
In a previous blog, Avadhoot Agasti discussed how data lakes can eliminate the impedance mismatches between data producers for control and data consumers for flexibility, or data silos. This approach also results in increased information use and supports many different types of use cases, while cutting server hardware and license cost due to silos.
While implementing any kind of data platform, the very first task revolves around extracting data from a variety of sources, not just a single data source as initially proposed in the data lake concept. The data ingestion layer in the data lake must be highly available and flexible enough to process data from any current and future data sources of any patterns (structured or un-structured) and any frequency (batch or incremental, including real-time) without compromising performance. This calls for building flexible data ingestion frameworks to ensure overall quality and success of ingestion process. In this particular blog, I’ll discuss how creating the flexible data lake ingestion framework has an impact on the data lake platform.
A Flexible Data Lake Ingestion Framework
To build a flexible data lake ingestion framework, we need to understand data patterns, which are indicated by key parameters as shown in the diagram below:
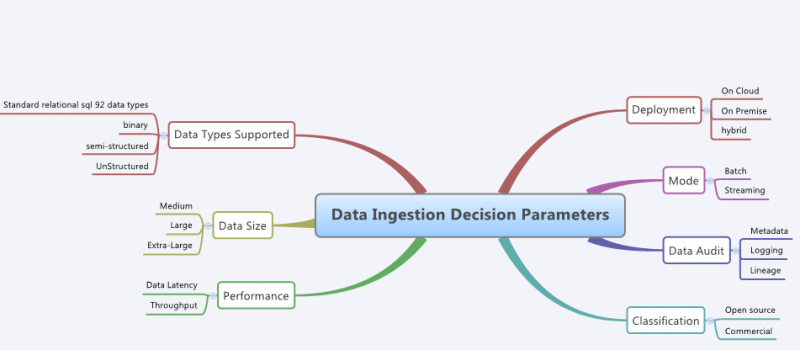
ETL/data lake architects must be aware that designing a successful data ingestion framework is a critical task, requiring a comprehensive understanding of the technical requirements and business decision to fully customize and integrate the framework for the enterprise-specific needs.
Pivotal questions must be asked to business stakeholders before navigating to the ingestion setup. Here are the key questions:
- What are the disparate data sources under consideration (Network Logs, CRM data, Billing, Social data)? Where are they located (on premise, in the cloud)?
- What are the input message types – structured, un-structured or semi-structured? What is the priority among them to ingest from a business perspective?
- Are there specific network protocols required to collect data from these input data sources (e.g. SNMP, EMS, CMIP, SGMP, TSR, and SIP)?
- Does the data source make the data available easily or a connector needs to be built?
- Does your organization need a unified view of the ingestion pipeline?
- What are the critical performance indicators (e.g. volume, throughput, velocity) that are expected?
- Do you need to capture metadata during ingestion?
- Do you need to be able to perform real-time analysis on source data?
- Does your organization want flexible deployment options – on cloud, on Premise or hybrid?
Based on the answers, choose the right tools for your framework. Consider following key features while choosing the right tools:
- Ability to handle high-frequency of incoming or streaming data
- Ability to ingest data from RDBMS, log files (semi-structured) or text/documents (unstructured).
- Ability to visually create data collection flows using various inbuilt processors pulling raw data from disparate sources and routes all of the data to data lake.
- Ability to ingest in Bulk mode
- Ability to ingest data from anywhere (on premise, a private cloud or a public cloud)
- Ability to detect change data capture from the data sources needed by the business.
- Monitor ingestion from a single central console.
- Ability to create descriptive metadata during data onboarding. The data pipeline should support automated metadata extraction, capture and tagging facility.
Key challenges and solutions to bring new data sources in Data Lake
With a data lake implementation collecting data from disparate sources, complexity arises with the variety of ingestion tools (at times one for each data source). Hence, it is very important that the ingestion framework should support tools/connectors for extracting and loading large volume of data onto the data lake through simple and unified interface. Consider tools such as Hortonworks Data Flow which is powered by Apache Ni-Fi, Kafka and Storm. It not only provides a user interface to view the data collection pipeline, but the ability to collect data from dynamic, disparate and distributed sources. In the commercial world, you can also consider tools from vendors like Informatica, Sycnsort, Talend and Pentaho.
Since we need a continuous flow into data lake, it requires that we not only keep pouring new data sets but also get the incremental data through appropriate change data capture (CDC) process as driven by the needs of the business. These may be incremental, pull-based refreshes, or continuous, near-real time push-mode streams of new and changed data. In the former case, for identifying changes in data between yesterday and today, we need to ensure we have mechanisms in place to identify change data based on timestamps or cluster of keys. Tools like Oracle Golden Gate, Gobblin (LinkedIn) , Attunity, Shareplex, SAP Replication Server provide a real time CDC capability.
Since a data lake is collecting data from several business and non-business sources, without extracting descriptive metadata, there is a risk that the data lake will become an unproductive data swamp. The ingestion framework should have a metadata management capability to provide descriptive metadata such as source provenance and onboarding timestamp automatically.
While bringing in new data sources, make sure to revisit capacity planning, support of current and future sources through existing ingestion tools, as well as the required latency to bring incremental changes to the data lake. It’s equally important for the data custodian that data flows securely through the ingestion layer as described by colleague Akshay Bogawat in his blog.
Conclusion
Overall, there’s a tendency for organizations to not plan and evaluate various options for the ingestion layer. In this blog, I have tried to cover challenges and highlighted the importance of planning ahead to build a robust, flexible and effective data ingestion framework based on business requirement to support heterogeneous data sources. What do you think?
Image Credits: www.sfgate.com



Find more content about
Unstructured Data (1) Data Ingestion (4) Datalake (3) Data Sources (1) Structured Data (1)











