
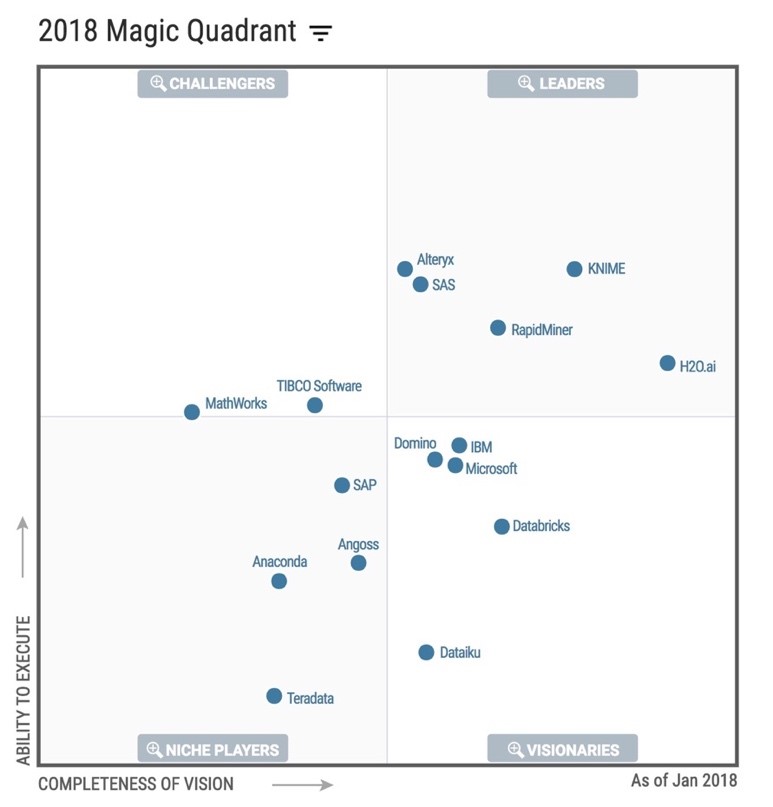
We are continuing our ML Platform blog series with this look at H2O.ai. H2O.ai founder Sri Ambati places a lot of emphasis on “democratizing AI”. The aim is to make model creation, training and tuning easy so that you don’t need formal statistics or programming know-how – at least that’s the vision. H2O.ai is a startup that has built the core product H2O as an open-source ML engine with a very intuitive user interface called H2O Flow. H2O has been consistently featured in the Gartner Magic Quadrant of Analytics platforms. They also have a licensed offering called H2O Driverless AI – which aims at simplifying many of the featuring engineering tasks for data scientists. More recently, they introduced H2O Q, an offering that aims to speed up business decisions using data. For this discussion, we will mainly talk about the open-source version and how it fits with the various facets of an ML Platform outlined in our earlier blog post here.
What is H2O?
H2O is a platform for ML that is written in Java. You need a JDK top run this and upon starting it runs a very intuitive web UI called H2O Flow. H2O may be installed directly as a stand-alone application running on JDK or deployed into a Docker container or hosted on a remote server called by an API. They have Python and R wrappers available that can call a H2O instance running locally or on a remote server. Internally, when you call the Python or R API, the appropriate API calls are invoked, and data is moved to the H2O cluster. H2O provides an optimized execution environment that can run on a single node or as a distributed cluster – very similar to a Spark or Hadoop cluster. H2O manages the deployment of models to different nodes and the distributed training of ML jobs. The web UI enables you to run different steps in an ML lifecycle through a menu-driven interface as shown below.
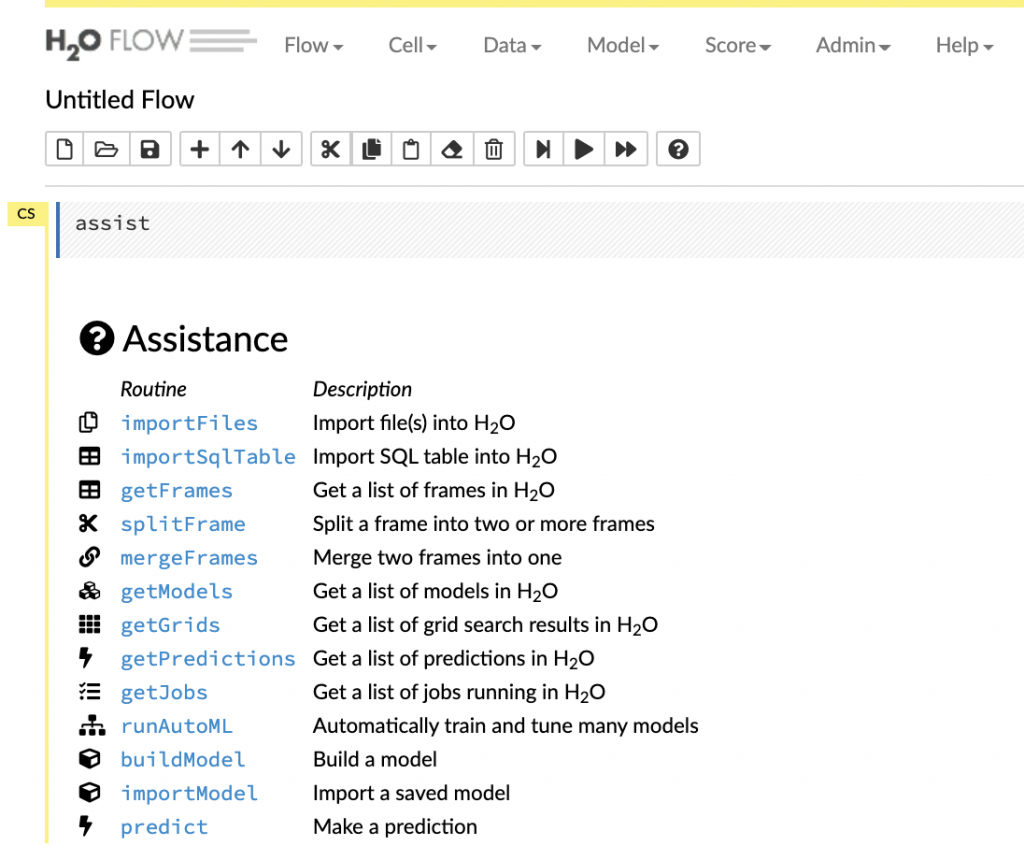
H2O Flow – Web user Interface
- Data Management
H2O lets you connect to a CSV file or a SQL table (supporting JDBC) and pull tabular data from it. The data pulled is stored in a custom binary data structure called DataFrame. You can select the data type for individual features such as numeric, time, string, categorical, etc. When data is imported in a DataFrame, you can see the summary statistics for the entire data and individual features. H2O provides imputation capabilities where missing or invalid data points can be filled in using fixed values or interpolation.
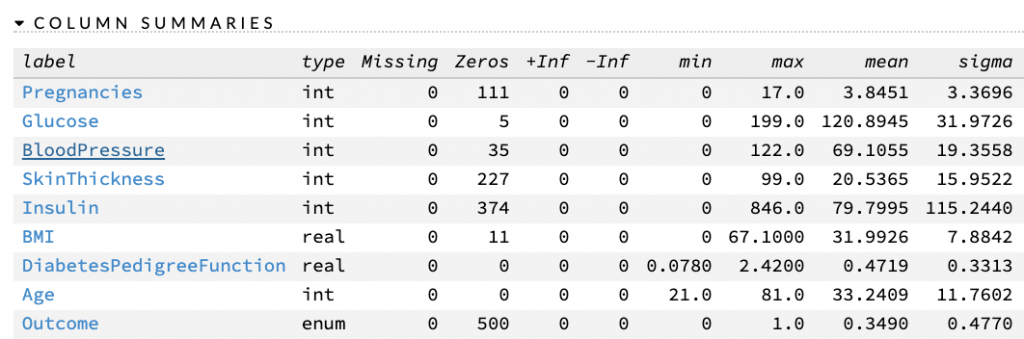
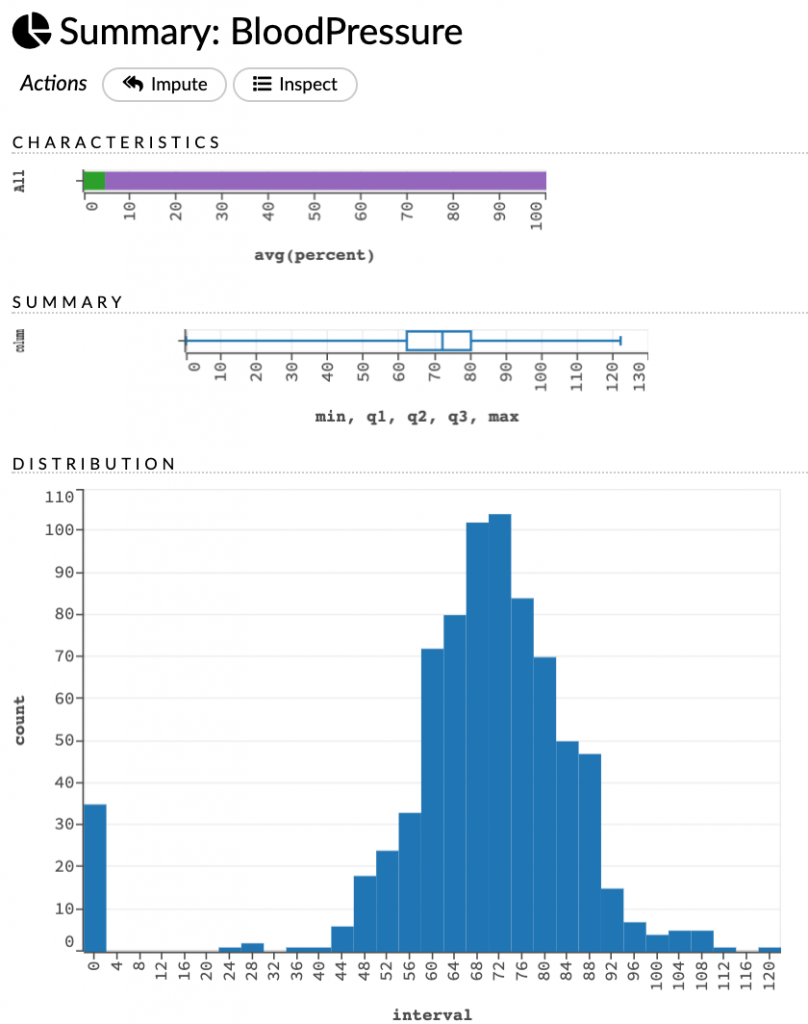
- Model Development
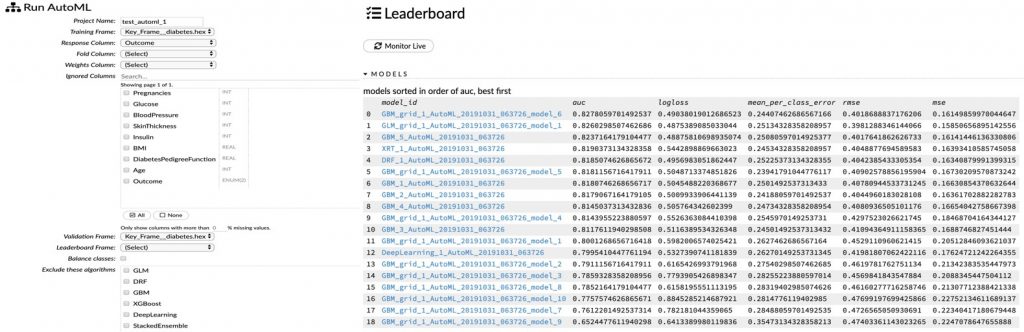
This is an area where H2O truly shines. It supports many algorithms and tunes each algorithm using a combination of hyper-parameters. Particularly for tabular and timeseries data, the rich set of configurable algorithms helps run several experiments on a cluster. Also, the AutoML feature helps you automatically select the best hyper-parameter combinations based on the available dataset. AutoML helps try out several algorithms like Gradient Boosting Methods (GBM), Distributed Random Forests (DRF), and Generalized Linear Models (GLM) on multiple hyperparameter combinations. It creates a pretty cool leaderboard comparing the different options. Support for image and text data sources is quite limited.
- Production Deployment
Models developed in H2O can be packaged in their custom binary format and deployed into a cluster. However, a dedicated H2O cluster needs to be set up and maintained. Also, the cluster has limited management and CI/CD capabilities. Hence, using H2O for production deployment may be a good option for smaller enterprises, but larger organizations can integrate with an ML pipeline tool like Kubeflow (using Kubernetes) or MLFlow (using Python VMs) – to build production CI/CD pipelines.
- Model Lifecycle Management
H2O tries to be a full-fledged tool for all aspects of a data science lifecycle. However, there are lot of gaps especially in model versioning, lineage, and other lifecycle aspects. You can train and deploy models in the H2O library, but these tend to get very opinionated and have limited integration with other packages like TensorFlow, PyTorch, etc. Hence, it is advisable to integrate H2O with a lifecycle management tool like MLFlow which can address some of these concerns while H2O can focus on what it does best – model development and hyper-parameter tuning.
Summary
H2O is a very powerful and feature-rich ML platform that aims to address the various challenges in the lifecycle of an ML project. However, the key areas it shines in are model development and AutoML – especially for tabular and timeseries data. Support for other data sources and ML lifecycle is on the cards and the team is good at constantly rolling out new, useful features.
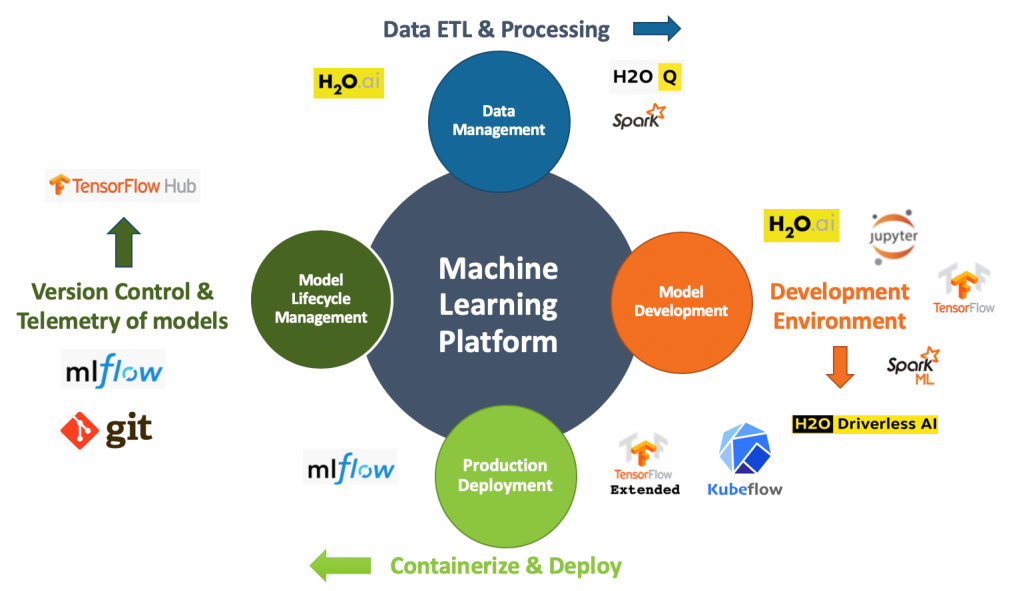
We recommend combining H2O with an ML pipeline management tool like KubeFlow and MLFlow to build a holistic on-premises ML platform. As shown in the figure below, we see this combination of H2O and MLFlow addressing key concerns of an ML Platform.



Find more content about
Data Management (5) big data analytics (3) Analytics Platform (1) H2O.ai (1) Machine Learning Platforms (1)











