The growth and opportunities in Artificial Intelligence (AI) are unlimited. Gartner predicts the business value created by AI will reach $3.9T in 2022. Furthermore, Deloitte Global predicts that among companies that adopt AI technology, 70 percent will obtain AI capabilities through cloud-based enterprise software, and 65 percent will create AI applications using cloud-based development services. Keeping an eye on these numbers is Microsoft, which through its cloud-computing service Azure has introduced a suite of applications directed both at,
- Non-coders/ Business-minded people: By making AI more accessible
- Machine Learning Practitioners: By reducing some of the heavy lifting involved in building and deploying scalable machine learning (ML) models
Some of the ways Azure provides for incorporating AI into solutions are,
Cognitive Services: API endpoints to tackle some of our common business use-cases around Computer Vision, Natural Language Processing and Speech Recognition
Azure Machine Learning Studio: A collaborative Drag-and-drop tool for quickly and easily building Machine Learning models without writing a single line of code
Azure Machine Learning Service: Azure Jupyter Notebooks for developing easily scalable and deployable machine learning models in familiar Python environments
Here, I will share my experience of using the Azure Machine Learning Service.
WHY ML IN THE CLOUD?
For starters, as a data scientist who is used to the comfort of their local Jupyter Notebooks, one might ask why ML in the cloud? Well, simply because the cloud provides us the benefit of faster & more-efficient models (using cloud computing resources) and easy one-click deployment capabilities. This is cost-effective as well as optimal use of time & efforts. Below, through an example use-case, we will go through how to effectively use Azure Machine Learning Services.
Predicting Loan Defaulters using Azure Machine Learning Services
‘Lending Club’ is a p2p lending platform. Given loan data for all loans issued from 2007 till 2018, we need to build a model for predicting loan defaulters. For this purpose, we will be using Azure Machine Learning Services (AMLS) for building and deploying a machine learning model in the most efficient manner.
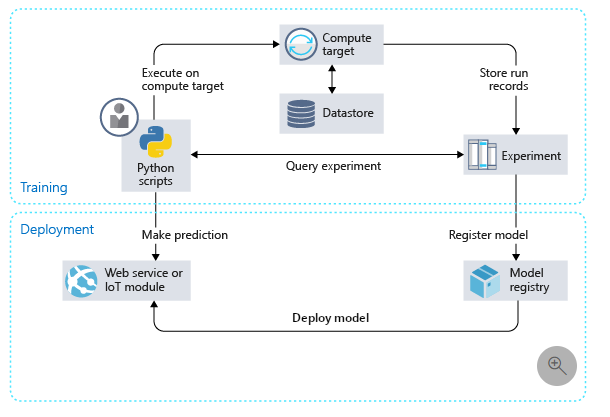
All Azure resources can be accessed through the Azure Portal. Within the portal, we create a Workspace which is the central location for compute targets, data storage, models and docker images created and webservices deployed.
Machine learning models in Python can be built-in Jupyter Notebooks either by accessing Azure Jupyter Notebooks or through the newly introduced Notebook-VMs. The former provides easy accessibility whereas the latter gives a secure, enterprise-ready solution to building models in Jupyter Notebooks. Alternatively, we could also launch a Jupyter Notebook from our Data Science Virtual Machine.
1. ACCESSING DATA
File sizes up to 100 MB can be uploaded on Azure Notebooks through the Upload tab
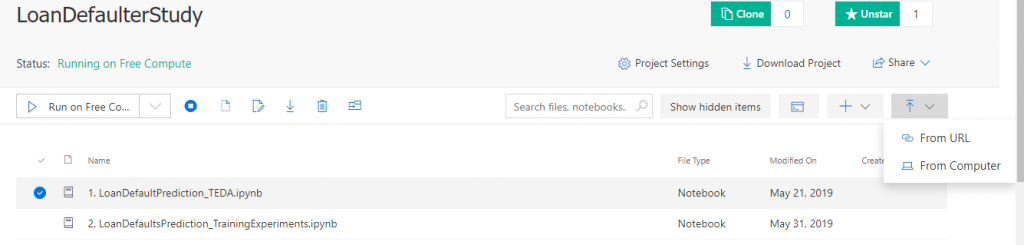
For files greater than 100MB, we need to access data through Datastores. Datastores are compute location independent mechanisms that access storage. Storage of any type such as an Azure Blob Container, Azure Data Lake and Azure File Share can be registered as a datastore in a workspace. Once a datastore has been registered with a workspace, data can be uploaded to it or downloaded from it using the associated credentials.
2. MODEL TRAINING
Depending on the computation requirements, a Machine Learning model on AMLS can be trained on a variety of resources such as a Local Compute (your local machine), an Azure Machine Learning Compute or your Remote VM. Compute Target can be created either through the Azure Portal, Azure CLI or Azure Machine Learning SDK. Previously created Compute Targets can also be reused by attaching them to our Workspace. Compute targets attached to a workspace can then be configured to contain the Python environment and dependencies needed for running our training script.
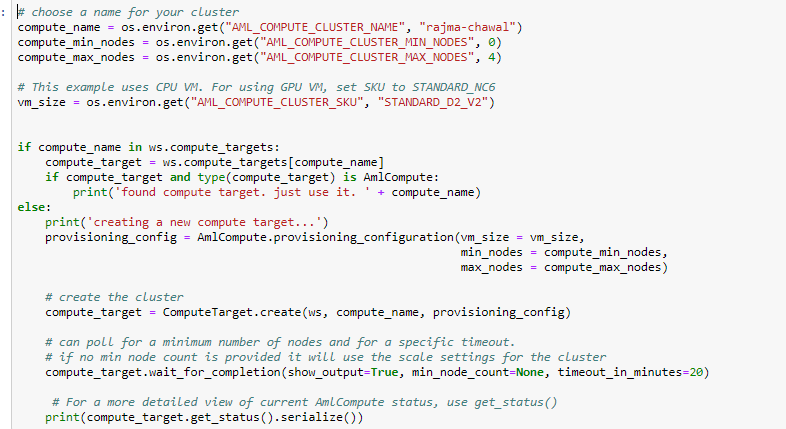
Below, I have created an Azure Machine Learning Compute with maximum 4 nodes
i) SUBMIT A TRAINING RUN
Submitting a training run is same across all compute-targets and involves the creation of an experiment.
Within the AMLS parlance, Experiment is a collection of related runs and a Run is an execution of Python code that does a machine learning task, such as model training. Within the run, we can log metrics and keep track of our experimentation. For example, if we train different models to solve the same problem, we can group the training runs under the same experiment, and later compare their results.
Once an experiment has been created and run within it, tracked with the user-provided performance metrics, the experiment is then submitted with an Estimator object. This object includes the source directory of training script, the name of the training script, the config of the compute target to be used and the dependencies that the training script may require.
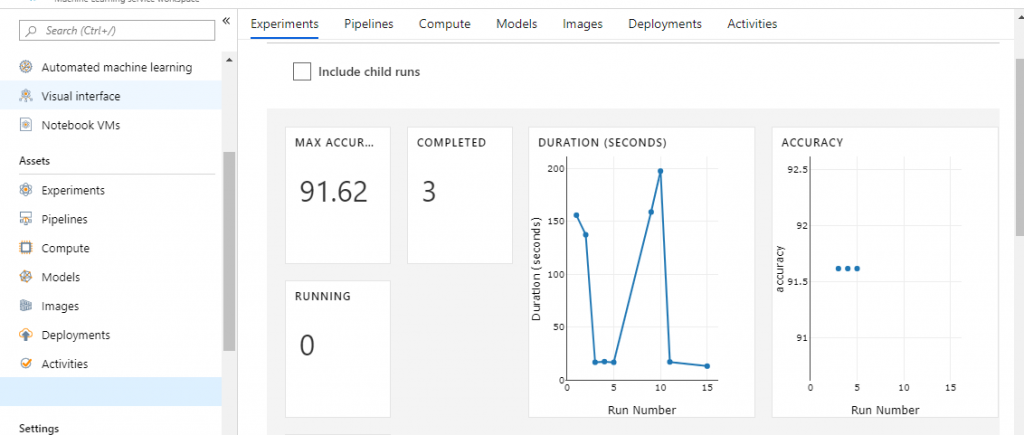
Below figure shows statistics for runs from the training experiment ‘LoanDefaultersPrediction’. The maximum accuracy observed across runs was 91.62%.
3. MODEL DEPLOYMENT
Once a model has been trained, it can be deployed in cloud or to an IoT device. Deployments can be done with various compute targets such as Azure Container Instances (good for low-scale dev workloads), Azure Kubernetes Service (good for high-scale production workloads) and Azure IoT Edge (deployed to an IoT device). Here we will go through steps involved in deploying our trained loan defaulter prediction model using Azure Container Instances (ACI).
a) Registering trained models
The first step of deployment using ACI is registering a trained model in the workspace. The model registry is a way to store and organize our trained models in the Azure cloud. Models trained anywhere can be registered in the workspace, all we need is a trained pickle file.
b) Define Scoring script & dependencies
To deploy as a web service, we need to create an inference configuration (InferenceConfig). In the inference config, we specify the scoring script and dependencies needed to serve our model. The scoring script contains two functions that load and run the model:
- init(): Typically this function loads the model into a global object. This function is run only once when the Docker container for our web service is started.
- run(input_data): This function uses the trained model to predict a value based on the input data. Inputs and outputs to the run typically use JSON for serialization and de-serialization.
c) Define deployment configuration & deploy the model
The final step involves defining the deployment configuration which is specific to the compute target that will host the webservice. We define the compute target configuration used for hosting the webservice and the container configuration which will be used for deployment.
For consuming this webservice, we can get the scoring URI for the deployed container and ping it with data to get predictions.
SUMMARY
To summarize, we have gone through the complete life-cycle of building and deploying machine learning model using Azure Machine Learning Services objective. In addition to the above steps, there’s also the option of automating hyperparameter exploration using the AMLS Hyperdrive library. It does so in the most efficient manner by providing a range of hyperparameter sampling strategies (Random, Grid-Search, Bayesian) and various options for terminating poorly performing runs (early stopping policies). Alternatively, we could also go for an automated way of the complete machine-learning model building using AutoML which will search for the best ML model given a dataset and training.



Find more content about
machine learning (13) Artificial Intelligence (11) Machine Intelligence (2) AI (4) ML (3) ML Platforms (1)











