
The Business Case
Resolving incidents is one of the key functions of IT Service Management (ITSM) in any organization. ITSM provides efficient solutions to issues, requests, and makes provisions to keep the business going. Also, ITSM is under constant pressure to improve issue resolution speed while decreasing costs.
A typical ITSM resolution process looks something like this –
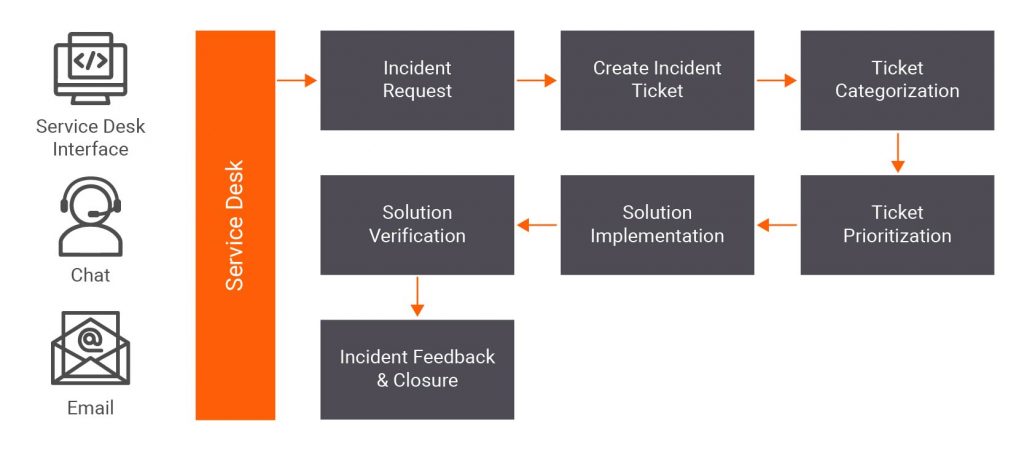
Incidents are recorded as tickets with various details such as requester, severity, incident id, submission date, contact details, status, and description.
Ticket categorization is important for prioritization to ensure service operations meet the agreed SLA. Incorrect manual categorization of tickets causes delays in the right team addressing the issue and multiple re-assignments to various teams cause unmet SLA, putting the business at risk. Accurate ticket categorization helps assign tickets to the right team and saves time.
Also, manual prioritization of tickets is based on personal experience and can be biased. For example, instead of checking the issue description, an employee may assign priority based on incident category or predetermined priority or their understanding of the business functionality.
NLP to the rescue
The process defined above can be streamlined for prioritization using an artificial intelligence-based solution. The solution would aim to reduce categorization errors caused by manual intervention and increase the overall resolution efficiency through accurate prioritization.
The solution operates around the clock and processes automated incident requests from generating tickets to assigning tickets to the right support team.
Natural Language Processing (NLP) techniques can be used to extract insights from the textual information in the tickets. Using NLP for ticket data can help determine the criticality and priority of the ticket.
The NLP Approach
NLP techniques are used to read, decipher, understand, and make sense of human language through the appropriate context. In NLP, you apply algorithms to identify and extract rules, apply them to language data, and convert them for computers to understand.
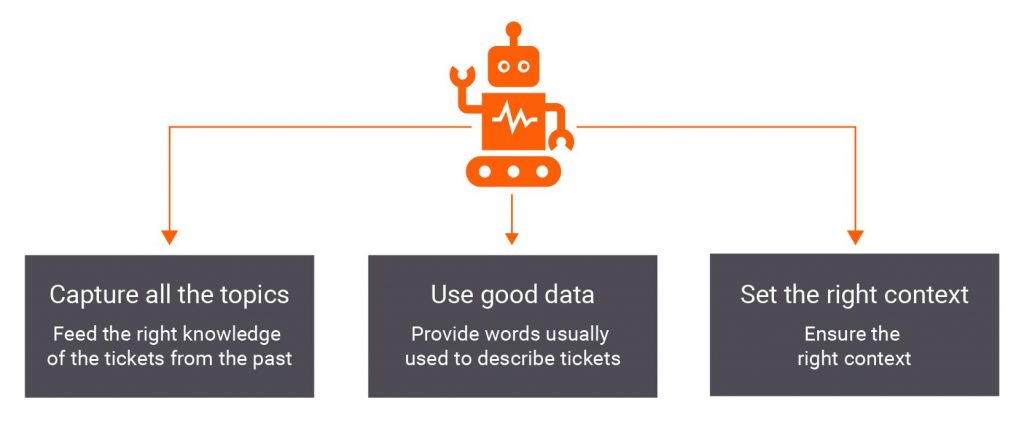
For correctly prioritizing incident tickets, keep the following in mind –
NLP Processing Pipeline
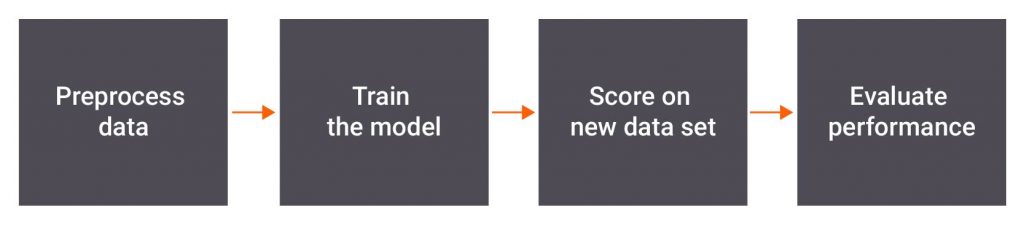
- Pre-process data – Pre-processing is necessary for NLP to show its magic. It’s a stepwise approach which transforms text into something a model can ingest easily –
-
- Data Cleansing – remove stop-word, capitalization from ticket description
- Tokenization – split sentences into individual words
- Parts of Speech Tagging – determine the meaning of a ticket description with the rule-based method
- Stemming – reduction of multiple words into a common residue word
- Lemmatization – morphological analysis of words using dictionaries
- Normalization – the process of transforming the text into a canonical form
- Train the model – Provide historical ticket data to algorithms which will help categorize tickets as ‘high-risk’ and ‘low-risk’. Initially, you might need to try out multiple algorithms before arriving at the algorithm that works the best.
- Score on new data set – Here you use various mathematical concepts to determine the accuracy and precision of the categorization. Intuitive visualizations will represent categorization results and provide trade-offs between various strategies used in the solution.
- Evaluate performance – The performance of various classifier techniques represents the performance of the solution. A comparative study of the graphs plotted here characterizes the ongoing performance of the solution.
The solution can be deployed in the following ways –
- Integration with ITSM interface with REST API
- Incorporate solution within the ITSM system itself
Challenges
1. Setting the right context
The most challenging part is to define the right context. Incident request data is highly structured data but contains one hidden detail – the incident symptom – the cause behind the issue. To identify this detail, you can –
- retrieve as much incident-related data from incident logging to emails to chats (if any) to make the symptom description as rich as possible
- use robust pre-processing techniques
2. Skewed data
Certain predefined ticket categories occur more frequently than others. We try to minimize the impact of such tickets through –
- using ticket data from a variety of predefined categories to train the model
- creating sample data, if required
- providing the results to the ITSM team and incorporate their feedback
So, what do we achieve?
- Improved customer service feedback and high satisfaction scores
- Reduction in the overall cost of missed SLAs
- Reduction in time to identify root causes of critical issues
- Ability to predict the likeliness of a ticket breaking the SLA as soon as it is assigned to an IT personnel
- Ability to interact with multiple systems and share predictions with each dispatcher when the ticket is assigned
- Flexibility to deploy the solution across multiple locations
- A robust text mining process to digest unstructured text














