
An assignment I was working on a few months ago involved predicting the renewal rates of different products that had different parameters. This time-bound activity needed to produce qualitative results and thus it had me analyzing various data sets, making histograms, imputing missing values, normalizing data and more. Despite applying various pre-processing techniques, fitting various models and attempting innumerable dimensionality reduction methods due to the large data size, I was unable to bring down the RMSE (Root Mean Square Error) score. With the clock ticking, I began to get more than a little worried!
Fortunately, I had some training in the deep learning RNN model I could lean on, which gave me some satisfactory results that we presentable to the client. But satisfactory is not something I was happy with! While performing this analysis on Python, I realized that a tool, into which I could drop this dataset and use different drag and drop features to perform different types of analysis, would be highly convenient and time-efficient.
Although several cloud-based sources like Google, Microsoft and Amazon can provide various tools to accomplish tasks like these, however when dealing with sensitive client data, one needs to be more diligent when choosing the right tool. It was while exploring these options that I came across the DataIKU Data Studio (DSS).
What is Dataiku DSS?
An AI-powered data product, Dataiku DSS provides machine learning capabilities with a user-friendly graphical interface. This collaborative data science software platform is perfect for teams of data scientists, data analysts, and engineers to explore, prototype, build, and deliver data products in a quick and efficient way.
It is available in different categories, at varying price-points and for a range of Operating Systems, but the best part is that the trial version is free. For my specific requirements, I went ahead and downloaded the ‘.ova’ file and installed it in the virtual machine. After a quick installation, I was excited and ready to explore the tool.
Here is what I found.
Key Features
Following are some key highlights of Dataiku DSS that can give you a quick introduction to the tool.
- Allows input from the various sources
- Contains various data pre-processing techniques
- Holds auto-ML capabilities
- Includes inbuilt ML algorithms and options to provide custom algorithms
- Provides various evaluation metrics and export options
- Enables easy dashboard creation
- Supports ML model deployment with Rest API
Another great feature of DSS is that it provides a step-by-step tutorial for quickly setting up a project. The ML data required is preloaded. Users can follow this tutorial page for a quick overview of tools. For demo purposes, I am unable to share details about my previous work since it involves sensitive client data, therefore I will show you the tool’s capabilities with the very popular ‘titanic’ data set. You can download the set from here.
Once you have the tool and the data set handy, we can start the model building process. Please note, during this model building, I will be skipping the data pre-processing part and feature engineering part.
Demonstration
Please follow the tutorial given in the reference section and create a sample project. Then, import the data and Titanic data set into it. Create a sample lab environment and configure the different algorithms as shown in the images below.
1) Model building
Image 1 features the different available algorithms and configuration options. To see all the algorithms, go to Design -> Modeling -> Algorithms. You can change the different hyperparameter of any algorithm in this window. A variety of feature engineering and feature reduction options are also available.
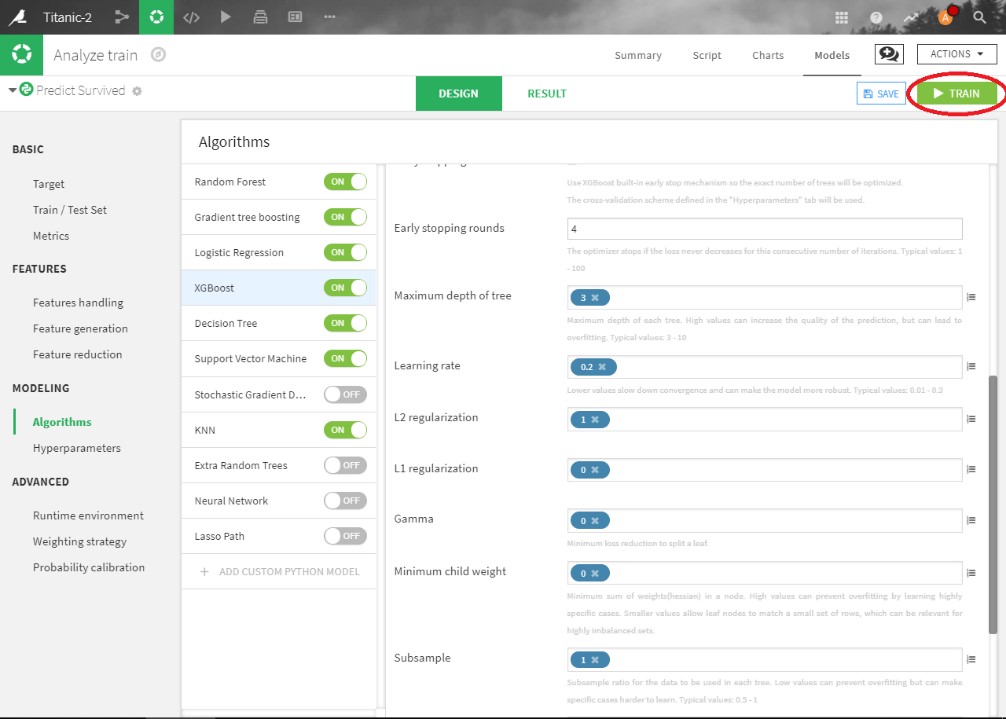
2) Result
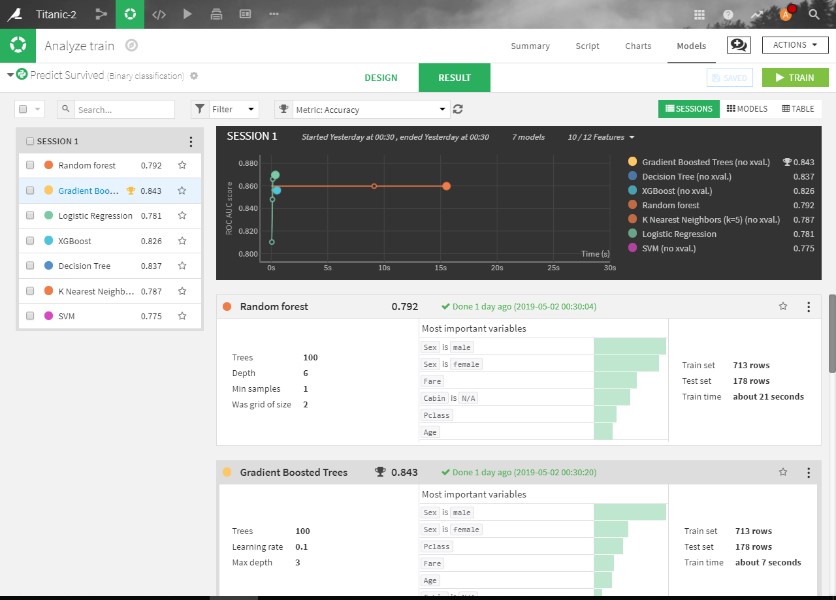
Without modifying any parameters, I start the training with the default 80:20 train/test ratio. Execution is very quick and results get generated in less than 2 minutes. Image 2 has more details. Surprisingly, DSS gives 90% accuracy on test data for “Gradian Boosting Tree” with Auto ML capability, all in less than 2 minutes. Apart from GBM, other algorithms also perform astonishingly well. For every algorithm, internal details like confusion metric, accuracy, ROC curves, key features are available in their individual algorithm tab.
Architecture Of DSS
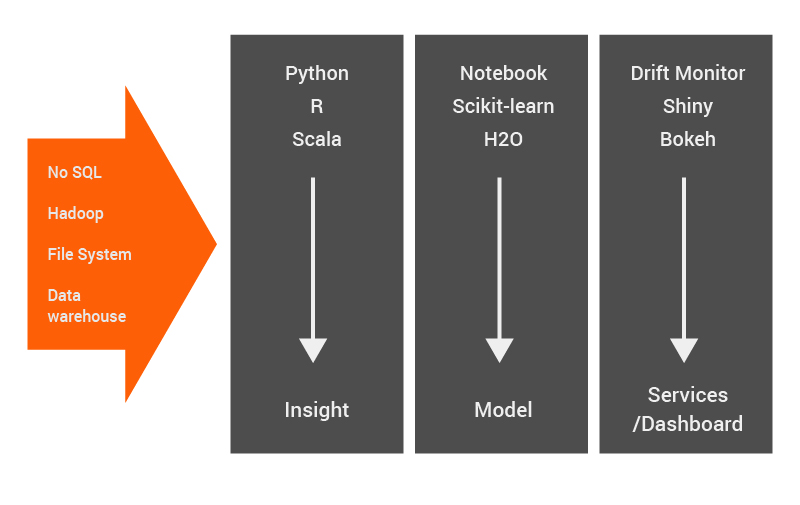
DSS Architecture
The DSS Architecture, as shown in the above image from the perspective of Data Science, has 3 major components – Insight, Model and Services/Dashboard. DSS also supports many advanced features using which one can enhance the model’s capability, namely –
1) Input: DSS can take inputs from different sources like the SQL dataset, Hadoop & Spark, No-SQL database, cloud-based dataset, and file system as shown in Architecture.
2) Explorative Data Analysis: DSS provides a wide variety of options for data processing techniques. This part forms the ‘insights’ that the architecture is able to provide. These include,
- Building univariate statistics automatically & deriving data quality checks
- Filtering data based on different criteria
- Offering data cleansing and string pre-processing methods
- Providing different numeric formulae to process numeric fields
- Presenting custom formulae in Python or R
3) Data Visualization: DSS provides different visualization to plots. This is also a feature that provides insights. This involves,
- Creating standard charts (histogram, bar chart, etc.) and scale charts’ computation by leveraging underlying systems
- Creating custom charts using Custom Python-based or R-based Charts
4) Model Generation: This provides a wide variety of Machine Learning models with the ability to handle a variety of features. This forms the ‘model’ part of the architecture and includes the following characteristics,
- Feature handling for Machine Learning
- Support for numerical, categorical, text and vector features
- Automatic pre-processing of categorical features (Dummy encoding, impact coding, hashing, custom pre-processing, etc.)
- Automatic pre-processing of numerical features (Standard scaling, quantile-based binning, custom pre-processing, etc.)
- Automatic pre-processing of text features (TF/ IDF, Hashing trick, Truncated SVD, Custom pre-processing)
- Various strategies for imputation of missing values
- Features generation
- Feature-per-feature derived variables (square, square root, etc.)
- Linear and polynomial combinations
- Features selection
- Filter and embedded methods
- Features generation
- Outliers detection in clustering methods
- In-build support for hyperparameter optimization with grid search
- Analysis of graphical model results with different parameters for supervised and unsupervised techniques
- Deep Learning support
5) Dashboard: (Services/Dashboard part of Architecture)
- Dashboard mechanism that showcases insights
- Graphs from Data Visualization methods can be exported to the dashboard with one click
- Different model artifacts like an optimal set of parameters and scoring metrics (AUC ROC, confusion metrics, accuracy, etc.) can be exported to the dashboard
- The dashboard can be exported in PPT and PDF format
6) Deployment:
- Inbuilt capability for production deployment with version control
- Bundles of the developed model, train data and other folders created. Bundles can be deployed on any node with the help of Dataiku.
The above features only cover the Machine Learning aspects, there are many more features to be explored and utilized.
Conclusion
We have explored only a small portion of what the DataIKU DSS is capable of. DSS supports various functionalities related to diverse ML tasks and provides a one-click option to build dashboards quickly. In addition to ML tasks, DSS also provides parallel computing, GPU support and Rest API services. Clearly, we have a very powerful tool on our hands that can be useful for developing POCs very quickly.
I encourage you to explore this tool with the links I have provided throughout the article and also via the reference links listed below.
References
1) Dataiku: https://www.dataiku.com/
2) Dataiku Tutorial:- https://www.dataiku.com/learn/portals/tutorials.html














