
Introduction
Historically, processing data streams has been a complex and time-consuming task that requires custom code and specialized hardware. In this blog, we explore how three major open-source technologies—Apache Kafka, Apache Flink, and Apache Druid—can unlock the potential of stream processing, enabling real-time data ingestion, processing, and analytics with scalability and reliability. These technologies have gained popularity among industry leaders and are at the heart of a streaming-first architectural deployment pattern known as Kappa architecture. In this pattern, data from various sources is streamed into a messaging system like Apache Kafka, efficiently processed by Apache Flink, and analyzed using Apache Druid.
Stream Processing – An Overview
Stream processing is analogous to a continuous flow of information being processed and analyzed in real time. You can imagine it as a river of data with events or messages flowing through it. These events could range from sensor readings and social media posts to financial transactions. Stream processing enables capturing, processing, and analyzing this continuous stream of information for various applications. It’s ideal for real-time monitoring, social media analysis, outlier detection, and more. To facilitate stream processing, we need a system capable of handling large volumes of data in a distributed and scalable manner, and this is where Apache Kafka plays a crucial role as a robust backbone for event-based pipelines.
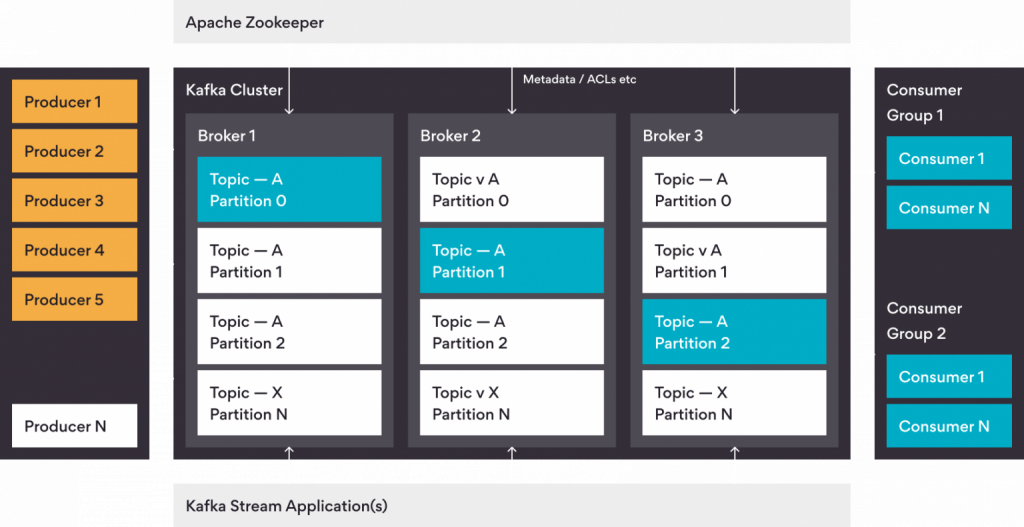
Apache Kafka
Apache Kafka serves as a distributed event store and event streaming platform that efficiently facilitates communication between different applications and systems. You can imagine it as a postal service for data, ensuring messages are delivered to the right recipient in real-time. Kafka is invaluable when various applications need to communicate, even if they use different programming languages or run on different machines. Examples of Kafka’s applications include sharing transaction data among financial institutions and processing millions of real-time user-generated events for social media companies.
Kafka Streams
Kafka Streams, an integral part of Kafka, is a client library for building applications and microservices where input and output data are stored in an Apache Kafka cluster. It allows DSL operators to perform stateful and stateless operations, making it ideal when both the source and destination are Kafka. However, Apache Flink steps in for more complex operations involving heterogeneous data sources.
Apache Flink
Apache Flink is an open-source platform for distributed stream processing and batch processing. It’s a framework and distributed processing engine capable of handling large amounts of data in real time or in batches. Flink empowers organizations to analyze data as it’s generated, supporting quick decision-making based on real-time insights while also enabling batch processing. Flink is renowned for its high processing speed, fault tolerance, and scalability. Thanks to in-memory computation, it processes data efficiently and seamlessly handles continuous data streams.
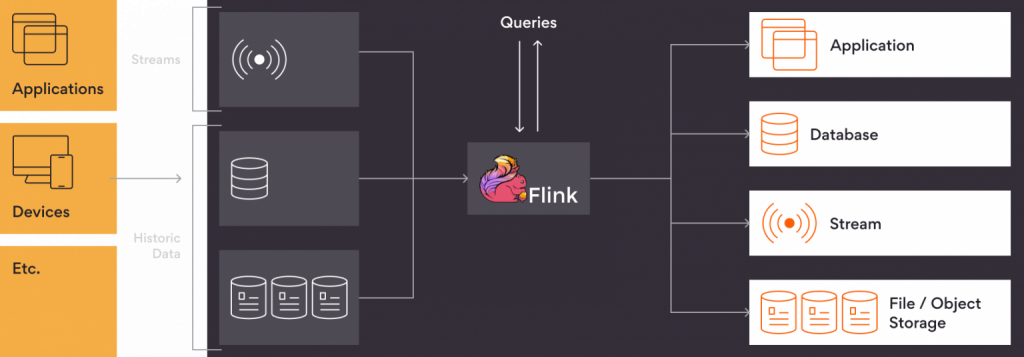
Apache Druid
Apache Druid is a real-time analytics database designed for fast slice-and-dice analytics on large datasets. It’s particularly popular for Online analytical processing (OLAP) applications, providing fast, interactive, and scalable analytics on time series and event-based data. Druid is often used as the backend database for analytical applications Graphical User Interface (GUI) and highly concurrent APIs that require quick aggregations. It’s like a digital warehouse, offering fast data analysis and efficient data storage.
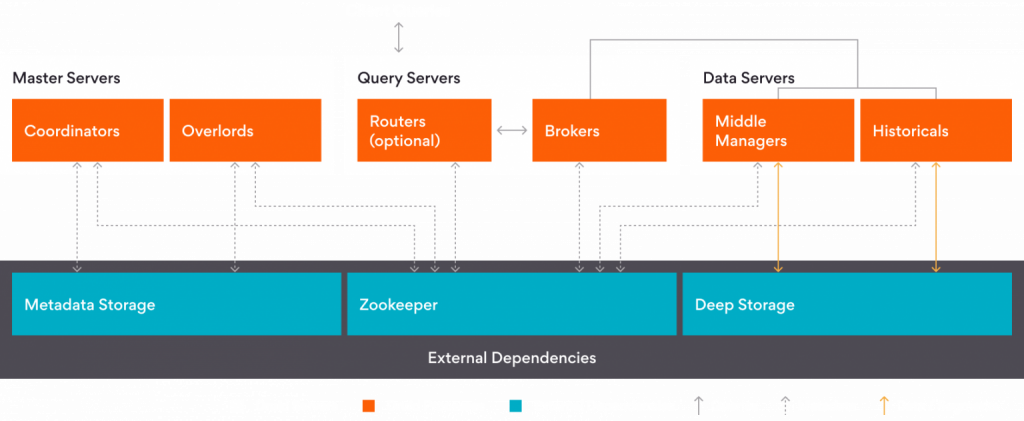
Architectural Overview
The architecture revolves around these three components, ensuring seamless data flow from event producers to Apache Druid for real-time analytics. Event producers can be microservices, IoT devices, legacy systems, SQL databases, and more. The data persists in Kafka, and Apache Flink processes, enriches, and transforms it. Apache Druid acts as an analytical database for querying data with extremely low latency, enabling advanced analytics.
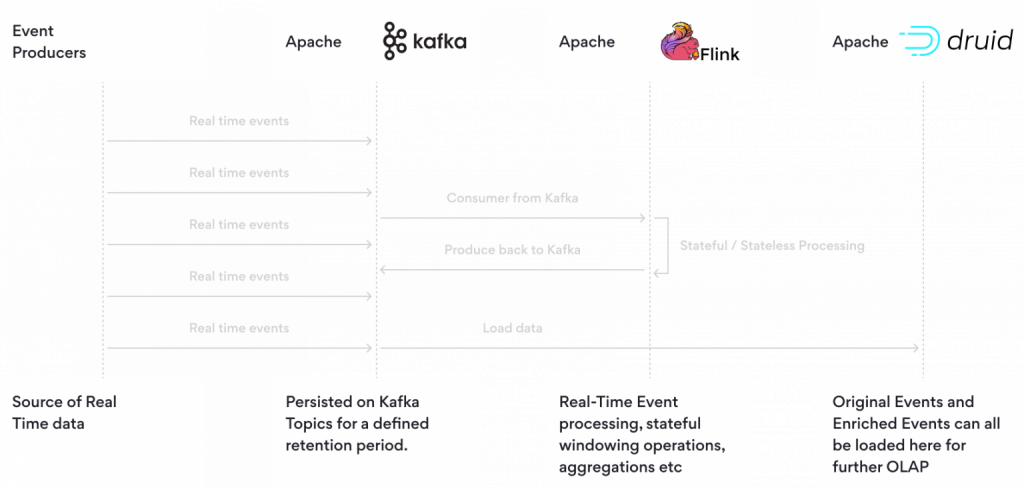
Benefits of Using Apache Flink with Apache Kafka and Apache Druid
In a typical real time and batch oriented workflow, the data teams have to wait for data from multiple sources, waiting for them processing it and then analyzing it. The Kafka,Flink and Driud trio provides a real time data architecture to provide:
Central Hub for Data: Apache Kafka acts as the central hub for collecting and storing real-time data from various sources.
Real-time Data Processing: Apache Flink processes and analyzes real-time data efficiently, supporting complex calculations, transformations, and analytics.
Efficient Data Analysis: Apache Druid is designed for fast analytics on large datasets, providing fast querying capabilities for insights and answers. Collectively, these components create a robust and scalable real-time data processing system.
Challenges
While the combination of Apache Kafka, Apache Flink, and Apache Druid offers powerful capabilities for real-time data processing, several challenges must be addressed:
Integration: Getting these technologies to work together seamlessly.
Complex Configuration: Setting up and configuring the components can be complex and require specialized knowledge.
Scalability: As the system grows, additional resources and partitioning may be needed to maintain performance.
Fault Tolerance: Ensuring the reliability of the system, even in the face of component failures.
Data Accuracy: Implementing monitoring and testing to ensure accurate data processing.
Security: Addressing security concerns with proper authentication, authorization, and compliance measures.
At Persistent, we are among early adopters of Apache Flink, and have been working with many of our clients to meet their needs in this area. Confluent has recently adapted Flink in their cloud native platform and we are a strategic partner of Confluent. We can help you discover, design and implement solutions to take your data processing at next level.
In summary, Apache Kafka, Apache Flink, and Apache Druid offer powerful capabilities for real-time data processing, but they require careful planning and expertise to address integration, configuration, scalability, fault tolerance, data accuracy, and security challenges. Combining these technologies can be challenging, but when done correctly, it unlocks a world of possibilities for stream processing, providing organizations with valuable insights from their streaming data.
Bibliography
- Confluent Inc, “Flink vs Kafka Streams/ksqlDB: Comparing Stream Processing Tools,” 25 September 2023.
- Apache Software Foundation, “Apache Flink,” 25 September 2023.
- Apache Software Foundation, “Apache Druid.”
- Apache Software Foundation, “Apache Kafka.”
- Confluent Inc, “Apache Kafka® Reinvented.”
Author’s Profile















