
The rapid technical progress and widespread adoption of artificial intelligence (AI)-based products and workflows are influencing many aspects of human and business activities across banking, healthcare, advertising and many more industries. Although the accuracy of AI models is undoubtedly the most important factor to consider while deploying AI-based products, there is an urgent need to understand how AI can be designed to operate responsibly.
Responsible AI is a framework that any organization developing software needs to adopt to build customer trust in the transparency, accountability, fairness and security of any deployed AI solutions. At the same time, a key aspect to make AI responsible is to have a development pipeline that can promote the reproducibility of results and manage the lineage of data and ML models.
Low-code machine learning is gaining popularity with tools like PyCaret, H2O.ai and DataRobot, allowing data scientists to run pre-canned patterns for feature engineering, data cleansing, model development and statistical performance comparison. However, often the missing pieces of these packages are patterns around responsible AI that evaluates ML models for fairness, transparency, explainability, causality and more.
Here, we demonstrate a quick and easy way to integrate PyCaret with Microsoft RAI (Responsible AI) framework to generate a detailed report showing error analysis, explainability, causality and counterfactuals. The first part is a code walkthrough for developers to show how an RAI dashboard can be built. The second part is a detailed evaluation of the RAI report.
Code walkthrough
First, we install the libraries needed. This can be done on your local machine with Python 3.6+ or on a SaaS platform like Google Colab.
!pip install raiwidgets
!pip install pycaret
!pip install — upgrade pandas
!pip install — upgrade numpy
Pandas and Numpy upgrade is needed for now but should be fixed shortly. Also, don’t forget to restart runtime if you are installing in Google Colab.
Next, we load data from GitHub and cleanse the data and do feature engineering with PyCaret.
import pandas as pd, numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
csv_url = ‘https://raw.githubusercontent.com/sahutkarsh/loan-prediction-analytics-vidhya/master/train.csv'
dataset_v1 = pd.read_csv (csv_url)
dataset_v1 = dataset_v1.dropna()
from pycaret.classification import *
clf_setup = setup(data = dataset_v1, target = ‘Loan_Status’,
train_size=0.8, categorical_features=[‘Gender’, ‘Married’, ‘Education’,
‘Self_Employed’, ‘Property_Area’],
imputation_type=’simple’, categorical_imputation = ‘mode’, ignore_features=[‘Loan_ID’], fix_imbalance=True, silent=True, session_id=123)
The dataset is a simulated loan applications dataset with features like gender, marital status, employment, income, etc. of applicants. PyCaret has a cool feature to make the training and testing data frames available after feature engineering via get _config method. We use this to get cleansed features that we will later feed to RAI widget.
X_train = get_config(variable=”X_train”).reset_index().drop([‘index’], axis=1)
y_train = get_config(variable=”y_train”).reset_index().drop([‘index’], axis=1)[‘Loan_Status’]
X_test = get_config(variable=”X_test”).reset_index().drop([‘index’], axis=1)
y_test = get_config(variable=”y_test”).reset_index().drop([‘index’], axis=1)[‘Loan_Status’]
df_train = X_train.copy()
df_train[‘LABEL’] = y_train
df_test = X_test.copy()
df_test[‘LABEL’] = y_test
Now we run PyCaret to build multiple models and compare them on Recall as a statistical performance metric.
top5_results = compare_models(n_select=5, sort='Recall')
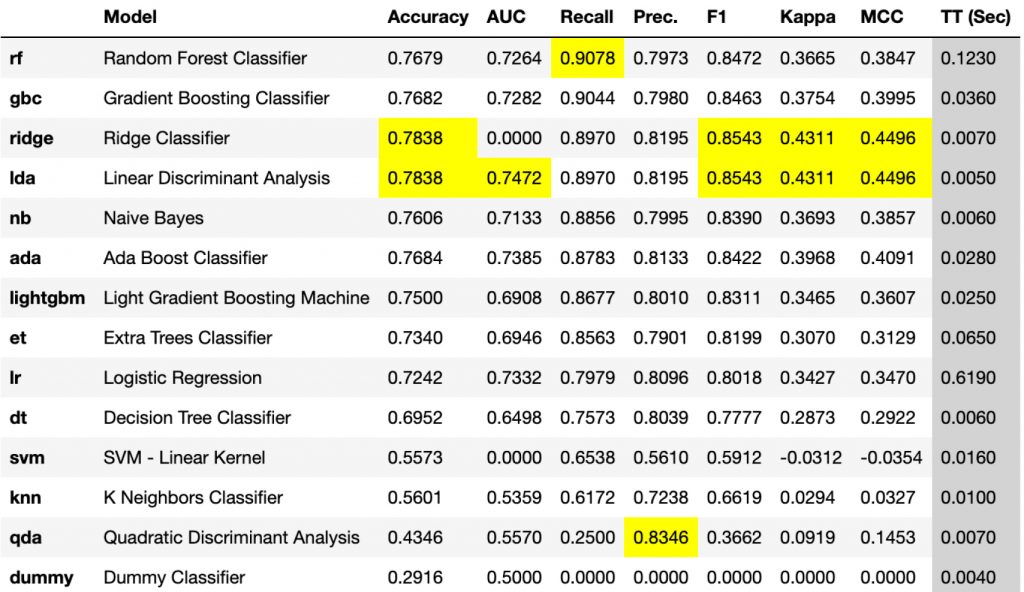
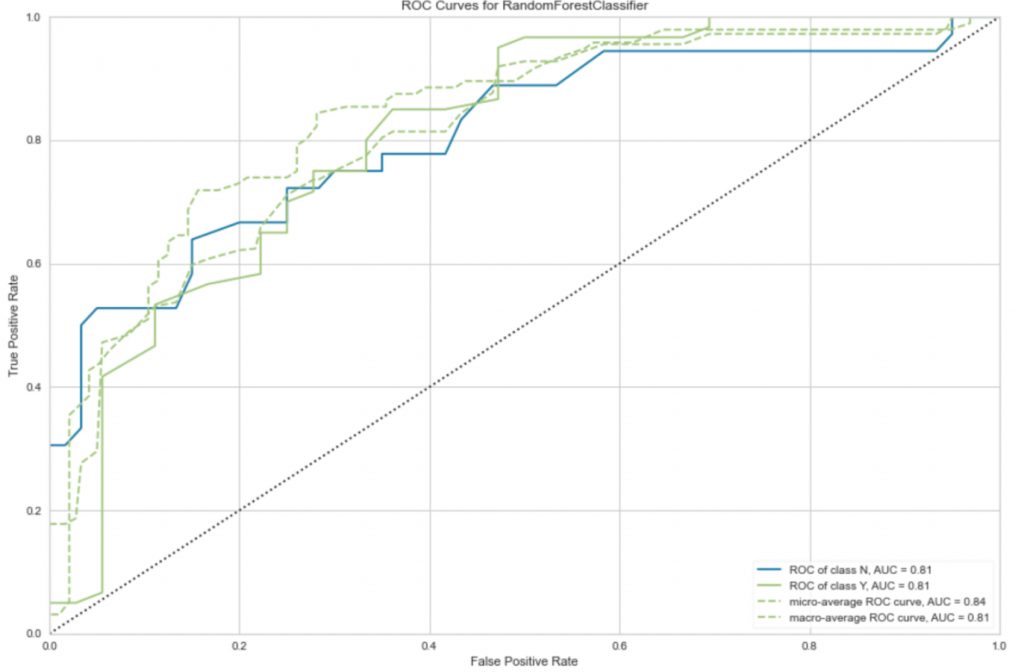
Our top model is a Random Forest Classifier with a Recall of 0.9, which we can plot here.
selected_model = top5_results[0] plot_model(selected_model)
Now, we will write our 10 lines of code to build a RAI dashboard using features data frames and models we generated from PyCaret.
cat_cols = [‘Gender_Male’, ‘Married_Yes’, ‘Dependents_0’, ‘Dependents_1’, ‘Dependents_2’, ‘Dependents_3+’, ‘Education_Not Graduate’, ‘Self_Employed_Yes’, ‘Credit_History_1.0’, ‘Property_Area_Rural’, ‘Property_Area_Semiurban’, ‘Property_Area_Urban’]
from raiwidgets import ResponsibleAIDashboard from responsibleai import RAIInsights rai_insights = RAIInsights(selected_model, df_train, df_test, ‘LABEL’, ‘classification’, categorical_features=cat_cols)
rai_insights.explainer.add()
rai_insights.error_analysis.add()
rai_insights.causal.add(treatment_features=[‘Credit_History_1.0’, ‘Married_Yes’])
rai_insights.counterfactual.add(total_CFs=10, desired_class=’opposite’)
rai_insights.compute()
The above code, though pretty minimalist, does a lot of things under the hood. It creates insights on RAI for classification and adds modules for explainability and error analysis. Then, a causal analysis is done based on two treatment features including credit history and marital status. Also, counterfactual analysis is done for 10 scenarios. Now, let’s generate the dashboard.
ResponsibleAIDashboard(rai_insights)
The above code will start the dashboard on a port like 5000. On a local machine, you could directly go to http://localhost:5000 and see the dashboard. On Google Colab, you need to do a simple trick to see this dashboard.
from google.colab.output import eval_js
print(eval_js(“google.colab.kernel.proxyPort(5000)”))
This will give you a URL to view the RAI dashboard. You can see some components of the RAI dashboard below. Here are some major results of this analysis that were generated automatically to complement the AutoML analysis done by PyCaret.
Results: Responsible AI Report
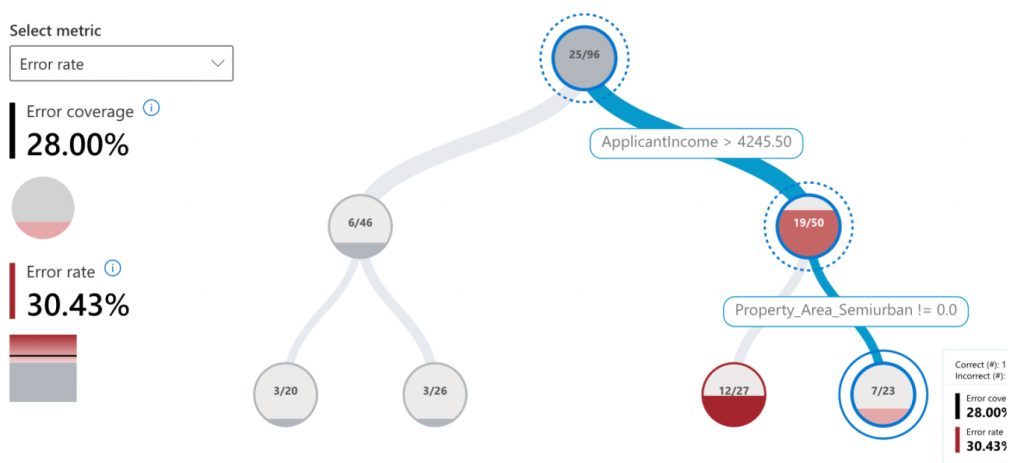
Error analysis: We see that the error rate is high for rural property areas and our model has a negative bias for this feature.
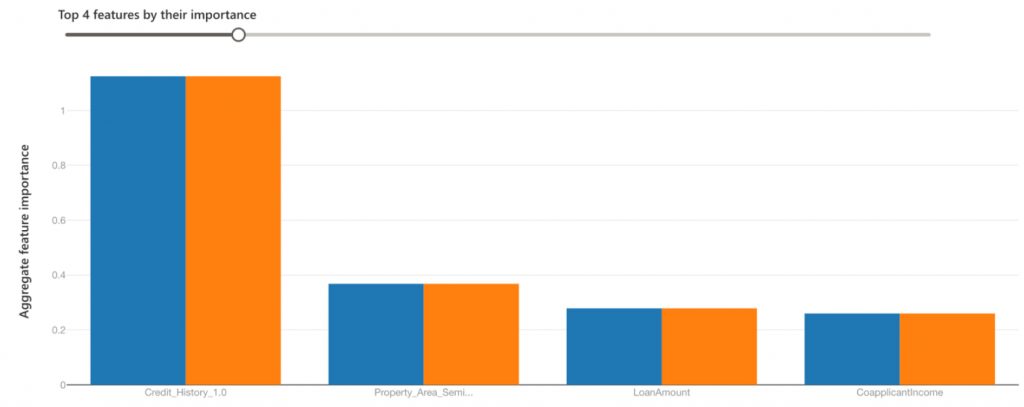
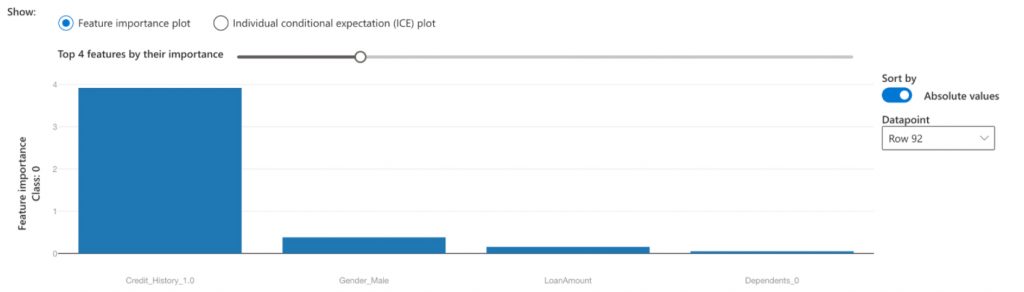
Global explainability – feature importance: We see that the feature importance remains the same across both cohorts — all data (blue) and property area rural (orange). We see for the orange cohort, the property area does have a bigger impact but still, credit history is the #1 factor.
Local explainability: We see that credit history is an important feature for an individual prediction also – row #20.
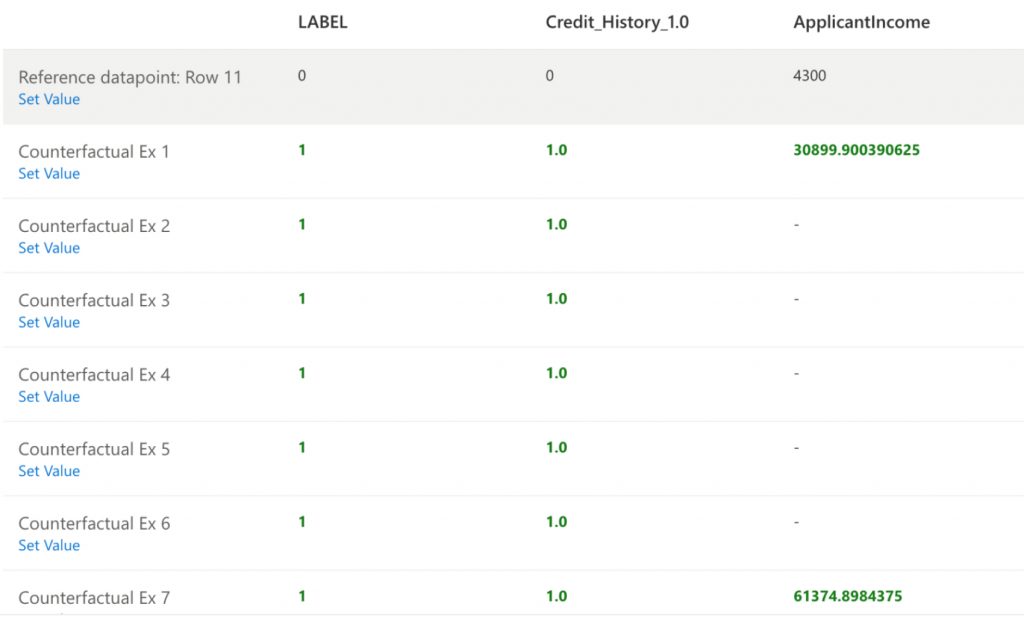
Counterfactual analysis: We see that for the same row #20 a decision from N to Y can be possible (based on data) if credit history and loan amount is changed.
Causal inference: We consider causal analysis to study the impact of two treatments, credit history and employment status, and see that credit history has a greater direct impact on approval.

responsible AI analysis report showing model error analysis, explainability, causal inference and counterfactuals can add great value to traditional statistical metrics of precision-recall that we usually use as levers to evaluate models. With modern tools like PyCaret and RAI dashboards, it’s easy to build these reports. These reports can be developed using other tools — the key is that data scientists need to evaluate models for these patterns on responsible AI to make sure their models are ethical along with being accurate.
Originally published at VentureBeat














