
Demonstrated Using Lending Club Data
In my previous blogs, I explained how the cloud data platform Snowflake can be used not only as a data warehouse but also as a data lake environment, as well as a platform for augmenting ELK stack. As we mature in the Snowflake journey, machine learning (ML) on top of data saved in Snowflake is obviously coming up as a strong common requirement.
Snowflake offers great connectivity to Apache Spark, Python, and Amazon SageMaker to execute ML workloads. However, all of these solutions involve spinning up another infrastructure or service to manage the compute workloads of ML. For Spark, we must spin the Amazon Elastic MapReduce EMR or Databricks cluster. For Python, we need to have Amazon Elastic Compute Cloud (Amazon EC2) running or subscribe to the SageMaker service.
Background
The machine learning lifecycle has two prominent steps:
- Model development and tuning: This is a complicated process which involves iterations of feature engineering, algorithm selection, configuration and accuracy measurement. The combination of Python Scikit-learn (SKlearn) and Jupyter provides the best experience to achieve this. The data scientists typically love these tools.
- Model re-engineering and deployment: All the ML libraries provide both train and predict capabilities. However, in most cases, the model needs to be re-engineered so that it can fit in the main ETL flow. There are many reasons for re-engineering, such as (a) managing a high volume of data (b) making model execution a part of ETL flow (c) performance considerations (d) minimizing management of external infrastructure and (e) ease of operations.
Generally, the following two approaches are used:
- Deploy model and expose RESTful API for predict. Then, the applications can call it in real-time, or ETL flow can call it in batch mode. AWS SageMaker supports this approach very effectively.
- Convert the model to Spark and execute it on the Spark/Hadoop/EMR cluster.
While both of these approaches work pretty well, they do attract management and cost overheads.
In Place ML in Snowflake
The idea here is to execute ML within Snowflake. Obviously, we are aiming at a “model re-engineering and deployment” step here since it affects the day-to-day operations. Model development and tuning is a one-time activity and best done with the tools preferred by your data scientist team. In this blog, we assume that Python Scikit-learn (SKlearn) is the mechanism to develop the model.
When we re-engineer the model, there are two important steps: Re-engineering of feature engineering and actual model code.
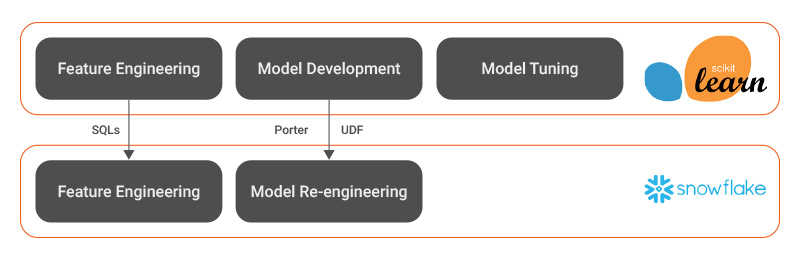
Snowflake provides all useful constructs for typical feature engineering tasks. Here are some samples:
Feature Engineering in Snowflake
| Feature Engineering Task | Snowflake Approach |
| Normalization | with aggregates as ( select min(loan_amnt) as min_loan_amnt, max(loan_amnt) as max_loan_amnt from loan_data) select (loan_amnt – min_loan_amnt)/ (max_loan_amnt – min_loan_amnt) as normalized_loan_amnt from loan_data, aggregates limit 5; |
| One-hot-encoding | select iff(grade=’A’,1,0) as grade_A, iff(grade=’B’,1,0) as grade_B, iff(grade=’C’,1,0) as grade_C from loan_data where grade in (‘A’, ‘B’, ‘C’); |
Models in Snowflake
We leverage Snowflake’s JavaScript UDFs for codifying models in Snowflake.
I am using an interesting Sklearn-Porter (https://github.com/nok/sklearn-porter) project. Using Porter, the SKlearn models can be converted to JavaScript.
This is very effective since:
- Model development and tuning process remain exactly the same.
- The model is then ported to JavaScript, converted to UDF and then all of the Snowflake power can be used to execute the model in a distributed manner.
- The data preparation and model execution can all be executed in SQL constructs of Snowflake.
Use Case
Dataset: Lending Club Data )
The raw data has 1.95M records and 145 columns.
ML Use Case:
Every loan has a purpose, such as involving a major purchase, small business, vacation, etc. In this dataset, there are about 121K records where the purpose is not defined (other). The idea is to train a classifier to predict the purpose for these 121K records.
Notebook:
The notebook (https://github.com/avadhoot-agasti/snowflake-demos/blob/master/ml_classifier_lending_club.ipynb) demonstrates:
- Feature engineering, model development and tuning in SKlearn.
- Porting of model to JavaScript using Porter.
- Decorating the generated JavaScript so that it can be converted to Snowflake UDF.
- Re-writing feature engineering to Snowflake SQL.
- Combining everything together to perform the classification directly using Snowflake queries.
Summary
This blog demonstrates the approach of executing the ML models in-place in Snowflake. This is an approach that helps us get the benefits of using Python SKlearn to develop the model and, utilizing the power of Snowflake, to execute it in mainline ETL code.



Find more content about
Machine Learning Lifecycle (1) ML in Snowflake (1) ML Use Case (1) Python SKlearn (1)











