
It has been three years since we (the architect community at Persistent), published a series of blogs detailing our views on Data Lakes – these blogs covered the why, the what and the how of the subject. As someone who takes a lot of interviews for my organization, I get to have a lot of conversations with candidates who mention that they use Data Lakes as platforms to develop their analytics app or reports. This makes me believe that we are at a point where Data Lake adoption is at record highs. But another interesting point to note is that we still get more and more inquiries regarding our expertise in building data lakes. The good news for all the organizations who are on the verge of starting their data lake journey is that they can simply learn from the vast experience of others, skip several generations of Data Lake architecture & tech and directly jump to where the world is heading – building Data Lakes in the Cloud.
But why focus on building Data Lakes in the Cloud? Glad you asked!
Here are a few news stories that validate my claim that people are increasingly looking at cloud to building their data lakes.
- In the recently concluded re:Invent event, CEO of AWS, Andy Jassy mentioned that there are more than 10,000 data lakes on S3.
- In Nov 2017, Symantec announced that they are building data lake on AWS.
- Intuit and Thermofisher have also made similar announcements around the building and offering Data Platforms/Lakes in the cloud within the past few months.
Another commonly asked question is, why choose AWS for building Data Lakes?
There are several driving factors that make AWS a popular choice for building Data Lakes and the best way to validate this point is through this visual aid.
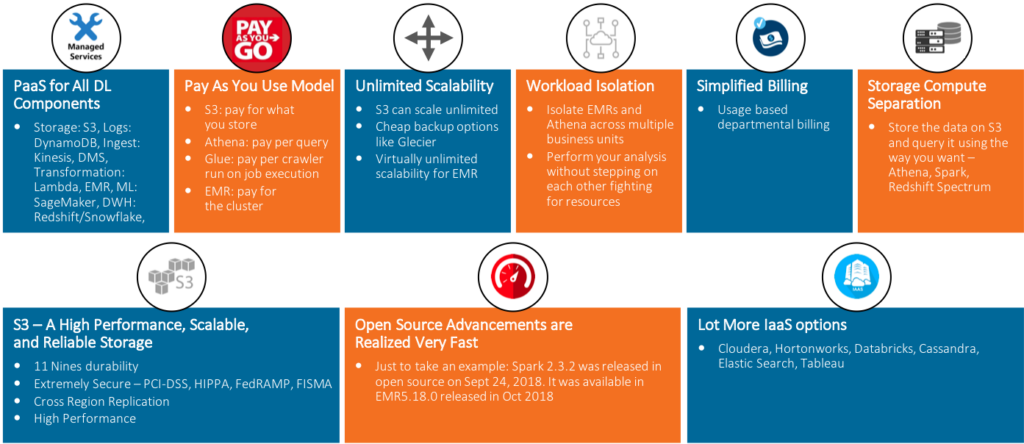
I hope this quick background on using cloud to build Data Lakes by using AWS has piqued your interest. Stay tuned for a series of blogs that will detail the process step by step. We will be covering Data Lake Reference Architecture and the AWS technology overlay on it and then talk about some of the most common use cases in Data Lake along with processes to solve them with AWS technologies – we call these the AWS Design Patterns. The finale of this series will be a blog covering typical questions that arise during the process and answers by experts – kind of like an FAQ to end the series on a problem-solving mode.
Finally, expect a complete antidote from me very soon on this topic – let me give a quick glimpse of what’s going in my mind. As someone who has been involved in Data Lake projects for the last 4 years, I have realized that one of the biggest selling points of the Data Lake concept is its ability to consume data in different ways – SQL, BI, Scripting, Machine Learning and more. But any guesses how most of the real users consume data? Its SQL; whether it is Hive, Impala, Spark (SparkSQL), Anthena or through any BI tool which indirectly means SQL, it is clear that Data Lake technologies are happily embracing SQL. Parallelly, modern Data Warehouses like Snowflake are embracing all the cool things that Data Lake brought – storage compute separation, pay as you go, immense scalability, semi-structured data support etc.
The big question is – can the modern cloud DWH become a good technology option for implementing Data Lake and DWH in a box? Do leave your comments and help shape my thoughts (and the next blog) on this topic.



Find more content about
Cloud (12) Cloud Technologies (4) Data Lake (7) AWS cloud (5) Amazon cloud (4) modern Data Warehouses (4)











