
Building Generative AI (GenAI) applications has never been easier. Low-code frameworks, hosted LLM APIs, and prebuilt agents have dramatically compressed timelines. You can easily build a simple RAG application with a few lines of code by leveraging some of the new frameworks. But deploying GenAI in production isn’t as simple as spinning up a smart assistant that talks. It’s about ensuring AI trustworthiness — knowing if the assistant is reliable, relevant, safe, and grounded. That’s the real challenge, and the industry is just starting to see the tip of the iceberg.
The RAG Iceberg: What Lies Beneath the Surface
Creating a basic Retrieval-Augmented Generation (RAG) system looks deceptively simple: you ingest documents, chunk and embed them, store those embeddings in a vector database, prompt a large language model to retrieve and generate a response, and deploy. At first glance, the system seems functional, like a polished product demo. But beneath that simplicity lie deeper challenges not discussed in social media demos.
Below the Surface:
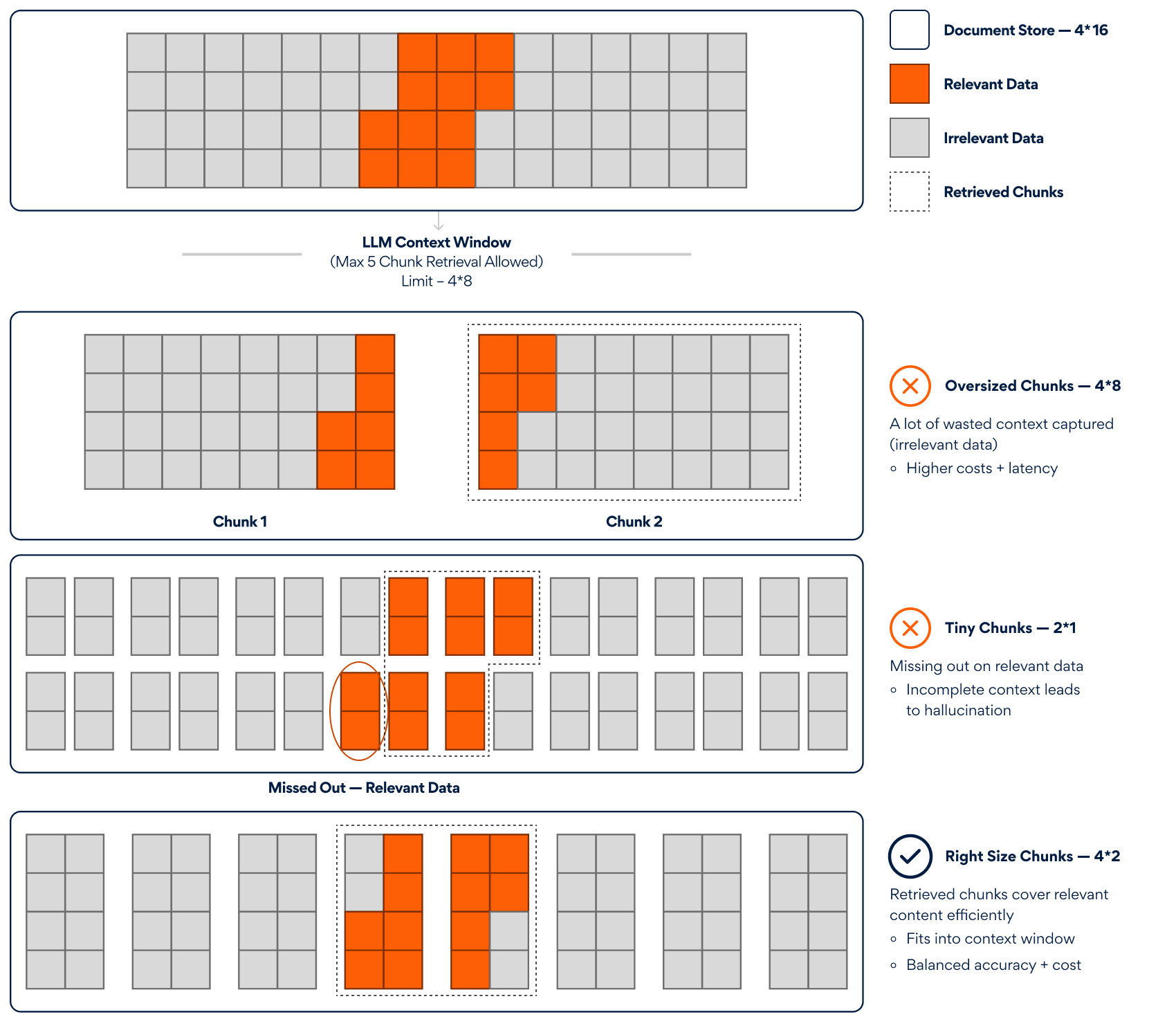
- Retrieval Accuracy: Was the correct document chunk retrieved? Poor chunking logic whether too granular or too broad fragments critical information or muddles response context. Either way, it leads to hallucinations or vague, partial answers.

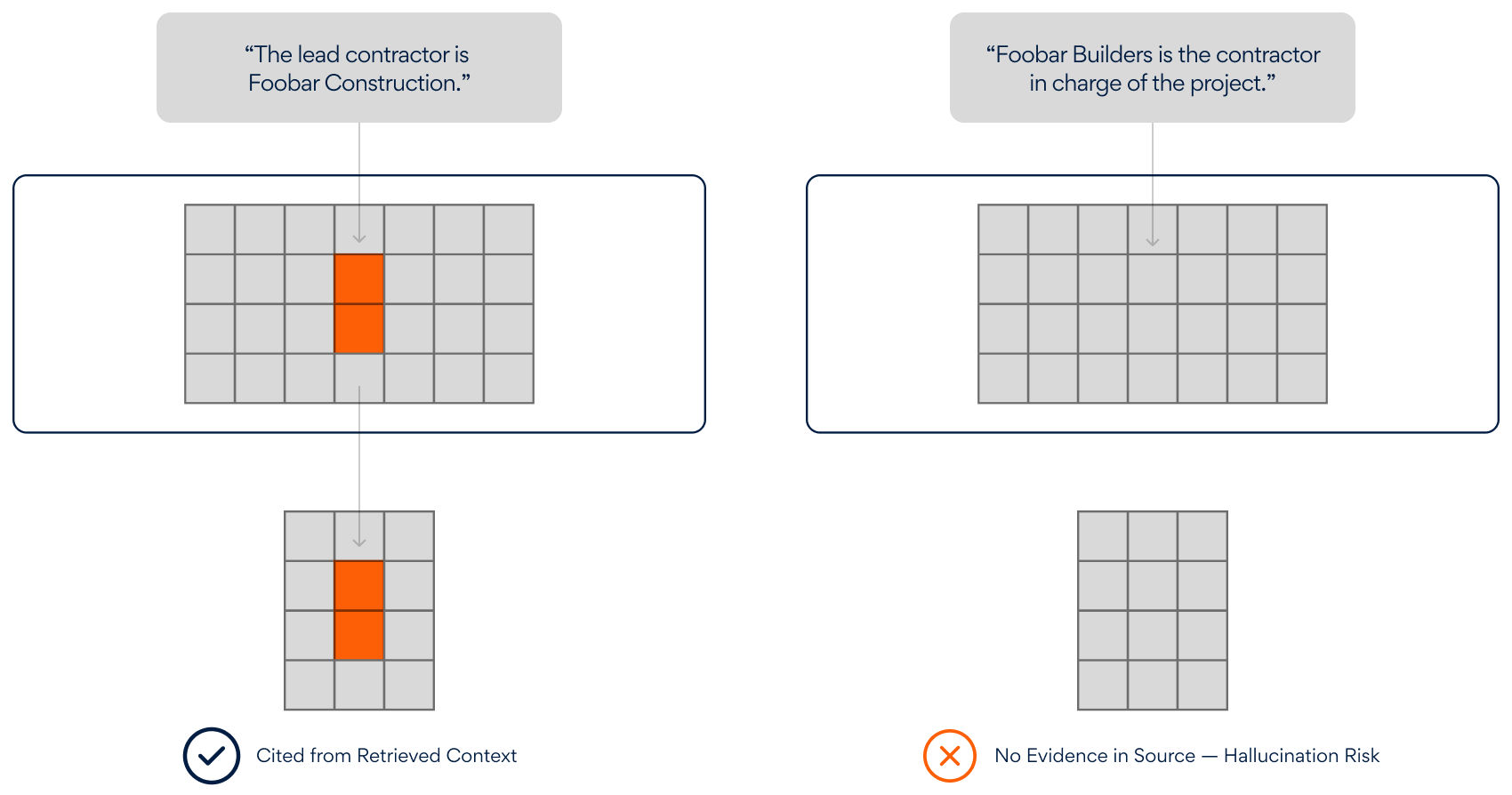
Figure 1: Retrieval Accuracy - Answer Grounding: Is the answer explicitly based on retrieved content or free-floating model knowledge? You can’t verify whether responses utilize your knowledge base without proper citation mechanisms and grounding evaluation
Figure 2: Answer Grounding - Safety and Privacy Risks: Does the system inadvertently reveal sensitive information? Production RAG systems can leak confidential data through incomplete content filtering or clever prompt injection attacks-risks that rarely surface during basic testing.
Figure 3: Safety and Privacy Risks - Stability Over Time: Will the system behave the same tomorrow? Even minor updates like replacing an embedding model or tweaking your chunking strategy can break previously working queries. Without regression evals, you’re flying blind.
- Costing and Efficiency Imbalance: Are you retrieving too many chunks per query or too few? Over-retrieval bloats token usage and spikes API costs, especially with high-tier models, while under-retrieval misses relevant context and degrades quality. Without observability, these trade-offs stay hidden.

Even if you’ve nailed every pre-release check, production introduces a new set of dynamic, evolving challenges that offline tests never cover:
- Content Evolution: Documents get updated, replaced, or added daily. There’s no such thing as a “frozen knowledge base.” What was accurate yesterday might mislead today.
- Unpredictable User Behavior: Real users ask complex questions in ways developers never anticipated, exposing edge cases and creating scenarios untested during development or even during the UAT phase.
- Model Drift: Upgrading your base model or embeddings might silently break grounding, even if you kept your RAG stack unchanged. A new version of a model might tokenize differently, compress context, or reinterpret instructions without warning.
- Input Format Diversity: Structured tables, multi-column text, infographics, and spreadsheets don’t behave the same way in a vector database. New formats enter the pipeline constantly, and not all of them chunk, embed, or retrieve the way you expect.
- User Satisfaction: Without mechanisms like upvote/downvote signals, how do you know if your assistant is helping or hurting? User feedback is the only real signal in production-and most GenAI systems don’t capture it.
Figure 4: The iceberg model illustrates how most teams are still operating at the tip, prototype-level GenAI, while the deeper, critical challenges of production readiness remain largely unaddressed beneath the surface.
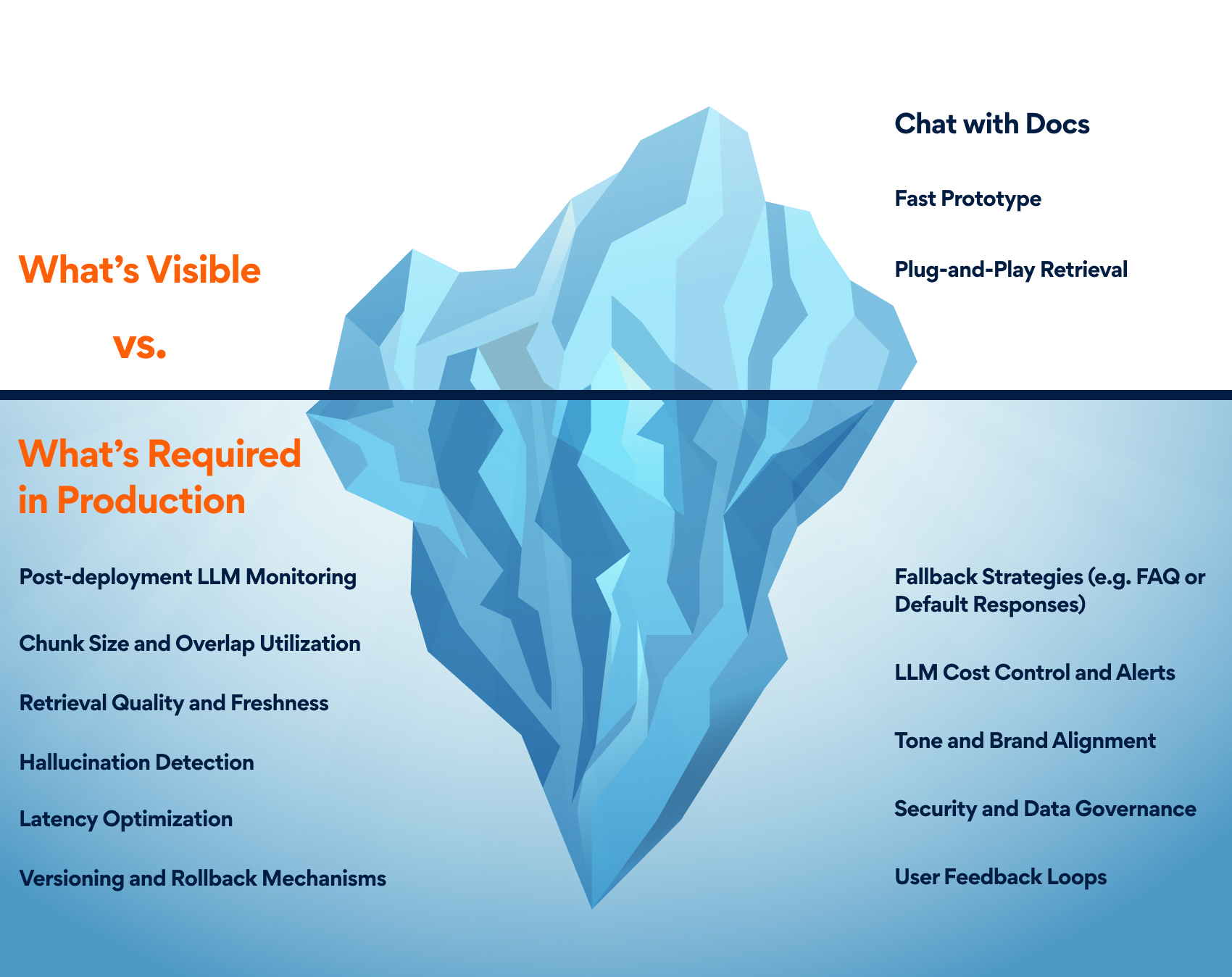
RAG isn’t just a pipeline. It’s a living, evolving system that requires continuous AI performance monitoring and refinement. Without ongoing GenAI evaluation mechanisms including reinforcement from user feedback, it’s not a question of if your RAG system will break in production, but when.
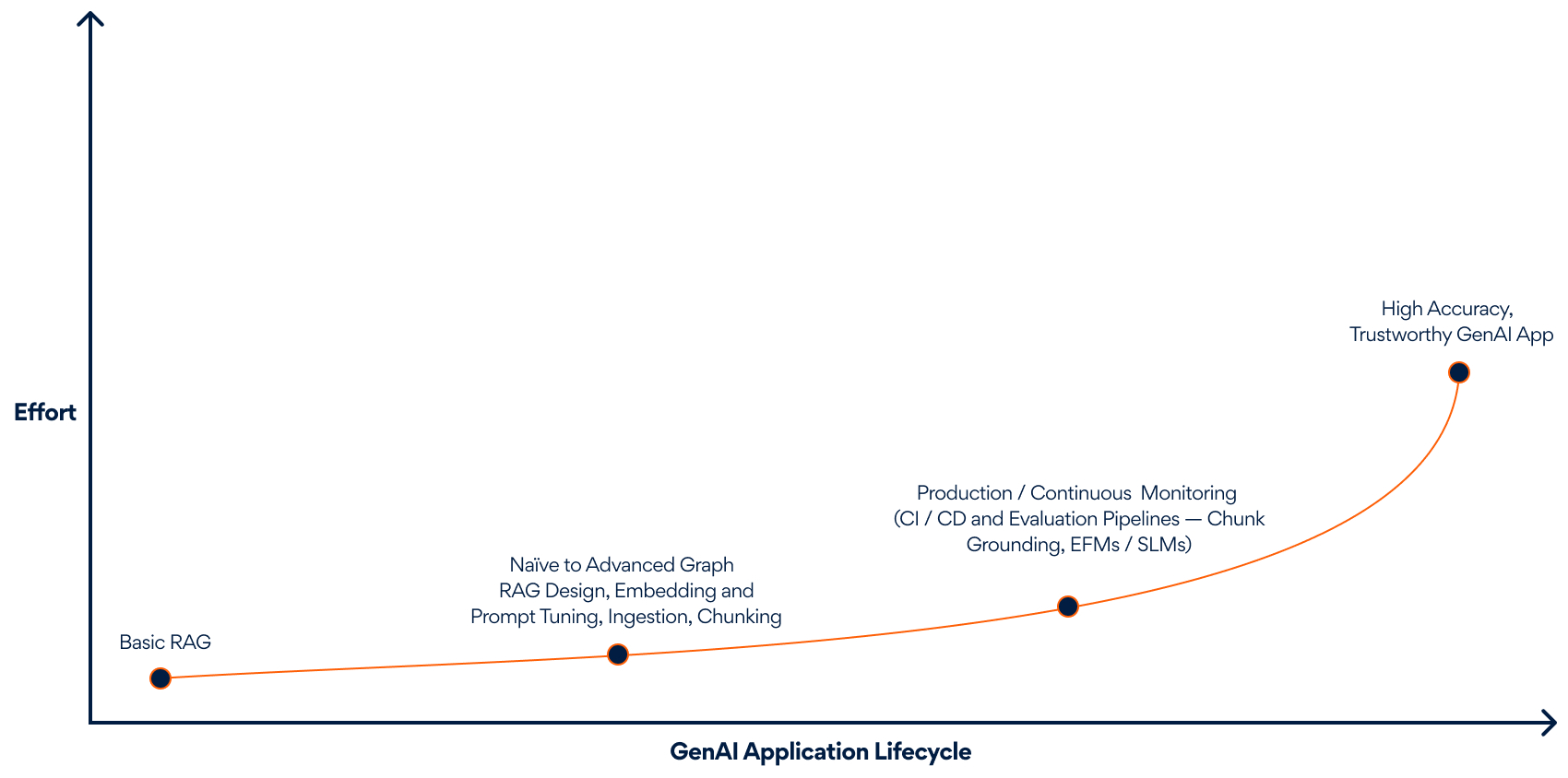
From MVP to Maturity: A Timeline of Effort
Most teams ship a GenAI MVP that works, but the real effort begins after launch.
The GenAI journey starts with code, but maturity demands continuous evaluation, grounding, and monitoring.
Why Evaluation Demands a New Mindset
In traditional software, test cases follow logic. You know what the system should return, and you write tests accordingly. Traditional programming can be auto-tested using traditional programming.
GenAI systems can be auto-tested appropriately using only GenAI systems, but predictability vanishes. Outputs vary with temperature, prompt phrasing, model drift, and context length. There’s no single “correct” answer-just better or worse. So how do you test something inherently non-deterministic? Static test scripts fall flat here. Instead, evaluation becomes dynamic, judgment-based evaluation-powered by LLMs themselves.
LLMs can judge the output of other LLMs-scoring for relevance, tone, and factuality at scale. This approach, known as LLM-as-a-Judge, is increasingly used across the industry.
But general-purpose models were not designed for this job. And that introduces serious pitfalls:
- Nepotism Bias – Models tend to favor responses that align with their own architecture
- Length Bias – Verbose answers often receive better scores, regardless of accuracy
- Prompt Sensitivity – Slight changes in phrasing can lead to inconsistent evaluations
- Frequency Blindness – Standard tools don’t account for how often you evaluate or when to trigger it
The problem isn’t with GenAI, it’s with using tools never designed for evaluation. What’s needed are models fine-tuned specifically for trust, safety, and performance monitoring.
That’s why Persistent partners with organizations like Galileo, whose Luna™ Evaluation Suite includes fine-tuned Evaluation Foundation Models (EFMs) purpose-built to:
- Detect hallucinations, privacy leaks, and unsafe completions
- Verify retrieval grounding and chunk attribution
- Support agentic workflows and multi-turn reasoning
- Evaluate continuously streamed or batch-with cost-efficiency in mind
These EFMs aren’t just LLMs, they’re LLMs trained to trust, audit, and assess. They’re designed to ensure the reliability of your AI systems and agents.
Every evaluation system involves a set of trade-offs that must be carefully managed. For instance, there is often a balance between granularity and cost—more detailed scoring typically requires additional tokens, increasing computational expense. Similarly, there’s a trade-off between latency and accuracy, as real-time scoring can introduce delays that slow down inference performance. Finally, teams must weigh coverage against focus; attempting to evaluate everything may not be the most efficient approach and can dilute attention from the most critical elements.
One of the most overlooked aspects of deploying generative AI in production is the frequency and timing of evaluation. Key questions arise: How often should models be evaluated? Should assessments be triggered after a certain number of API calls? And should evaluation occur post-deployment in batches, or happen in real time? These considerations are central to maintaining model performance, reliability, and safety—but they often operate behind the scenes, forming the invisible backbone of successful GenAI systems.
At Persistent, we treat evaluation not as a checkbox, but as a continuous function baked into the GenAI development lifecycle. Not just RAG, but RAG you can rely on. Not just agents, but agents you can audit. Not just LLMs, but LLMs that understand how to judge.
If we want to deploy GenAI into regulated, high-trust, and mission-critical environments, we need to move from demos to dependability. While building GenAI systems may now take days, earning trust takes a system.














