
Co-authored by Aditya Thatte, Project Lead, OpenStack
Since the inception of OpenStack, teams across the world, both in Industry and academia are heavily involved in evolving the platform to make it highly robust and usable. Being early adopters of OpenStack, our team has explored and engineered several solutions, products and customizations around OpenStack. In this article, we will share an overview of our journey into the OpenStack world, by explaining some of the solutions we have engineered around it. This article should be useful for anyone wanting to learn more about OpenStack, especially if planning to move to cloud solutions. Readers will learn diverse ways OpenStack can be deployed beyond the single node setup and integrated with other systems.
The ‘All-in-one’ single node setup
The classic ‘all-in-one’ setup is all about slicing and sharing a single compute node between users and applications of a specified group. This setup is widely used to manage a self-contained dev-test virtual environment running stand-alone workloads. We have experimented with various versions of ‘all-in-one’ setups, ranging from a manual installation of all the services to using Redhat’s RDO setup.
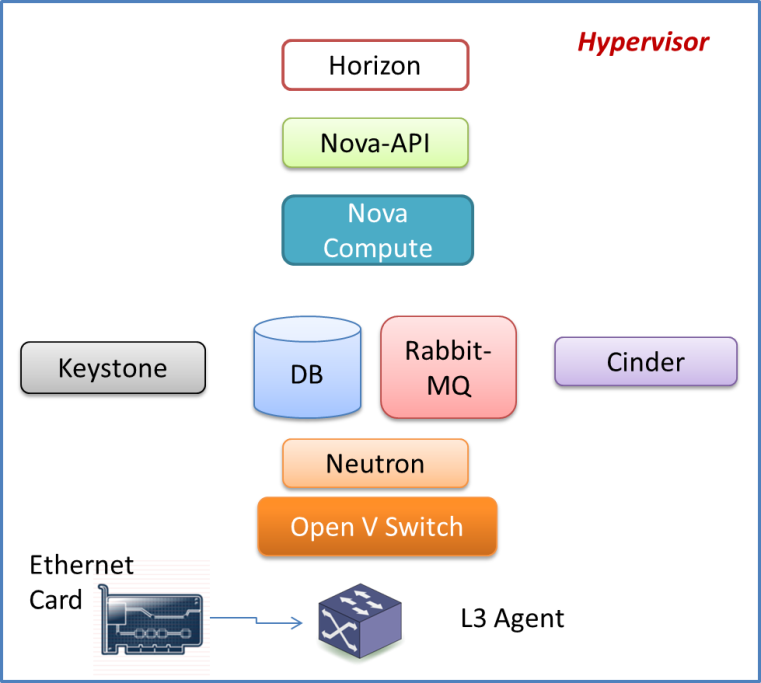
The above figure shows our standard ‘all-in-one’ setup, that is used for all the experiments. Neutron is deployed in a standard setup on account of its flexibility and trivial capability to isolate networks between the hosted services. On the storage side, the ‘glance’ and ‘cinder’ services leverage the ephemeral storage (instance hard disks) which is setup in Raid 2 configuration.
Private Cloud Deployments for Small & Medium Enterprises (SME)
The single node setup for stand-alone applications can be deployed on a relatively low powered hardware, as opposed to deploying a virtual infrastructure required to support scalable applications. In this light, we leveraged powerful hardware and deployed Openstack in a distributed (multi-node) setup.
The network was setup with a linux bridge driver using IP tables for network services, and Keystone was introduced later into the solution.

The Nova Controller is designed to be highly available on a shared storage. The OpenStack storage services are hosted on a different node to avoid a single point of failure. Glance, Cinder and Swift are installed on a Storage Area Network (SAN) having approximately 48 disks and a Linux head. These services are made available to users over a dashboard, while the Cinder storage services for all the virtual machines (VMs) are spun up using a compute rack. The front-end dashboard of the cloud management platform is developed using the Django framework (Horizon was in the early development stage) and is integrated with the corporate LDAP network for authorization and administration.
To create VMs in geographically distributed locations, the OpenStack services are setup (replicated) at individual sites.However the Keystone component is common across these sites.
Public & Hybrid Cloud
The next logical step was to explore the deployment of a public cloud to deliver infrastructure services over the internet. We collaborated with our customer to setup an OpenStack based cloud service. One of the key requirements of this setup was to ensure the cloud stack was conformed to a reference architecture, encapsulating the standard Operation Support Systems (OSS) and Business Support Systems (BSS) components. Users consumed the services via a dashboard and integrated API services, while developers leveraged the SDK for Python and Java.
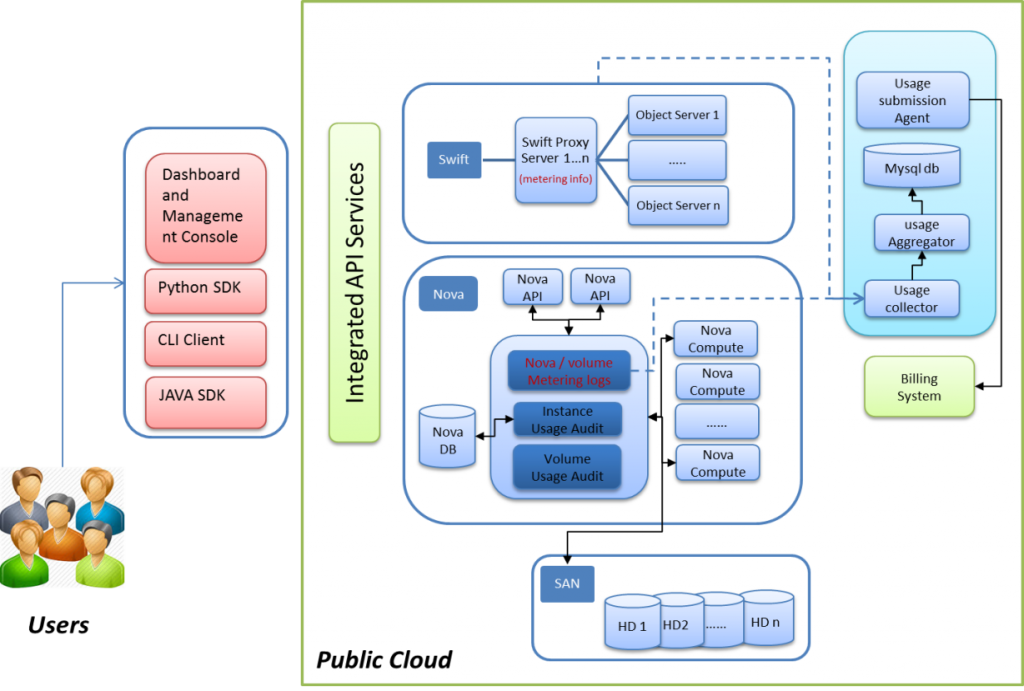
Many customizations were done on OpenStack to offer the cloud services based on the customers’ exact requirements, customized network access control rules, billing and SLA management solutions, etc.
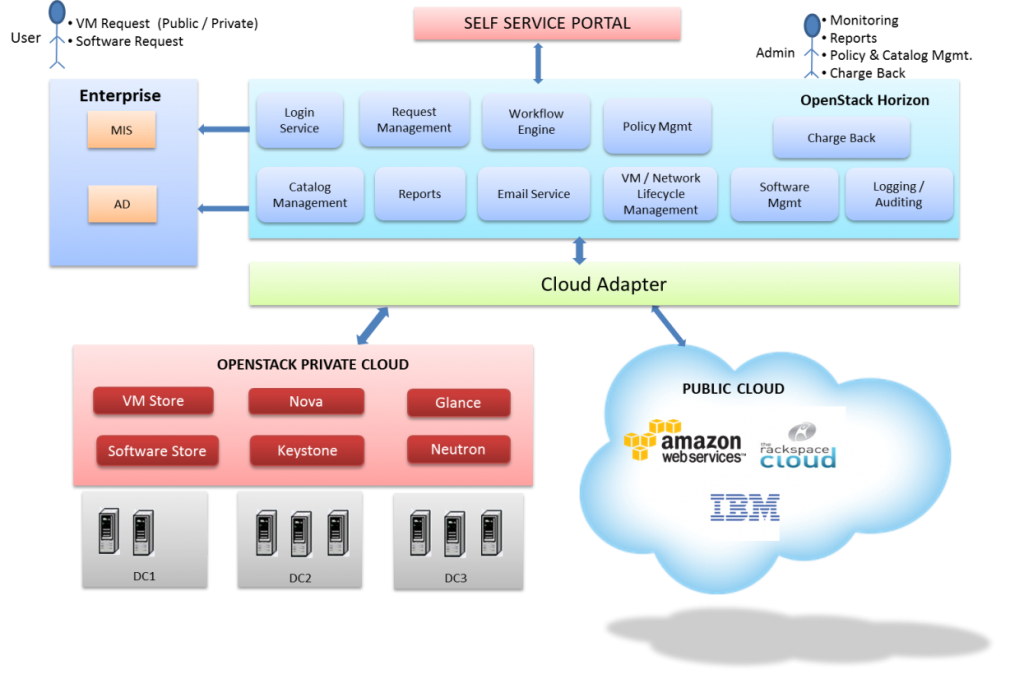
We have also implemented the notion of a hybrid cloud model by integrating an on-premise OpenStack based private cloud with heterogenous public clouds, using a federated cloud framework (aka cloud broker). The diagram shown below depicts the use of the jCloud adapter used to orchestrate between a private and public cloud environment(s).
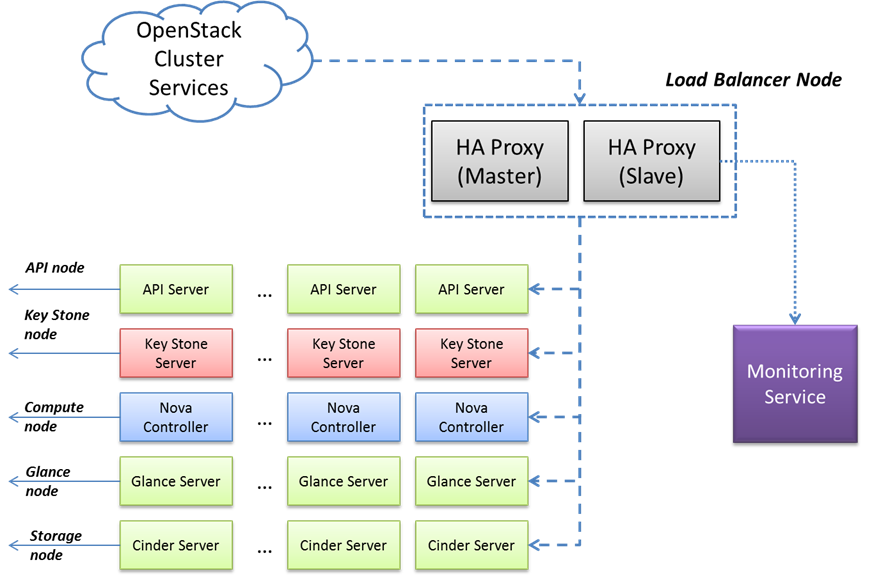
High Availability of OpenStack Services
High Availability (HA) forms the basis of any robust and reliable solution, and as such, we have implemented mechanisms to make the database service and Openstack services highly available.
Database HA
- HA for database and Rabbit MQ has been setup using Pacemaker, which relies on the Corosync messaging layer for reliable cluster communication. Corosync implements the Totem single-ring ordering and membership protocol, providing UDP and InfiniBand based messaging, quorum, and cluster membership to Pacemaker.
- The Pacemaker layer interacts with the applications through Resource Agents (RAs), and can use native and third party RAs. We used native Pacemaker RAs (such as those managing MySQL databases or virtual IP addresses), and existing third-party RAs (for RabbitMQ).
- We installed Corosync for messaging and DRBD for synchronous replication on top of Pacemaker. This setup has certain limitations, however we addressed it using the rate-limiting feature of OpenStack. The MySQL service on the top of this layer ensures high availability as per the requirement.
OpenStack Services HA
We used HA-Proxy to provide scalability of each service as a virtual machine. We have also developed an adapter to scale up/scale down the services whenever required. This aims to solve two problems, viz. Auto-scaling and High Availability.
In addition to the above-mentioned solutions, we have also setup application-specific OpenStack environments, such as media servers, DbaaS and virtual desktops, which have been deployed in our own labs and for several of our customers.














