
AI is the new electricity, and data is the new oil. These words are often quoted during conference keynotes and on social media. Thomas Edison invented the electric bulb in 1878 and fast forward to 2019 – we cannot imagine our life without electricity. It has become an essential part of our life. Along the same lines, the very first AI applications were simple applications such as weather forecasting. Now we witness highly personalized applications like book or movie recommendations, intelligent traffic route navigators, conversational personal assistants, wellness apps, early disease diagnosis, etc. To generate highly accurate personal recommendations, we need access to a large amount of private, personal data, and this is why tech giants like Google, Facebook, Amazon, and Microsoft dominate the AI market today. “We don’t have better algorithms than anyone else; we just have more data,” admitted Google’s Chief Scientist Peter Norvig. Hyper-personalization comes with a huge cost – loss of privacy. Events like the Cambridge Analytics Scandal raised concerns about confidentiality and data privacy. Many international agencies are now forming laws and regulations for the protection of private data like GDPR in Europe.
A fundamental procedure for preserving an individual’s privacy in a training set is data-anonymization. It is a procedure to remove personally identifiable information from data sets. Although it is a simple technique, it is not foolproof. Netflix hosted a Million-Dollar Challenge for the data science community that involved sharing movie reviews provided by 480,189 anonymous users for 17,770 movies. However, Arvind Narayanan and Vitaly Shmatikov demonstrated a robust De-anonymization Technique which used the publicly available Internet Movie Database (IMDB) as the source of data and successfully identified Netflix records of known users, uncovering their apparent political preferences and other potentially sensitive information. Another technique, known as Differential Privacy, has been receiving a lot of attention lately. In this technique, a certain amount of “noise” is added to the data without letting users know about it. The fundamental concept here is, unless anyone has access to the denoising function, that party cannot retrieve the original data. Though this technique is scalable, there is some concern regarding the amount of noise that should be added to the data so that the original information is not lost. People have proven that differential privacy can be breached if a hacking party queries the data long enough and eventually figures out the pattern of the noise added to the data. Some researchers are working on advanced encryption techniques called Homomorphic Encryption, where mathematical operations can be performed directly on encrypted data. When the outcome of the mathematical operation is decrypted, it is identical to the outcome of the same operation performed on un-encrypted data. This may look exciting but is yet to be stress-tested on complex and iterative mathematical operations in machine learning.
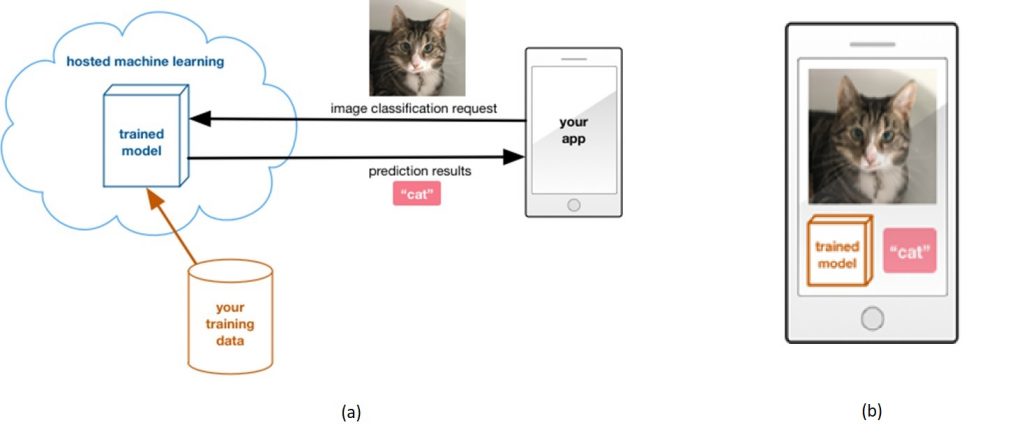
The primary cause of a privacy breach is someone’s personal data being shared with someone else. But what if that data is processed in the same place that it originated? In a traditional machine learning scenario, imagine that you are developing an image recognition application. You need to transfer all the training data to a central place or in the cloud for model building. Once the model is trained, you have to send the test image back to the central server, and you get the outcome or inference on the client as shown in Figure 1(a). There are two fundamental limitations of this approach. 1. Privacy is not preserved. 2. Time lag in receiving the inference back from the cloud service. Imagine a mission-critical model like a driverless car. You cannot rely on a cloud-based service to decide whether to hit the brakes when they see a pedestrian in the car’s way. Processing capabilities in edge devices like cell phones have advanced significantly, enabling us to make inferences on the device. Here, the model is trained at a central location and deployed on the edge device for instant inference as shown in Figure 1(b). This has solved the time lag issue and has enabled cell phone applications with excellent user experience and instant inference capabilities. However, centralized model training still needs all the data to be collected in a single place and is therefore vulnerable to privacy breaches. It is not possible to build a machine learning model without accessing private data.
What is Federated Learning?
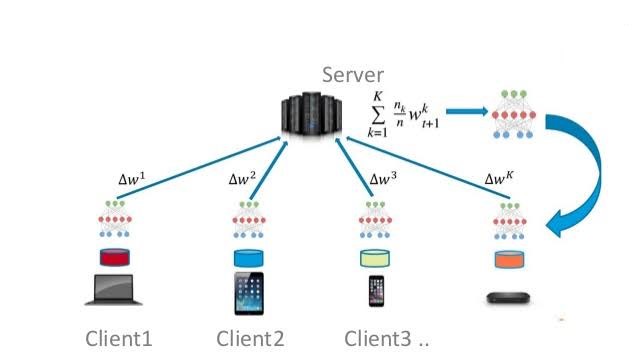
Federated learning is a technique to train machine learning models on data to which you do not have access. Instead of collecting all data within a central cloud and building a model, we will bring the model to the data, train it locally wherever the data lives, and upload model updates to the central server. The term federated learning first surfaced in a research paper by Google in 2016. Let’s take the example of a machine learning model to detect credit card fraud. Customer financial transaction data is highly sensitive and cannot be shared outside a bank’s network for building a model. Individual banks may design their fraud detection model, but it may not be accurate because one bank might not encounter all kinds of fraudulent attacks. So, for an individual bank, the training data is not enough to build a highly accurate model. The solution is to form a federation of multiple banks and assign a central party to manage the model building process. The baseline model is trained at a central location on some publicly available datasets. Let’s call it the first-cut model. This first-cut model is shared with all the banks, and then it is fine-tuned locally by each bank on its private data. The updated weights are then shared with the central party by each member of the federation. The central party then aggregates the individual model weights and performs differential aggregation to build a better model. The updated model is sent back to each member of the federation as shown in Figure 2. Thus, each bank can train their machine learning models using private data without sharing it with external parties. So, the data is not uploaded, but the ability to predict is uploaded.
Applications of Federated Learning
Apart from banking, federated learning can be effectively applied in the healthcare domain. Medical institutions relay their in-house datasets to build machine learning models. But such datasets are biased in terms of patient demographics, instruments used, or clinical specializations. Federated learning makes it possible to gain experience from a vast range of data located at different sites. Nvidia researchers recently published their work on Federated Deep Learning with King’s College, London, on brain tumor segmentation. This approach could revolutionize how AI models are trained, with the benefits also filtering out into the broader healthcare ecosystem. Wellness apps using smartphones or wearable smart devices provide wider opportunities to leverage federated learning.
How Do You Carry Out Federated Learning?
Google has developed a federated learning framework called TensorFlow federated, which is an open-source framework for experimenting with decentralized machine learning. Another option is PySyft, which is an open-source library developed on top of the PyTorch framework. WeBank’s AI group has initiated an open-source project called Federated AI Technology Enabler (FATE) to provide a secure computing framework to support Federated Learning. There are some research challenges to be addressed like scalability and network bandwidth issues when federated learning is applied to billions of smartphones, and each device sends updated model parameters back to the central party. Several research groups are working towards addressing this limitation, and we can hope to see a lot of smartphone-based Federated Learning applications soon.



Find more content about
machine learning (13) Artificial Intelligence (11) AI (4) Cloud-based Service (1) Federated Learning (1)











