
IBM® Datacap’s ability to capture, recognize and classify a wide variety of unstructured document types—and more importantly, identify and extract the important information within those documents—has earned it “market leader” status in Gartner’s Enterprise Content Management (ECM) category.
But can recent advances in machine learning allow 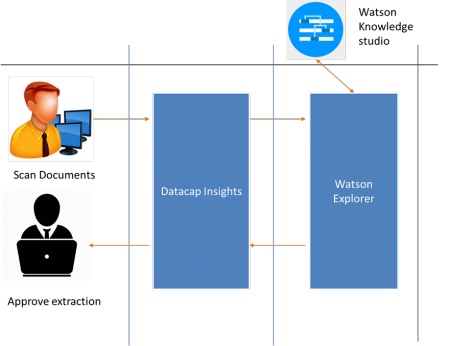 IBM Datacap users to extract even more value from their investment in the platform? We believe so.
IBM Datacap users to extract even more value from their investment in the platform? We believe so.
I’d like to share one way that Persistent Systems has been using machine learning to enhance Datacap and improving the confidence and value of the data it captures.
Integrating machine learning through IBM Watson Explorer
IBM Watson Explorer (WEX) is a cognitive search and content analysis platform that enables organizations to gain insights from their data, including a wide variety of structured, unstructured, internal, external and public content.
Watson’s cognitive horsepower and ability to correlate content from disparate sources and formats should complement Datacap’s ability to capture and structure a large volume of documents—if the two platforms can be successfully integrated.
To accomplish this, our Watson engineers used Watson Knowledge Studio (WKS), a cloud-based application that allows developers to create custom annotator components able to recognize and call out specific mentions and relationships in the unstructured data stream.
Once the annotator model is developed and trained, it can be easily imported into Watson Explorer Content Analytics to make those results easily searchable or Watson Explorer Annotation Administration Console to deliver deep insights back to the organization.
Unlocking the full power of Datacap insight
Combining the capture and recognition functions of Datacap with the machine learning capabilities of Watson can deliver unprecedented levels of value, automation and acceleration.
Your organization would be able to automatically process incoming documents, regardless of their structure, formatting, scan layout or possibly even language. Using IBM Watson text analytics and language processing tools, you’ll be able to identify and extract important legal entities in the document, including person, place and role information like “Joan,” “manager,” “Main Street” and “branch.”
With the annotation models in place, Watson can search for and identify specific industry terms and return keyword-value pairs like “Account Number” and “12345.” It can also gauge the document’s overall sentiment—positive, negative and to what degree—and classify the authors as “rude,” “ignored” etc., assigning specific actions based on your own business rules.
A healthcare example
For a health insurance company, the ability to automatically process invoices generated by different hospitals would be of great benefit, driving increased efficiency and effectiveness. Datacap gives the insurance company the ability to process a variety of invoices printed in different formats by different hospitals, including different paper sizes and document orientations.
At that point Watson could take over, extracting the important legal entities and structuring the results consistently, despite the infinite variety of terms used on a hospital’s invoice. All of this happens automatically, without human intervention.
This exact solution is currently being tested on a group of hospitals to ensure the accuracy and completeness of data and help increase the user’s confidence in the data extraction process, minimizing the needs for future manual intervention.
IBM Datacap has been helping large, complex organizations manage their immense volume of inbound documents for years. Now, with the help of IBM Watson, those same organizations will be able to analyze and identify the crucial information and relationships those same organizations need to achieve breakthrough efficiency and effectiveness, optimizing their processes and transforming their businesses.














