
Before we delve deeper into the differences between processing JSON in Spark vs Snowflake, let’s understand the basics of Cloud Service/Framework.
In the Big Data world, Apache Spark is an open-source, scalable, massively parallel, in-memory execution, distributed cluster-computing framework which provides faster and easy-to-use analytics along with capabilities like Machine Learning, graph computation and stream processing using programming languages like Scala, R, Java and Python.
Spark Architecture
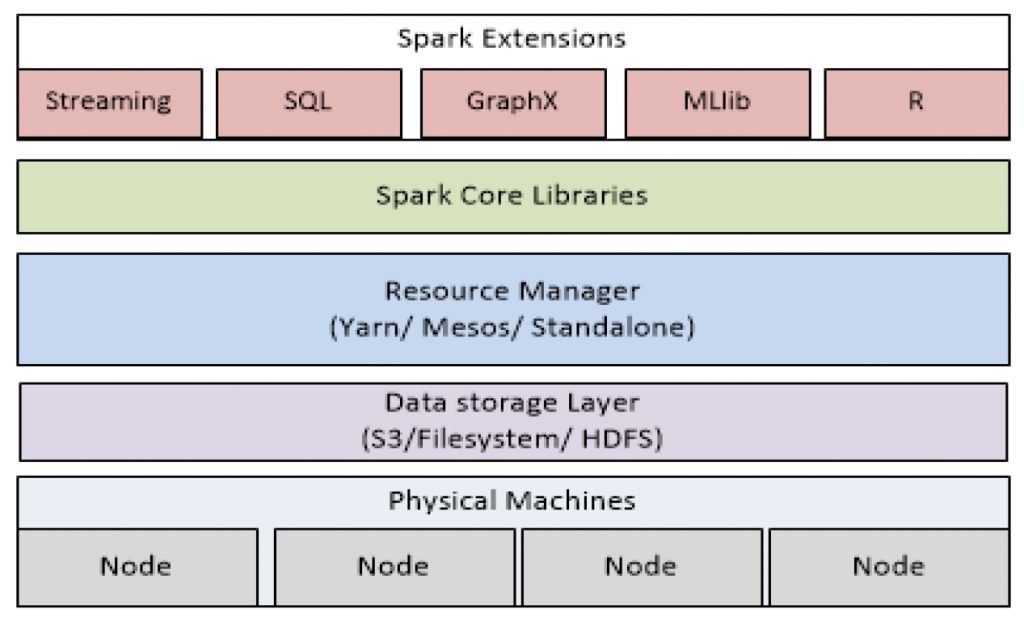
On the other hand, Snowflake is a data warehouse that uses a new SQL database engine with a unique architecture designed for the cloud such as AWS and Microsoft Azure.
Snowflake Architecture
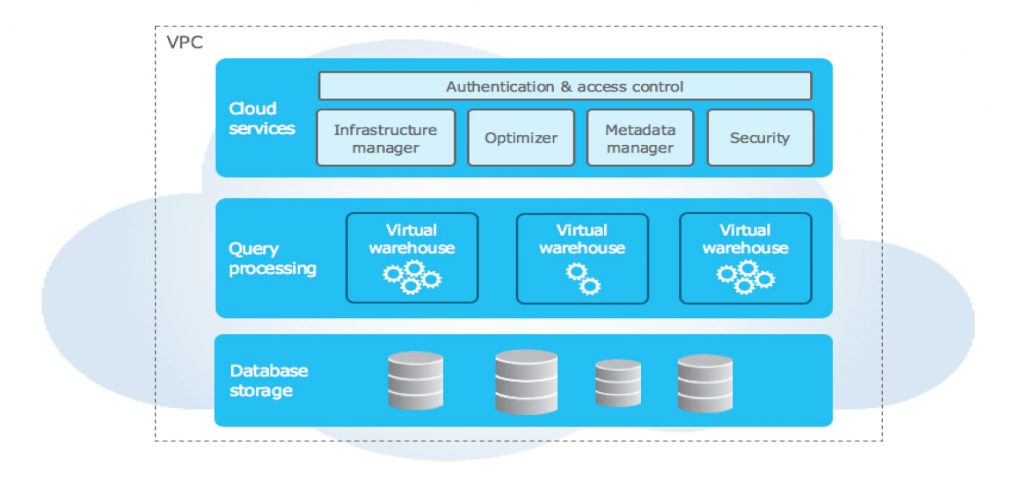
Spark & Snowflake both, have capabilities to perform data analysis on different kinds of data like,
-
- Structured (Data in Tabular format such as csv etc. )
- Semi-structured ( such as JSON, Avro, ORC, Parquet and XML ).
Let’s understand what we mean when we use the term ‘Semi-structured data’.
Semi-structured data is data with nested data structures and the lack of a fixed schema & contains semantic tags or other types of mark-ups that identify individual and distinct entities within the data.
JSON is one type of semi-structured data & it can be generated from many sources like smart devices or Rest API calls or in response to an event or request.
In this blog, we will understand the mechanism used to process JSON and how its data can be utilized for Data Analysis by executing analytical SQL Queries with the following Cloud Service/Frameworks,
- Spark (using Scala Code)
- Snowflake (using SQL)
Before going into processing mechanism, let’s shallow dive into JSON.
JSON stands for JavaScript Object Notation. A JSON (.json file) can contains multiple JSON objects surrounded by curly braces {}. JSON Object consists of two primary elements, keys and values. Following is an example of a simple JSON which has three JSON objects.

The above JSON is an Array of multiple employee JSON objects.
Object Keys are: employee_id, employee _name, email & car_model.
Object Values are: 03, “Jai”, jai87@gmail.com & Ford.
What is “Complex JSON”
JSON can be called complex if it contains nested elements (e.g. Array of Arrays of JSON Objects)

The above JSON contains multiple ‘cars dealer’ JSON Objects and each dealer object contains a nesting array of “cars” & the cars array contains another nesting array of “models”.
Another Example of Complex JSON (e.g. car_servicing_details.json )
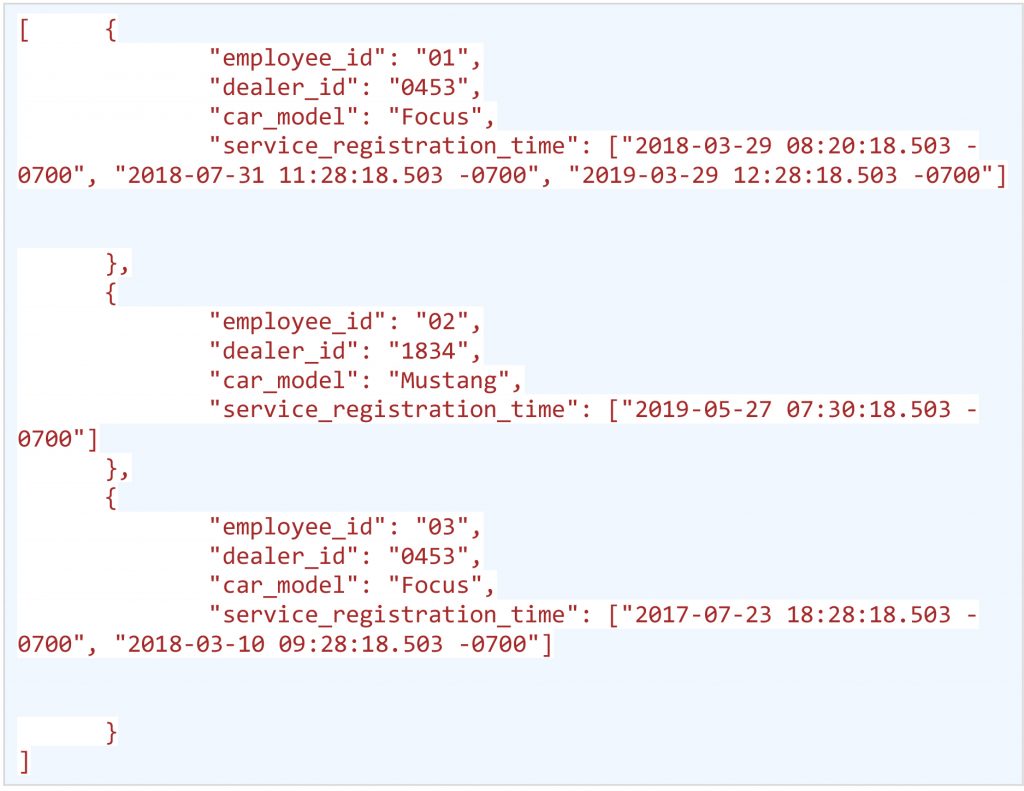
In this blog, all the above JSONs will be referred to as “Raw JSONs” (dealer, employee & car_servicing_details).
Processing JSON in Spark
In Spark, JSON can be processed from different Data Storage layers like Local, HDFS, S3, RDBMS or NoSQL. In this blog, I will be covering the processing of JSON from HDFS only.
Spark makes processing of JSON easy via SparkSQL API using SQLContext object (org.apache.spark.sql.SQLContext) and converts it into Spark Data Frame and executes SQL Analytical Queries on top of it.
- Before processing JSON, need to execute the following required steps to create an SQLContext Object

- Once we have an SQLContext Object (sqlcontext) ready, we can start reading the JSON.



Based on business needs, Spark Data Frame (sparkjsondf) features/functions can be used to perform operations on JSON Data, such as knowing its schema/structure, displaying its data or extracting the data of specific key(s) or section(s) or renaming Keys or exploding Arrays to complete the JSON into a structured table.
Now, let’s move on to understanding such a functionality step by step.
- Printing Schema of Raw JSONs.

dealer JSON Schema…
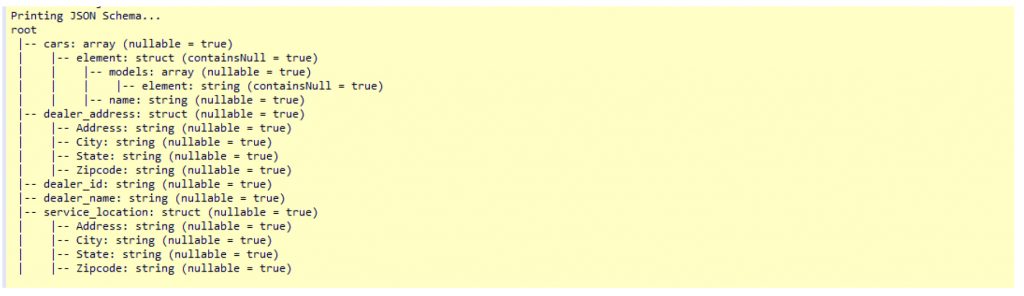
employee JSON Schema…

car servicing details JSON Schema…

- Print the Raw JSONs data of Data Frame

dealer JSON data…

employee JSON data…

car servicing JSON data…

- Reading a Specific Key (name of the car “name”) of JSON… (cars -> name)


- Reading a specific section of JSON


- Explode complete dealer JSON into one data frame.

dealerExplodeTable Data Frame

Similar to dealer data frame, creating data frame for complete employee & car_service_details respectively by exploding raw employee & car_servicing_details JSONs.employeedf and car_service_timeDF Data Frame
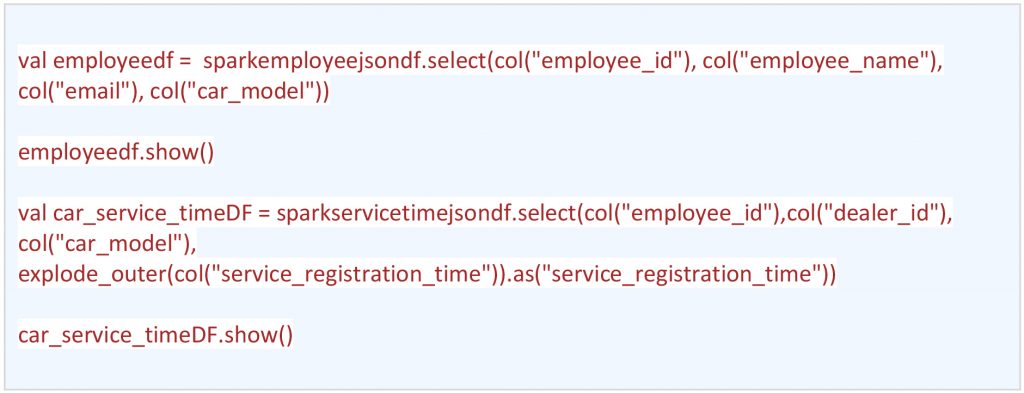

- Keeping structured and semi-structured data together.

- Executing Analytical SQL Queries
Analytical Query I: (Group by Operation)

Analytical Query II: (Joining of two JSONs)


Analytical Query III: (Subquery, Where and Order by Condition)


Analytical Query IV: (Order by on Timestamp Column)


This entire process has detailed what it takes to successfully complete the processing of JSON using Spark. Now, we will go through the step-by-step process of coming to the same result using Snowflake.
Processing of JSON in Snowflake
In Snowflake, Data (structured or semi-structured) processing is done using SQL (structured query language). To run SQL queries, the basic requirements are a Snowflake account and the following interfaces to connect with the respective account.
- SnowSQL (A command like tool)
- Web ( https://<Account_Name>.snowflakecomputing.com/console/login )
JSON Data can be uploaded using PUT command which can be executed using only SnowSQL. (For how to use SnowSQL, please refer to this link)
Once connected with a Snowflake Account using SnowSQL, the following steps must be followed.
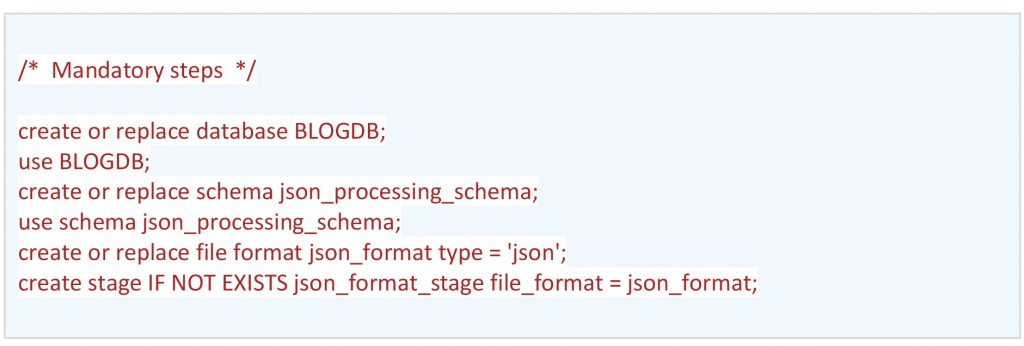
- Following are the mandatory steps (creates database, schema, file format & creating internal stage) required, before processing the JSON in snowflake.

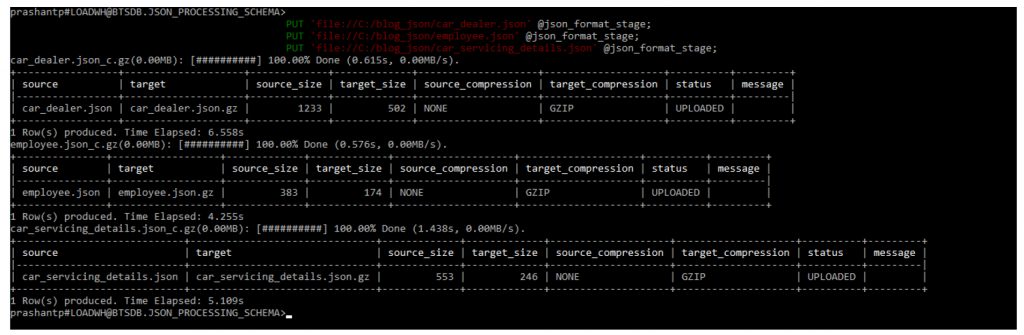
- Raw JSON data will be Copied using PUT command from the local machine to Snowflake’s Internal Stage (e.g. json_format_stage)



Moving ahead we are going to use Snowflake’s Web Interface to execute Queries.
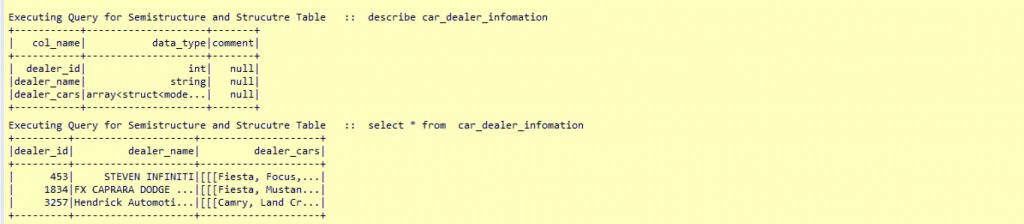
- Similar to Spark, we will need to flatten the “dealer” array using the “lateral flatten” function of Snowflake SQL to insert the same into a “car_dealer_info” table.

Now, we will execute the rest of the SQL queries using Snowflake Web Interface instead of SnowSQL
- Print the data of the table read from JSON


- Reading a Specific Key (name of the car “name”) of Raw JSON… (cars[] -> name )

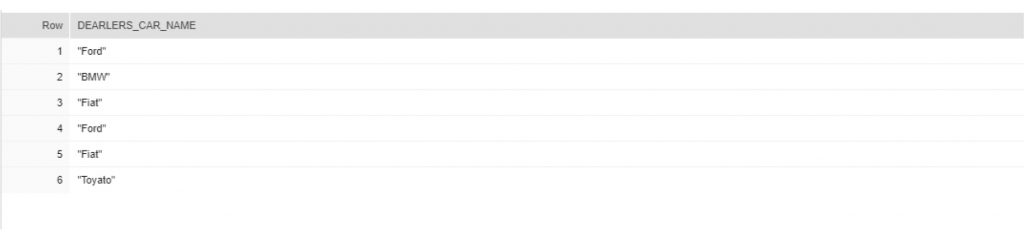
- Reading a specific section… (The address section of each dealer)


- Explode complete JSON into one table ( “dealers_info”) using lateral flatten function.

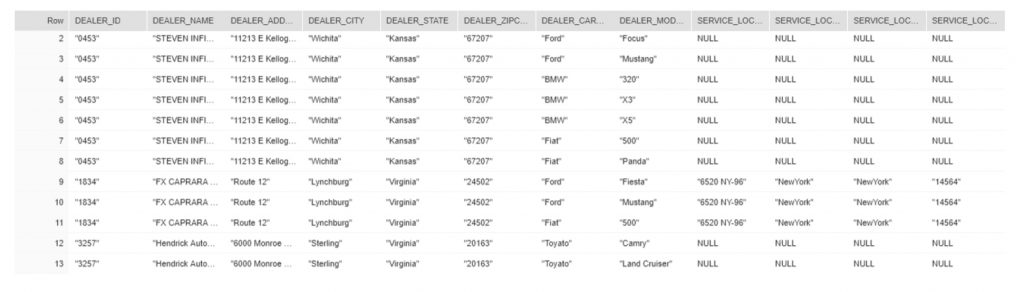
Similar to dealer_info table, creating employee & car_service_details tables by exploding Raw employee & car_servicing_details JSONs.

EMPLOYEE Table

CAR_SERVICE_DETAILS Table

- Keeping structured and semi-structure Data together.

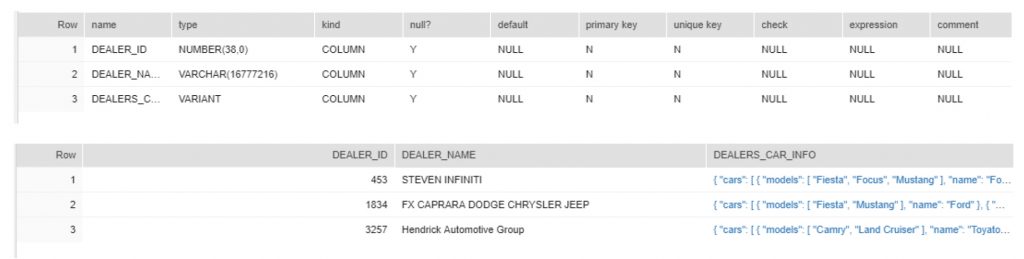
- Executing the same Analytical Queries which were executed in Spark as per our previous section.
Analytical Query I: (Group by Operation)


Analytical Query II: (Joining of Two JSONs)


Analytical Query III: (Subquery, Where and Order by Condition)


Analytical Query IV: (Order by Query on Timestamp Column)


Conclusion:
Overall, both Spark and Snowflake have their own way of processing complex JSON and Run Analytical Queries. The following table provides an overview of the same.
Features:
| JSON Processing | Spark | Snowflake |
|---|---|---|
| JSON Data Source | HDFS/Local/S3/RDBMS/NoSQL | Snowflake Internal or External Stage ( S3). |
| Processing JSON | SQLContext & Data Frame APIs | SQL using Web and Command Line Interface ( SnowSQL ) |
| Programming language | Java/Scala/Python | SQL/Pyhton |
| Processing Engine | Spark Core | SQL Database Engine |
| Structure & JSON Semi-structure Data Together? | Yes, both can be part of the Spark SQL Table. | Yes, both can be part of One Snowflake Table. |
| Joining Two JSON Data | Yes ( Ref. Analytical Query II ) | Yes ( Ref. Analytical Query II ) |
| Where Condition in SQL Query | Yes ( Ref. Analytical Query III ) | Yes ( Ref. Analytical Query III ) |
| Subquery in SQL Query | Yes ( Ref. Analytical Query III ) | Yes ( Ref. Analytical Query III ) |
| Support Data Type Ordering | Yes ( Ref. Analytical Query IV ) | Yes ( Ref. Analytical Query IV ) |
| If JSON Format is Not Fixed | By using explode_outer function Insert NULL value | By Including outer => true in lateral flatten function insert NULL value |
| Group By | Yes ( Ref. Analytical Query I ) | Yes ( Ref. Analytical Query I ) |














