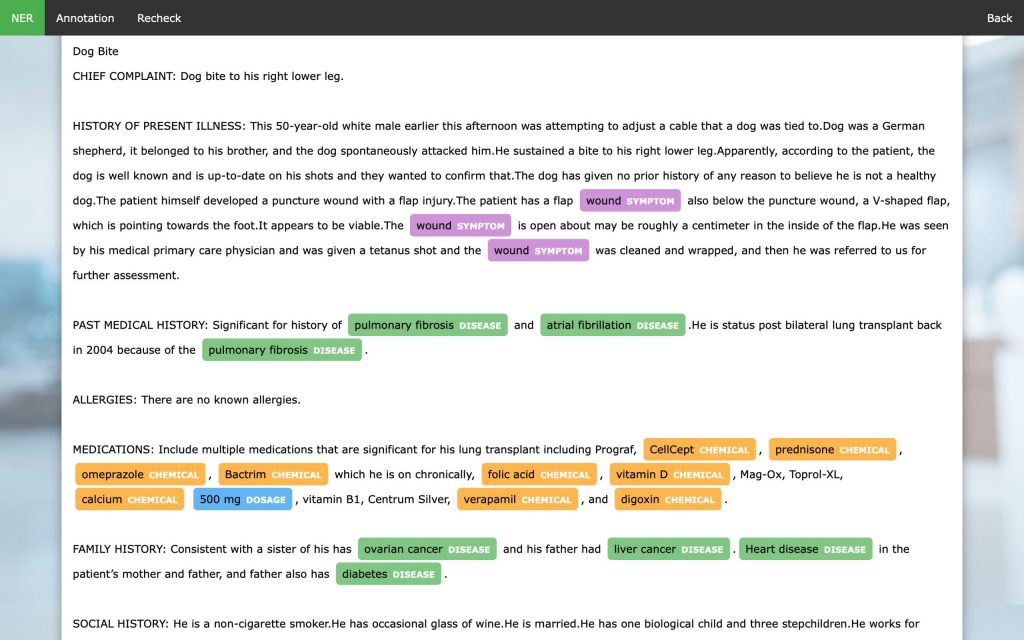
At Persistent, we built a custom web browser-based tool which helps minimize time commitments from domain experts and the manual effort required to generate such a training dataset. The following figure displays a screenshot of the annotation tool.
In-house Annotation Tool
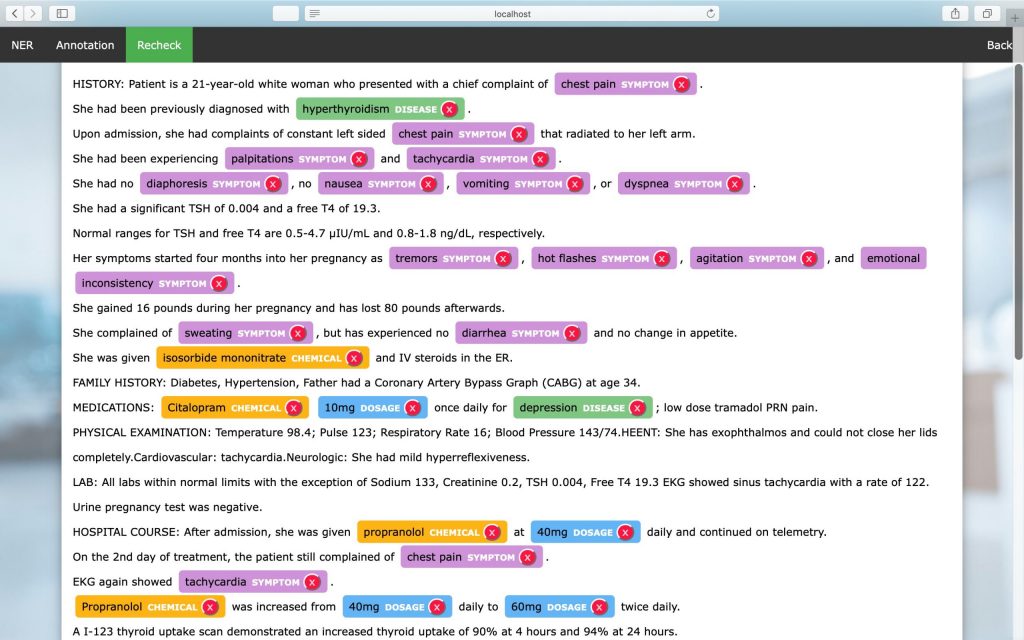
As seen in the snapshot, the tool works with text files and the user provides annotations using a mouse and keyboard inputs. After marking the required span of text using the mouse, the user can use keyboard keys to annotate the selected span. For example, the ‘S’ key on the keyboard represents the Symptom entity. On providing inputs, the tool highlights the span with a specific color for each entity and adds an entity name on the screen with a cross mark to make corrections. The tool also has a recheck functionality to enable the reviewer to re-examine annotations.
After initial annotations, we utilized the annotated data to train a custom NER model and leveraged it to identify named entities in new text files to accelerate the annotation process.
Additionally, models like NER often need a significant amount of data to generalize well to a vocabulary and language domain. Such vast amounts of training data are often unavailable or difficult to synthesize. To overcome this challenge, we can leverage transfer learning to improve NER models. Transfer learning techniques are largely successful in the image domain and are advancing steadily in the natural language domain with the availability of pre-trained language embeddings and pre-trained models. Recent advancements in NLP, also known as the ImageNet moment in NLP, have shown significant improvements in many NLP tasks using transfer learning. We leveraged the scispaCy pre-trained model as our base model and applied transfer learning to obtain our custom NER model.
Language models like ELMo and BERT have shown the effect of language model pre-training on downstream NLP tasks. Language models can adjust to changes in the textual domain through fine-tuning. Given all this, we can adjust to new domain-specific vocabulary with very little training time and almost no supervision.
In order to improve the performance of transfer learning models further, we employed a newly released spaCy package feature for pre-training. Pre-training allows us to initialize the neural network layers of the NER deep learning model with a custom word vector layer. We obtained our custom pre-training layer by using a large un-annotated domain-specific text corpus. This domain-specific text corpus was collated by putting together a large set of publicly available medical notes.
Our experiments present empirical results which corroborate the hypothesis that transfer learning delivers clear benefits even while working with a limited amount of training data. A key observation of the results presented is that the F1 score of a model trained with our approach with just 50% of the available training data outperforms the F1 score of the NER model trained from scratch with 100% of the available training data. We recommend that while building industry solutions, leveraging pre-trained models that have a partial overlap with the entities provides clear benefits.
Our approach to the problem using a custom annotation tool and pre-training techniques can be utilized and extended to multiple NLP problems, such as Machine Comprehension, FAQ-based Question-Answering, Text Summarization, and more. The techniques are application domain-agnostic and can be applied to any industrial vertical such as, but not limited to, banking, insurance, pharma, and healthcare where domain expertise is required.
For more details of the approach and experiments take a look at our research paper: NER Models Using Pre-training and Transfer Learning for Healthcare.



Find more content about
NLP (2) Data Models (1) Healthcare Analytics (1) Healthcare Data (1) NER Tool (1) Transfer Learning (1)











