
Very often, we get requests from our customers for workshops on Data Lake. We discuss whether to create a data lake, are there adequate use cases, the technology stack decisions for building the Data Lake platform, security of the data etc. Often, there is an indecision whether Data Lake is necessary. Data Lake is still not very widely spread concept but is an upcoming trend. It is still not a pressing requirement for many of the organizations, but people visualize that it will enable a broad range of users to explore the organizational data, there will be a better control over the data and its lineage. All of that of course will lead into better understanding of the data in the business.
For information, let us look at the definition of Data Lake. James Dixon, the founder and the CTO of Pentaho coined the term Data Lake and defined it as below:
“If you think of a DataMart as a store of bottled water – cleansed and packaged and structured for easy consumption – the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.”
Data Lake is not yet a necessity for every organization. There are cases where one may choose to go for a Data Lake and there are other where one will not. In this blog, we will see some patterns of both these cases. The next section dives into these cases.
To Data Lake or not to Data Lake….
Data in the organizations has started growing enormously. Organizations want to harness all the raw granular structured and unstructured data for machine learning, discovery and such purposes in addition to the conventional analytics that is derived out of data warehouses. There is still a need to create and maintain the data warehouse for business users for traditional analytics. Question that comes to us many a times is whether to have a data warehouse or a Data Lake? As the two are complementary in many of the cases, we may need both. There are some cases, where we need just the data warehouse.
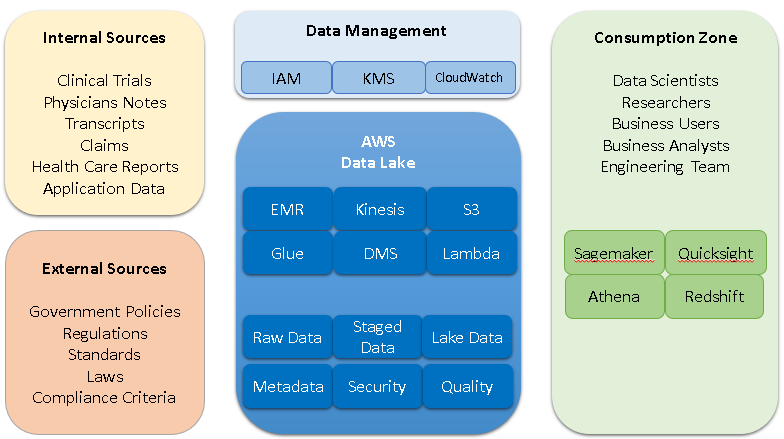
Case Study I: Let us take a Healthcare business case. There is a huge amount of data that is unstructured like clinical trials, physicians’ notes, transcripts, health care reports etc. The velocity of data that comes in from various sources is usually very large. For one of our Healthcare clients, we were discussing whether a data warehouse will fit the needs or would a data lake be necessary. The company has hosted applications that are being used by various clients. Data gets generated at various points in time from the applications, there are standard datasets that are also ingested for referencing like government regulations, compliance standards etc. There are multiple applications hosted by the organization and each of the application generates the data at various points in time. Also, some applications are multi-tenant, and some are not. The spectrum of different user types is also pretty wide. Some users want to look at the trends while there are data scientists who want to explore the data of clinical trials to come up with detailed analysis etc. They had an existing warehouse which however did not meet all their needs. Some of their researchers had to go back to raw data sources for certain use cases. This is a very apt pattern where a data lake was suitable.
In this case we designed a data lake based on AWS S3. All the data is moved into AWS S3 at various intervals and in its most natural form. Limited data that is needed for detailed analysis is moved into the warehouse that is built using AWS Redshift. This design helped us limit the node sizes for Redshift and thereby limiting the ongoing cost. AWS S3 being a low-cost option, all the data is stored in there. This is made available using Athena to a set of users who want to explore the data and find patterns, do Machine Learning and have pricing engine/predictions etc. One of the target goals was better data governance. Having a data custodian and governance was possible because of the data lake.
Case Study II: There is another case in marketing domain, where in we saw huge amount of data coming in from sources like transactional applications, CRM and field. Most of the data was structured. All the business users were operating on the data in silos. There was no single source of truth and no master data management. For example, a name of the customer might be spelt differently in different business units! All this lead to chaos. leaders wanted to have a data lake in place. There was another set of leaders who thought that the data lake would turn out to be a data swamp. They thought it would be just another data storage to manage. In their use case, the data sources are well defined and fewer than what we usually see. Most of the data was structured. Most interesting observation was that they did not have a set of users who could use modern tools to explore the data. There were no adequate use cases that would necessitate a data lake. Hence, we finally decided to build a single source of truth – a data warehouse on Redshift. The pattern we discovered here was that if there is no need for sophisticated analysis and if vanilla reports suffice then there is usually no need for a data lake.
Case Study III: In our next use case, for one of the financial companies, the pattern was to maintain the secrecy of the data. The question was whether cloud is an alternative to store the financial data. Most of their analysis was happening over the aggregated data. The business users were the main consumers of the data. They were comfortable using tools like Tableau. We analysed their business needs and data analysis patterns. We did not see an immediate need for the Data Lake, but sensed the need in the future. Hence, we built a Redshift based data warehouse to address their current needs. The source data was stored into AWS S3. Historical data that would not be needed was archived and put into AWS Glacier to lessen the cost even more. S3 was almost like staging but could be expanded as needed. To maintain the secrecy, all the personal identification information was separated and was encrypted and stored in Redshift. The Redshift volume by itself was encrypted. ‘Data in transit and at rest must be encrypted’ was the theme followed. This provided them the needed secrecy. This also enabled an ELT approach that made the handling of the huge amounts of data easier. Our design in this case was such that the architecture could be extended to form a data lake as needed.
Conclusion
The data in the organizations is growing at enormous rate and so are the types of data. The trend in data warehouse architectures today is to diversify the portfolio of data platforms. Users can choose just the right platform for storing, processing, visualizing data sets. Such diversified platforms allow various users to use the data for exploration and discovery-oriented advanced analytics. The platform addresses the need for both technical and business users.
As for the technology used, for a data lake, various design patterns can be adopted like Hadoop or a relational database, cloud or on-premise. Data Lake can very much be built on premise, using a relational database or using Hadoop cluster. Cloud is an obvious option as the whole world is slowly moving to the cloud. Based on the priorities, the organizational trend and needs this choice can be made. The tools used can be traditional like Talend, Informatica (IaaS), S3, Redshift. The other set of tools are Big Data based and code heavy like Kenesis, Spark, MongoDB etc.
Interested in learning more about how to build a new age data lake? Talk to our expert now!














