
There are three basic approaches to AI : case-based, rule-based, and connectionist reasoning
– Marvin Minsky
These are the words of the world-renowned Artificial Intelligence (AI ) researcher who has seen beyond our times and set a path for many AI systems that currently exist. Majority of the research and development in general machine learning and AI until today has been circling around the case-based and rule-based approaches. The “connectionist reasoning” approach provides an opportunity to define and visualize data in a completely different manner providing new and serendipitous insights. Knowledge representation is one of the key components of Artificial Intelligence which materializes the approach of connectionist reasoning. It defines how knowledge and reasoning is to be represented in intelligent systems by providing reasoning through connections.
Knowledge from Language
With humans, knowledge within the brain is communicated to the outside world through the mode of language. Language, in general, expresses the connections between different (knowledge) entities. The searches we run on Google and Wikipedia are very good examples of knowledge systems expressed through language. While knowledge is best communicated through language, it is a complicated task to mimic the same in computer science using language. Natural Language Processing (NLP) is a hard topic in AI which has various challenges. Here’s a graphical representation of extracting knowledge from text data and placing it in a knowledge system.
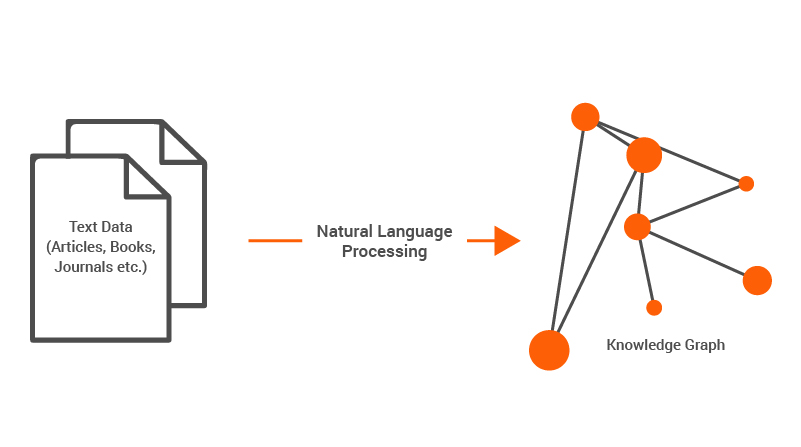
Language is built on three principles: syntactics, semantics and pragmatics, all which are essential to express and communicate knowledge. To completely represent a piece of knowledge through language, all three components are necessary and are generally difficult to capture effectively through modern NLP methods. A graph with nodes and edges is the best method to represent knowledge through language. This is because every piece of knowledge has entities and each entity is related to another in some fashion. The “connections” between the different entities hold key information on the knowledge that is being represented. Consider the following piece of text.
“Harry was frying eggs by the time Dudley arrived in the kitchen with his mother. Dudley looked a lot like Uncle Vernon. He had a large pink face, not much neck, small, watery blue eyes, and thick blond hair that lay smoothly on his thick, fat head. Aunt Petunia often said that Dudley looked like a baby angel — Harry often said that Dudley looked like a pig in a wig.”
In this piece of text, there are multiple entities and relations which hold information on the different entities. From the text we know that Harry, Dudley, Petunia and Vernon are related. We could draw a graph of the entity connections as shown in Figure 3.
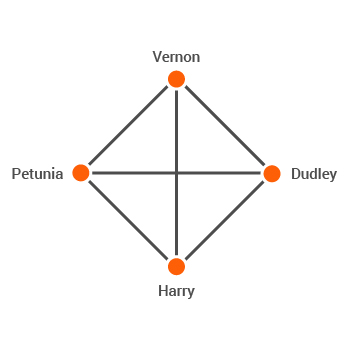
As a human, it is easy to draw connections using a graph because we can infer the entities and deduce the relationships. How would we do this in an automated fashion using NLP methods?
The NLP Pipeline
The first step is to find all the entities within the text. In this text, there are different entities both people and objects. For now, let’s consider only people-based entities. This is how a Named Entity Recognition (NER) method would find the entities in the given text.
With this piece of information, it is possible to generate the graph nodes. But how would the nodes relate to each other. This is the trickiest part of generating such a graph that represent facts (knowledge). Naively, one could simply draw a connection between entities if they are mentioned together in a single sentence. But this does not always imply that there is a physical connection between two or more entities. There are two ways to represent relationships in such instances.
(1) A physical relationship is explicitly mentioned within the sentence.
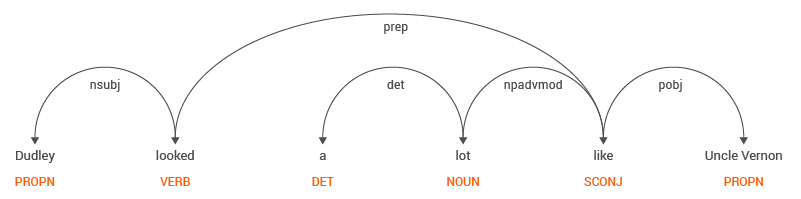
In this case, the solution is generally trivial. The solution is to look at the structure of the sentence and extract relations. For example, consider the sentence “Dudley looked a lot like Uncle Vernon”. Figure 2. shows the Dependency Structure and Parts of Speech (POS) in the sentence.
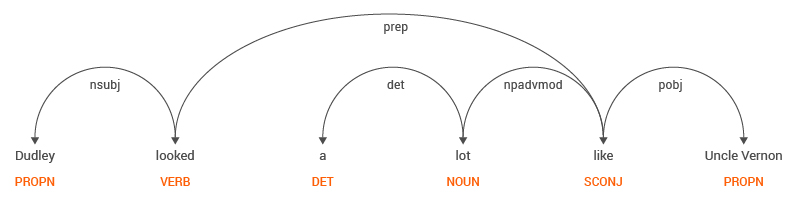
By linguistic definition, a relationship can be found between two entities that are proper nouns (PROPN), one which is a subject (nsubj) and the other being an object (pobj), connected by a preposition (prep) which is the actual “relation”. If we were to apply this rule to the POS tags in the sentence, the relation extracted would be,
Dudley → looked like → Uncle Vernon
(Subject) – (Preposition) – (Object)
Here the relation in the sentence is that “Dudley looked like Uncle Vernon”. This is a relation mentioned explicitly in the sentence.
The mentioned rule-based approach fails where the sentences are much more complex, and the parsing structure has more interconnected dependencies. In such cases another approach is to use “Information Extraction” and “Relation Extraction” methods provided by tools like CoreNLP and Stanford NLP to extract relations. These methods also follow similar principles mentioned previously. But they also have limited accuracy when it comes to complex sentences.
(2) A relation is not mentioned in the sentence but generally understood from the passage itself.
In the sample text, there are three important relations that are not explicitly mentioned in the passage. Even though not expressed linguistically it may be generally understood by any human readers. From the passage, it is understood that (a) Petunia is Harry’s aunt, (b) Vernon is Harry’s uncle and (c) Dudley is the son of Petunia and Vernon. Nowhere in the passage are these relations explicitly mentioned but this is implied from the words used in different sentences. These relations which are generally important for knowledge representation are quite difficult to capture. This requires more of a layered and complicated NLP pipeline to capture the relations after constructing different ontologies of relations present in the text. The challenges will involve normalizing and resolving entities within a passage, co-referencing entities, and finally extracting relations from simplified sentences. Constructing the ontology of relations itself involves linguistic challenges.
Probabilistic methods can also be employed to infer such relations that are not explicitly mentioned but inferred through multiple relations and facts. The formulation can be expressed in a Bayesian fashion as follows.
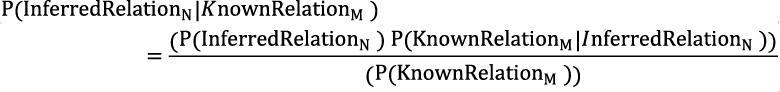
The generalized principle of the probabilistic method is that new relations are “inferred” from “known” relations. This probabilistic method can be applied after generating a graph of the entity relations’ tuples and applying graph analysis methods. This, in turn, is a part of “knowledge generation” within knowledge graphs.
Finding relations between entities is the real juice of representing knowledge in a graph. The challenges in terms of linguistics are extreme when it comes to extracting meaningful relations between entities out of the text. It is not just the structural complexity of the text but also the style of writing that affects the entire NLP pipeline which generates graphs from text.
Resolving Entities
The text analytics challenge does not end with identifying the relations. Another major issue is Entity Resolution. For example, an entity referred to as “Harry” in the middle of a chapter is referred to as “Harry Potter” in the beginning of the same chapter. Recognizing that both are the same entity across passages and even chapters or even other books while generating the knowledge graph is very challenging. If we were to consider entities extracted from heterogeneous text sources, the difficulty compounds because of the nature of the entities mentioned. For example, Saddam Hussein might be alluded to as “Saddam Hussein” in a news article and “Saddam Hussein Abd al-Majid al-Tikriti” in Wikipedia. Tracing and relating these two names to the same person is non-trivial. Similarly, it is possible for two separate entities to have the exact same name. Knowing how to deal with such an instance is also crucial in generating a reliable knowledge graph.
Conclusion
The general accuracy of a knowledge graph depends on the cumulative accuracy of each component in an NLP pipeline which begins with entity extraction and ends with the extraction of the relation. Therefore, the reliability of the generated knowledge graph is directly proportional to the reliability of the NLP methods. Apart from the facts extracted from the text, there are facts that are not mentioned in the text. Adding such information from multiple and heterogeneous sources should be considered. This challenge of merging information extracted from multiple structured as well as unstructured sources is a pain point in the area of knowledge systems and requires extremely sophisticated text processing methods.
In summary, generating knowledge graphs from textual data is a challenging process. It requires a complicated inventory of NLP methods to reliably and accurately extract entity information, relationship information, and concise facts. Moreover, merging textual information from heterogeneous sources to represent knowledge is complex in terms of both scale and volume.














