
Our experience of installing, configuring and maintaining hundreds of Big Data setups over the last few years has made the importance of and ability to perform multiple tasks really clear. Though it’s part of process, it’s painful when you do it manually.
As a Big Ops (Bigdata devops) engineer or big data developer, you might have experienced the pain and time involved in installing various Hadoop distributions and in the various tasks highlighted in figure 1.
Good news, we have automated these processes. In this blog I will throw some light on how we have achieved it for Hadoop distributions like Hortonworks, Cloudera and BigInsights on any number of nodes. We support most commonly used Linux flavors like: Ubuntu 14, CentOS 6, CentOS 7, RedHat 6, RedHat 7 and it’s prerequisites on the listed OS.
Since we have used Ansible for deployment automation, let me give you a little information about it and why we have used Ansible over chef or puppet.
Ansible is an easy to use Configuration Management, Application Deployment, Orchestration and Provisioning Infrastructure tool. The advantages of using Ansible are: dead-simple syntax (YAML), small learning curve, written in python, agentless, secure – uses ssh, free and opensource. It is easy to create customized modules as per requirements.
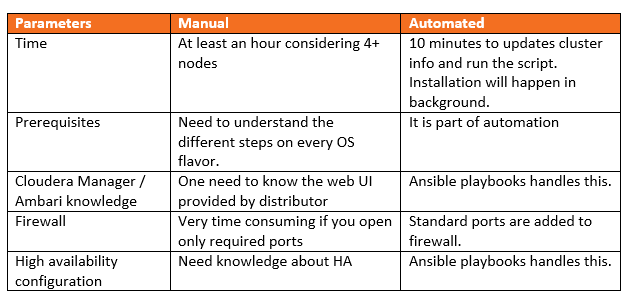
Here is the comparison between a manual installation and configuration vs automated installation and configuration:
Apart from above mentioned advantages, there are many more as below:
- The biggest advantage is that the user just needs to define Hadoop distribution as a variable. The user doesn’t need to know specifics of Cloudera, Hortonworks or BigInsights deployment information.
- Single hosts file for all Hadoop distribution.
- No upper limit on number of nodes.
- Single command will deploy entire cluster once couple of files are updated with hosts and other info.
- Playbooks allows users to select custom repositories. This helps to select local repositories, saving considerable amount of network bandwidth and time.
- One can fine tune parameters, which are supported by blueprints for HDP and BI / Cloudera API for Cloudera.
- Easy to add custom deployment scripts to existing playbooks if you need to install additional software.
- One can easily tweak Simple Ansible playbooks if they have some specific requirement.
- Can be used for on premise or cloud deployments.
Overall Flow:
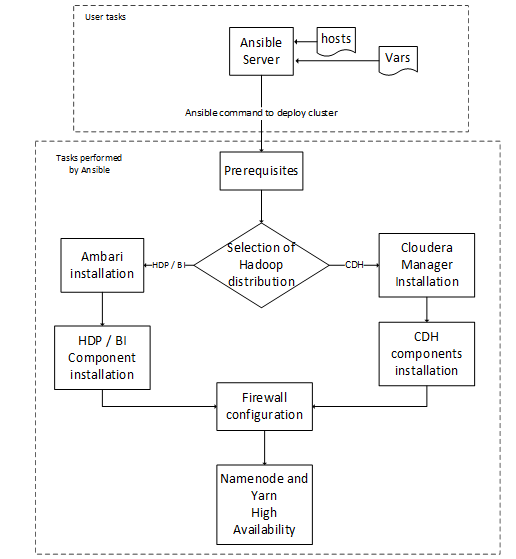
We have made this Ansible Playbook available @ https://github.com/persistentsystems/.
This helped us a lot. Since misery loves company, if you have experienced some of the same pain, do reach out to me @ nilesh_njoshi@persistent.co.in and I would be happy to guide you on this.



Find more content about
Big Data (18) Hadoop (1) BigINsights (1) Ansible (1) Big Ops (1) BigData DevOps (1) Cloudera (1) Hortonworks (1)











