
For various applications today, ranging from Netflix’s Recommendation Engine to Self-driven Cars, Machine Learning has completely transformed the Business operations & processes!
According to Fortune Business Insights, it is estimated that the global machine learning market is projected to grow from $15.50 billion in 2021 to $152.24 billion in 2028 with a CAGR of stunning 38.6% . Yes, the future of machine learning surely seems bright as analytics driven technical solutions continue to evolve and hold immense potential!! However, these systems aren’t perfect and deploying them without understanding their decision-making process might be a huge risk that can at times amount to loss of human lives or millions of dollars, for e.g., if a machine learning model for bank loan eligibility prediction denies the loans to the customers who are likely to pay or approves the loan for the customers who are likely to default then it may lead to losses for the bank.
This misclassification can be owing to various reasons such as faulty hyperparameter tunning, poorly trained model, bad input data, biased set of data, etc. Knowing that there are too many ways which can lead to failure, it can be difficult to trust the model.
Here, is an interesting illustration from our AI/ML experts that will help you understand the role of explainability in the MLOps cycle and how it can enhance the prediction accuracy.
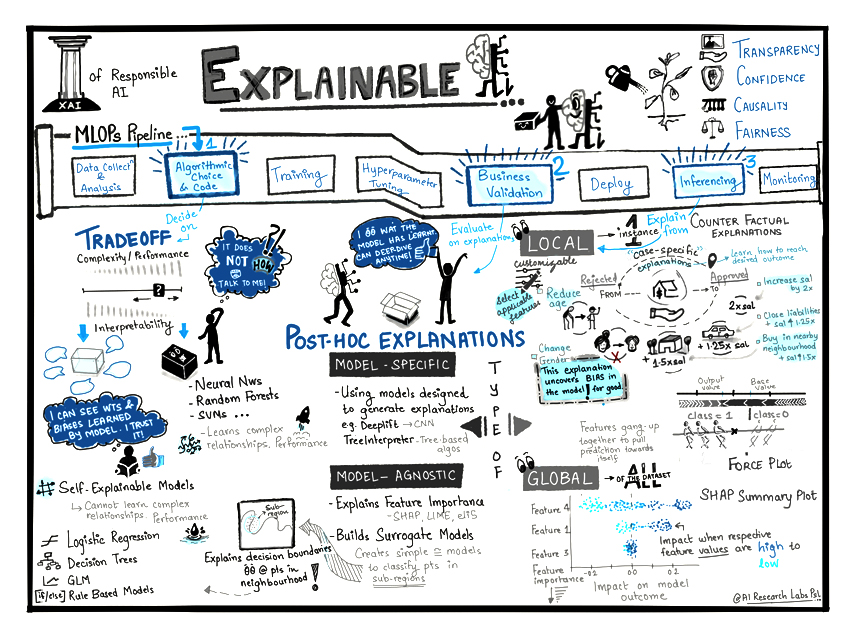
Building Explainable & Transparent ML Models
We can’t fix the bugs in ML models like normal code. We can only iterate with better data, accurate hyperparameters, smarter algorithms and flexible system configurations to train the model. The MLOps pipeline helps to automate the workflow and consists of different components that are connected in a sequential manner.
If you are a data scientist then you have the control to iterate and to make the model better. However, what if you are a user of that model? You don’t have much control and you don’t know why the model’s performance is poor. As there is no transparency, there is no trust! Adding explanations along with the prediction will make the model more trustworthy and transparent.
Transparency @ 3 Stages in MLOps Pipeline
As seen in the illustration (Fig 1) above, Transparency can be included at 3 stages in a MLOPs pipeline.
Stage #1 – Algorithmic Choice and Code
There is always a trade-off between accuracy and explainability.
- Low Accuracy, High Explainaibility –
Less complex algorithms such as logistic regression and decision trees have low accuracy on non-linear relationships and high explainability. As their internal structure is easily understandable, these models are called as ‘glass box’ or ‘self-explainable’ or ‘transparent’ models.
- High Accuracy, Low Explainability –
Highly accurate models such as deep neural networks and ensemble algorithms are less explainable and more complex as they learn non-linear relationships well. Understanding the internal working of complex models by considering millions of parameters is a very difficult task, so these models are called as ‘opaque’ or ‘black box’ models.
- Making the Right Choice –
The trade-off should be decided according to the application domain and end-users, for e.g., banks, healthcare domain, insurance companies would prefer highly explainable models over highly accurate models as they are answerable for their decisions and processes.
Stage #2 – Business Validation
Machine learning algorithms learn from the training data and generalize for the data which the model has never seen before.
- Decoding Patterns of Learning –
Explanations help to understand the patterns learned by the model, for e.g., a ‘feature importance plot’ shows which features are important in decision making. If the domain expert approves it then we can say that the model has learned correct patterns from the data otherwise we will have to iterate with a better data or algorithm.
- Model Agnostic & Model Specific Explainability –
Post hoc explainability methods are designed for models which are not self-explainable. They are divided into two kinds depending on the type – ‘model agnostic’ and ‘model specific’ – based on the data considered – local and global. Model agnostic methods can generate explanations irrespective of the algorithm used to train the model. On the other hand, model specific explanation methods are particularly designed for some class of algorithms, for e.g., treeinterpreter can generate explanations only for tree-based algorithms.
- Local & Global Explanations –
Local explanations consider single instance to generate the explanations, whereas global explanation methods take into account the whole training dataset. Models are approved for the deployment after confirmation by the domain expert.
Stage #3 – Inferencing
Keeping the model explainable in inferencing also helps us monitor for changing data patterns.
- Case Specific or Local Explanations –
A deployed model is used by the end users, if the model generates explanations along with the prediction then it will answer all their questions. These explanations are called as ‘case-specific explanations’ or ‘local explanations’. The local explanations can be generated using LIME and SHAP to show which features are contributing to the decision making.
- Counterfactual Explainable AI –
Without revealing the internals of the model, human level explanations can be generated using counterfactual methods. Counterfactuals identify the changes required in the feature values to accomplish desired prediction rather than pointing out the attributes contributing to the current prediction, for e.g., if the ML model rejects the loan application of a person then the counterfactual explanation could be that if his/her income was more than 50000 then only the loan application would be accepted.
The applicable features could be selected from the explanations to create a plan of action, for e.g., if the explanation says that age is on the higher side because of which the model rejected an application, then nothing can be done. However, it is good to know the reason as to why the application was rejected.
- Eliminating Bias in ML Models –
If the explanation says changing the gender will help get the application approved, then it uncovers a bias present in the model which could be corrected for a fair world.
Thus, as seen in our illustration (Fig 1), by including explanations at various stages of MLOps pipeline, we can include transparency, confidence, causality and fairness in the pipeline. This further leads to more responsible and reliable machine learning models that generate accurate predictive outcomes. At Persistent, we customise and build high-quality robust AI/ML models at scale for all your business-critical applications. To explore how our Artificial Intelligence & Machine Learning offerings can add value to your business, connect with us at: airesearch@persistent.com














