
We were recently building a demo of Reinforcement Learning (RL), where the objective was to control the temperature setting on a ship based on external temperature and humidity. As you know, RL is all about training an agent that learns through trial-and-error by observing an environment trying to maximize the rewards for taking actions. This contrasts with traditional supervised learning, where we provide a static dataset, and the model adapts itself to the data. In RL, the agent devises its strategy to sample data from the environment and uses this for training. Ultimately, the agent learns a policy to take the right action based on the state of the environment and the expected future rewards. So in our problem, we wanted to train the agent to learn the best policy to set the air conditioning temperature to minimize power consumption.
The major hurdle for RL problems is the need for a simulation environment that can show us the results of actions taken by our agent. We need to know the state transition probabilities and rewards for different actions. This is modeled as a Markov Decision Process, capturing the inner dynamics of our environment. For this problem, we developed a custom environment using the OpenAI Gym library, which simulates the ship conditions with temperature and humidity readings. Then, using human domain knowledge, we modeled a reward function that would penalize any action that violated temperature limits and rewarded actions that minimized power consumption. We used basic rules of thumb to model the reward function, but this can easily be extrapolated for complex scenarios.
Ultimately, using this reward function, we could train an agent that would predict the optimal setting for the ship’s temperature based on external temperature and humidity – thus, maximizing fuel consumption. The results are in the chart below –
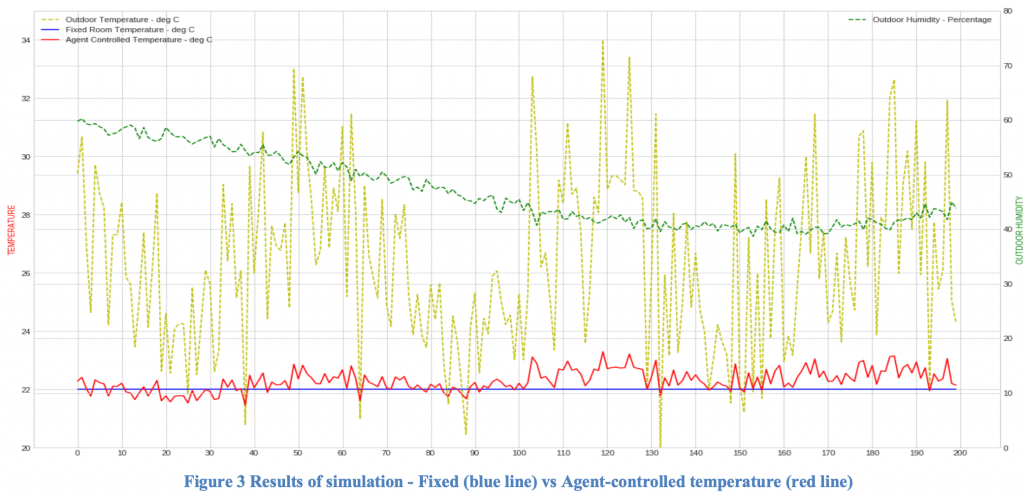
Our detailed research paper on this topic has been in the Cornell University Library and is available for free at: https://arxiv.org/pdf/1909.07116.pdf
All our code, including the simulator for rewards, is available on Google Colab at: https://colab.research.google.com/drive/1JQxLS2DSv5mO1i_68pd_uOQVNwCy1kEw



Find more content about
machine learning (13) Artificial Intelligence (11) Machine Learning Models (3) OpenAI (1) Reinforcement Learning (2)


