
The AWS ML stack offers support for Machine Learning projects in three layers. The top layer offers software developer-friendly, ready to consume AI Services such as Rekognition (image recognition), Transcribe (speech to text), Textract (OCR), etc. Whereas the bottom layer offers infrastructure (EC2) and framework support (TensorFlow, Pytorch, MXnet) which can be configured by data scientists for ML workloads. The middle layer is Amazon SageMaker which offers a platform to provide ML infrastructure as a managed service.
The SageMaker platform is designed to support the end-to-end ML model lifecycle, right from model data preparation to model deployment. Its modular architecture makes it flexible as well. This means that you can choose to utilize SageMaker independently for model building, training or deployment.
Accelerate time to productionize ML models

Sagemaker Features
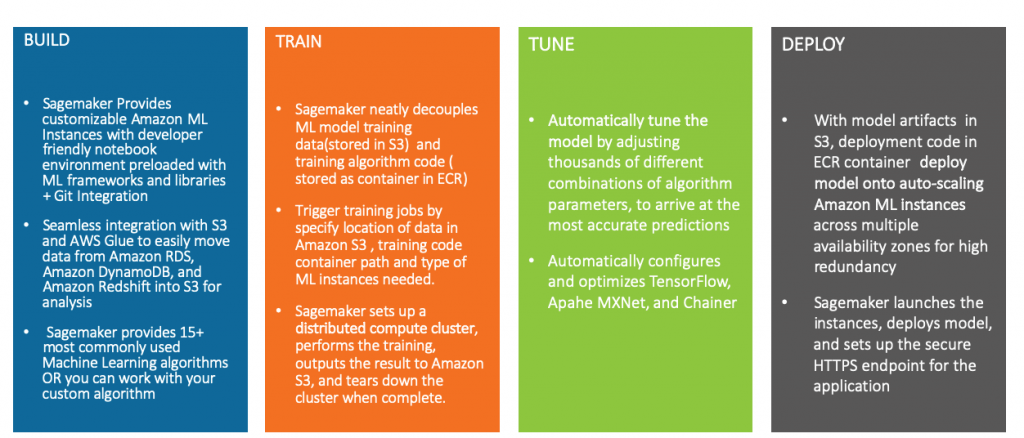
As a Machine Learning platform, a prominent feature of Sagemaker is the ease of getting started with development. The build ML instances launch Jupyter notebook interface where Data scientists and ML engineers can get started immediately. With the data science community predominantly preferring notebooks for iterative data exploration and model development, build instances offer great support for ML model development.
The decoupling of the ML algorithm code and data is where SageMaker starts becoming very appealing to enterprises. Based on the proven container technology preferred in a modern enterprise deployment, SageMaker bridges the gap between data science teams and traditional software development. As an added advantage, SageMaker ships 15+ most commonly used ML Algorithm containers specially designed for distributed training over AWS ML instances.
These built-in algorithm containers contain training and serving code for some industry-standard algorithms such as Gradient Boosted Trees (XGBoost), Image Classification (ResNet), Latent Dirichlet Allocation (LDA), DeepAR for time series forecasting and many more. Furthermore, there is support for custom algorithm containers which allow ML practitioners to package their own custom codes for training and serving.
The ML models can then be hosted on a dedicated AWS ML instance as a live REST endpoint or make bulk predictions using Batch Transform jobs.
Understanding SageMaker Capabilities with an Example
Let’s understand these platform features via an example. Let’s suppose that the task at hand involves predicting existing car insurance customer responses to a cold call for a new sale. We will train a Machine Learning model using all available historical data around customer details and past call metadata. The dataset we will use can be accessed from this Kaggle Competition.
The dataset provides various car insurance customer details such as age, job, marital status, whether they have home insurance, a car loan, etc. as well as the target value of whether the customer purchased the advertised insurance. Mapping the task to Machine Learning terms, the problem statement can be formulated as a numeric binary classification.
We can utilize SageMaker to resolve this problem in multiple ways. One approach would be to use built-in algorithms for binary classification. Alternatively, we could use any algorithm of our choice such as an R algorithm and then package the algorithm as a container for training and deployment.
For the problem at hand, the built-in SageMaker algorithm called XGBoost will be most appropriate.
Exploratory Data Analysis
The first step would be to get acquainted with the data by performing some exploratory data analysis. We can quickly fire up a notebook instance using the SageMaker console, which provides us with the Jupyter notebook.
Data can be loaded onto the notebook instance from any source. We can upload it directly from our work machines or alternatively, data can be easily pulled in from S3 buckets, AWS Athena, AWS Redshift or any other cloud storage services. In case we need to perform sizable ETL operations on input data, we can create AWS Glue jobs which can process the data and make it available in S3 buckets.
Since our car insurance data is small, we could upload the .csv files directly from our work machines. The .csv files can be processed using various preloaded python libraries allowing us to quickly visualize the data and understand the input variables in great detail.
Notebook:
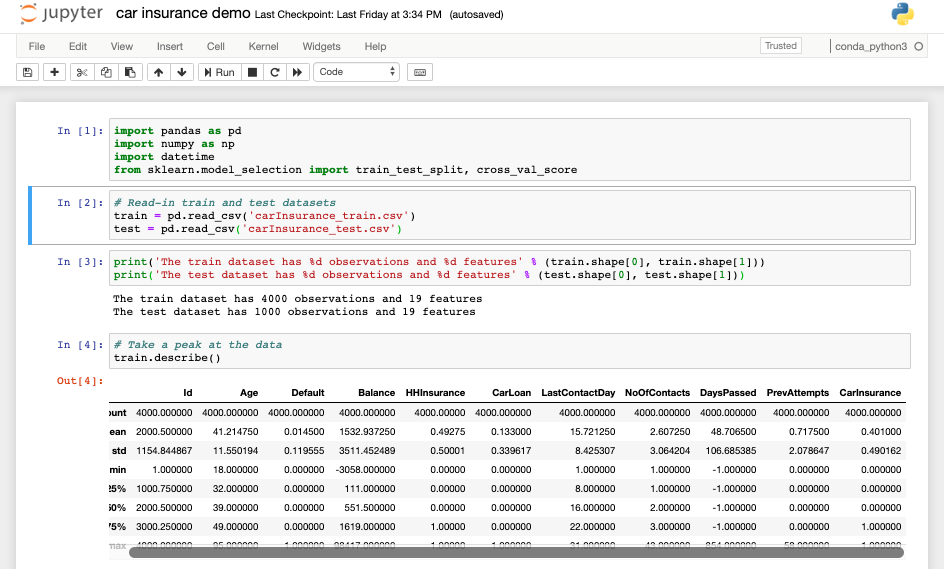
Exploratory Data Analysis using Notebook:
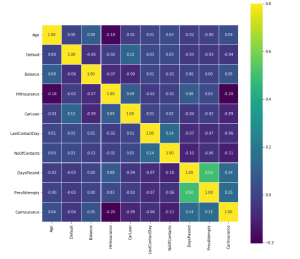
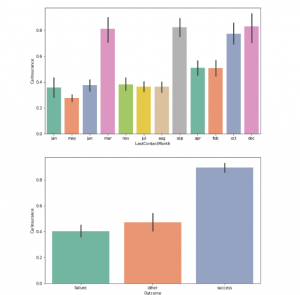
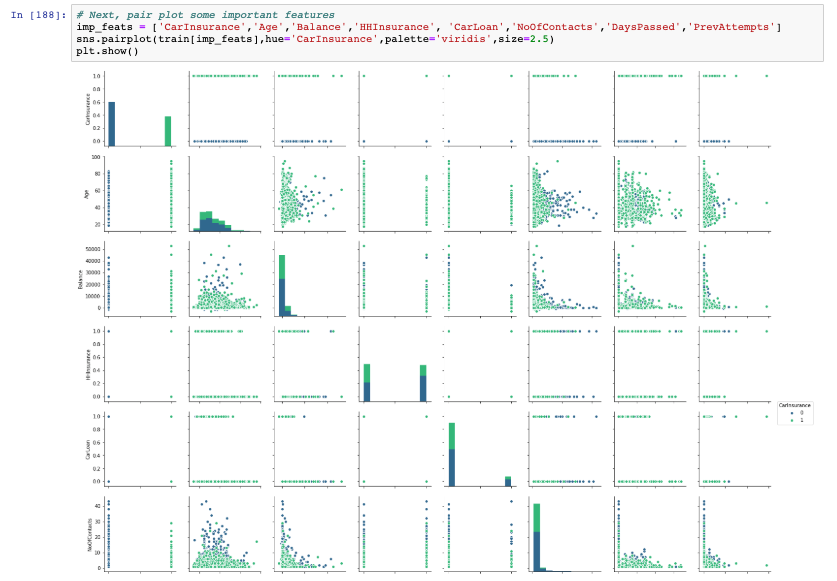
MODEL BUILDING
After understanding the data, we can apply some feature engineering to prepare the data for training.
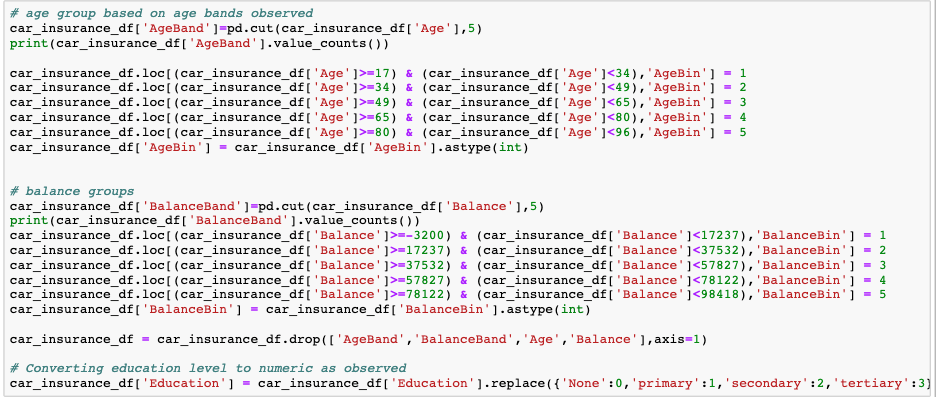
MODEL TRAINING
Now that the data is ready, we can create a training job to build our ML model. A training job requires data to be uploaded to the S3 bucket. We will use the XGBoost algorithm container, which comes built-in with SageMaker, to create our ML model. There are several hyper parameters available for configuration by data scientists. Let’s configure them with default settings and create a training job. We have parameterized the training job to use a single instance of ml.m4.xlarge ML instance and provided a path for input as well as output data.
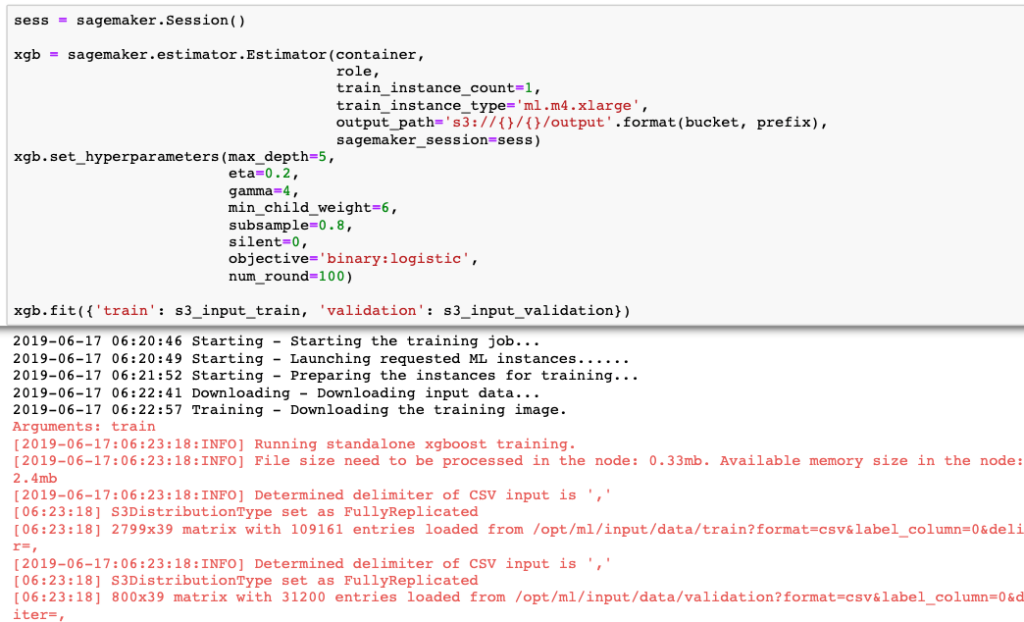
Once we trigger the training job, SageMaker will spin up an ml.m4.xlarge instance, load the algorithm in it, pull data from the input location and execute the training. Once completed, the model artifacts will be available at the output path.
In case the data is very large, say in GBs, we can use the SageMaker pipe mode. For algorithms which support batch training, data can be streamed through the training job. This is highly efficient as we can process a large dataset without the need to configure memory-intensive ML instances. For even more scalability, there are algorithms which support distributed training. We can spin up a cluster of training ML instances for parallel processing which can expedite training times tremendously.
We can now use the SageMaker hosting service to deploy our ML model as a REST API endpoint.
Like the creation of a training job, we can parameterize the deployment by configuring details such as count and the type of ML instance we would want including the model path as well as algorithm container path. The model artefacts are pulled from the S3 bucket and serving code is already packaged in the XGBoost algorithm container. With a command from the notebook instance, we can launch the hosting ml instance and start serving predictions.
MODEL DEPLOYMENT

Now that our model is deployed and ready to serve predictions, let’s test its performance using the test data. The results look pretty good!

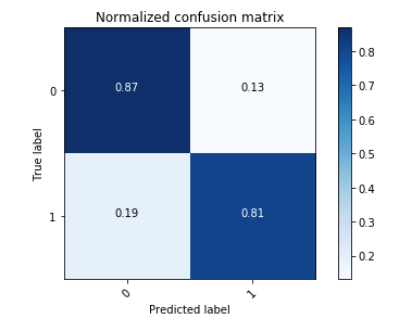
In case we prefer batch predictions as opposed to hosting a live endpoint, we can use the SageMaker Batch Transform feature. Just like a training job, it can spin up an ML instance, run predictions on input data and make the predictions available to the output path. Once done, the batch transform job tears down the ML instance.
Another extremely useful feature is A/B testing. This is used to test the performance of a new model geared towards only a certain subset of users. Sagemaker provides native support for deployment using A/B testing.
MODEL TUNING
Furthermore, as advanced functionality, we can employ the SageMaker hyperparameter tuning to find the best set of hyper parameters for tuning the ML model. On the algorithm XGBoost, SageMaker natively supports hyper parameter tuning. As part of the tuning job, SageMaker will run multiple training jobs and vary the hyper parameters in the ranges provided by the user. On execution, the results of the experiment are provided for the data scientists to choose the best model.
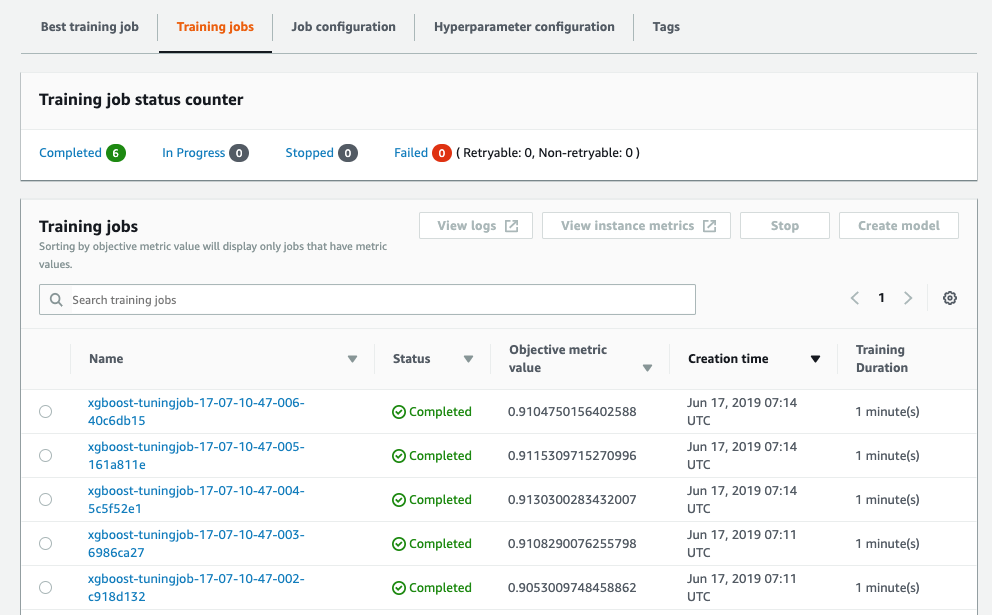
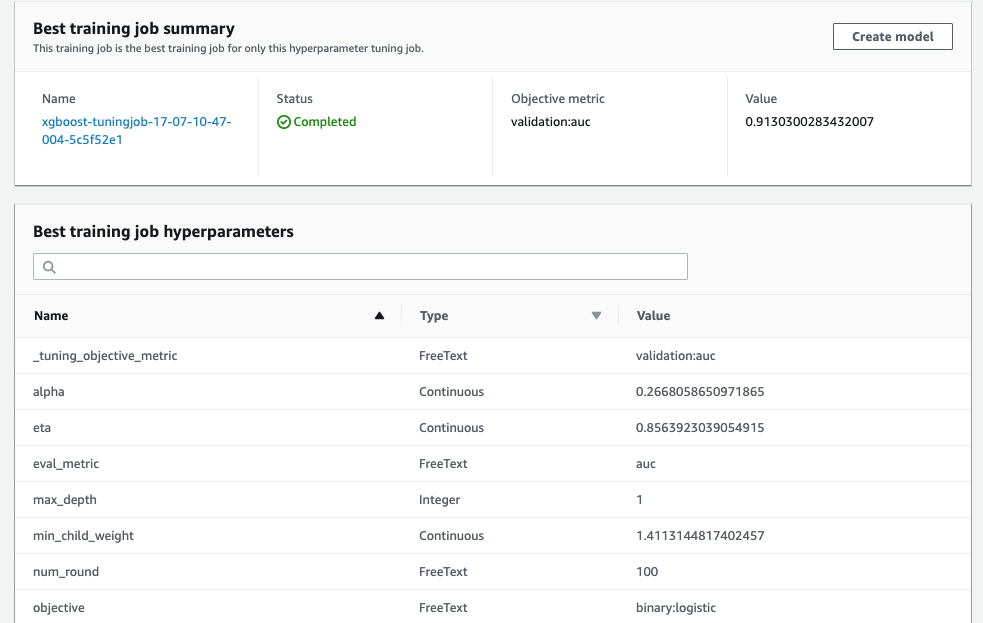
As demonstrated in this example, SageMaker presents itself as a very versatile platform appealing to the novice as well as experienced data scientists alike. Furthermore, all these building blocks of an ML workflow can be stitched together using orchestration tools such as AWS Step Functions, completing the package with support for continuous integration and deployment (CI/CD).
At Persistent, we have been evaluating with Sagemaker platform since its inception on various projects. Team Persistent really appreciates the flexibility provided by the platform to support a wide variety of workloads and we look forward to leveraging its capabilities for the benefit of our clients.
At this year’s AWS Reinvent event, we worked closely with AWS Services and published 10 ready-to-use models on the AWS SageMaker Marketplace for Healthcare, Banking and Manufacturing domains.
Here is a link that details the ML Models we released on the SageMaker Marketplace



Find more content about
machine learning (13) AWS Marketplace (2) SageMaker (2) Amazon Glue (1) Machine Learning Models (3)











