
At 2:07 a.m., the first alarm wasn’t the dashboard it was the checkout funnel. p95 latency climbed from 120 milliseconds to 2.4 seconds, retries surged and the error budget started bleeding in real time. The ITSM console did what it has always done: it lit up. Alerts created incidents, incidents spawned tasks, tasks triggered escalations. A well-trained on-call engineer stared at a familiar pattern until it wasn’t familiar anymore. The runbook assumed a single failing dependency. This time, it was a cascading interaction across a microservice mesh, a recently rotated certificate and a configuration change pushed twelve minutes earlier. The system was moving faster than the humans inside it.
For two decades, ITSM platforms served as the operational “nervous system.” They normalized requests, routed work, enforced approvals and preserved an audit trail. But their intelligence remained largely human. Even with automation scripts and orchestration, most enterprises still run a people-heavy loop: humans interpret noisy signals, hunt for context across tools, decide a course of action and then execute. That model worked when environments were simpler. With hybrid cloud and distributed microservices, this nervous system gets overwhelmed because the next failure mode rarely matches the last.
The ITSM lesson is direct: if humans remain the default “control loop” for incident triage, diagnosis and remediation, reliability will scale only as fast as attention. And attention does not scale.
Plugging the Gap: Not More Automation, More Agents
An agentic ITSM model redesigns the control loop. A Case Resolution Agent becomes the first responder: it clusters alerts into a single incident, pulls service topology and ownership from the CMDB and estimates business impact. A Knowledge Agent retrieves relevant runbooks, past incidents and known-error patterns, grounding recommendations in the organization’s own operational memory. A Case Analyzer correlates telemetry, such as metrics, logs and traces (for example, by grouping failures on traceId and linking them to the last deployment or configuration diff) and ranks likely causes. Finally, an Action Agent executes remediation through approved toolchains (CI/CD, Kubernetes, feature flags, infrastructure APIs), but only within explicit guardrails, with reversibility and verification built in.
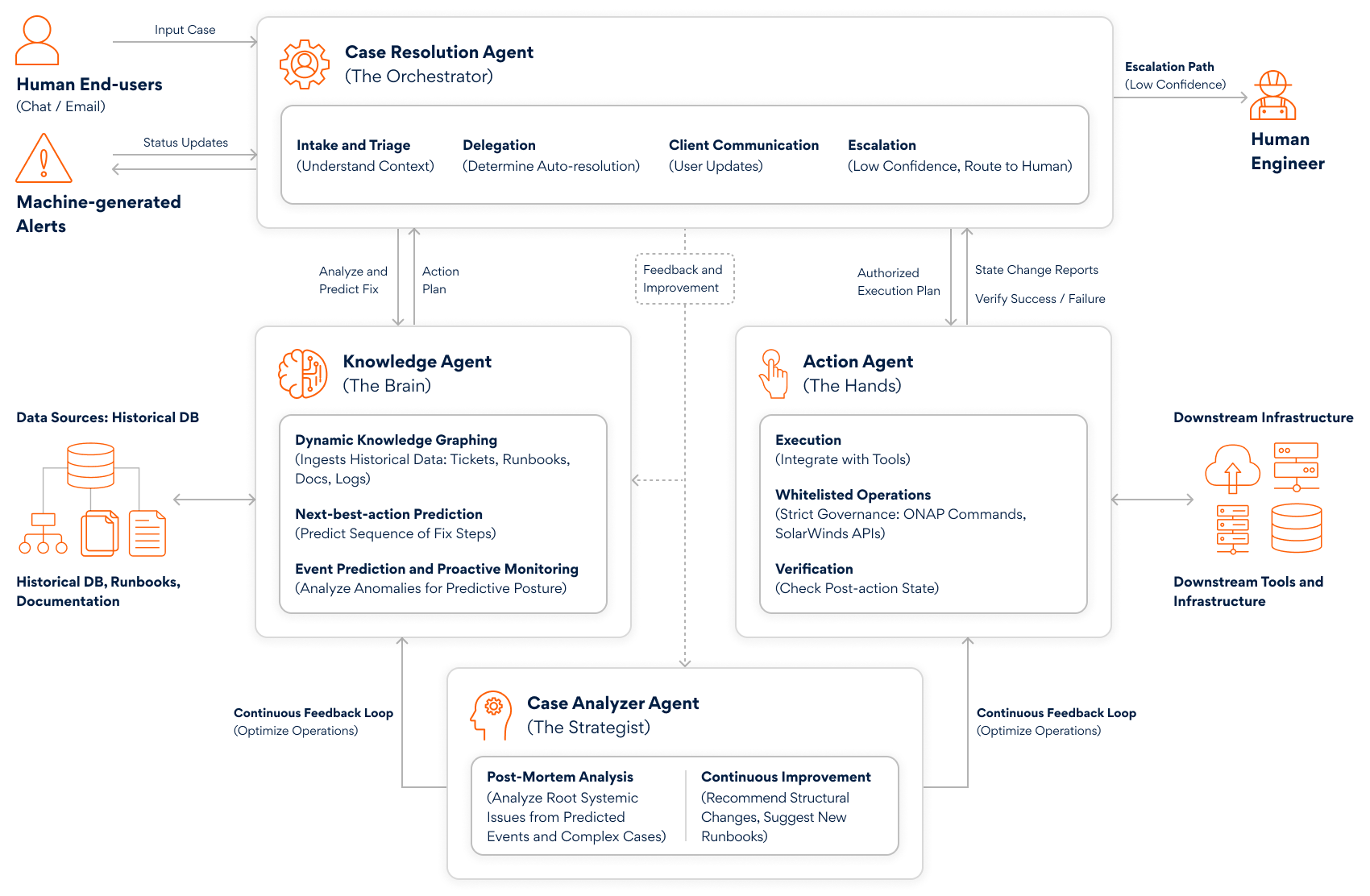
Back at 2:07 a.m., that difference looks like this: the agent sees the latency spike, ties it to a subset of pods after a config push and proposes three safe moves: traffic shift, config revert, rollback, each with expected metrics to validate success. It checks policy (change window, required approvals and what actions are permitted without human sign-off), executes the lowest-risk reversible change and watches p95 and 5xx return to baseline before closing the loop.
The outcome isn’t just a faster fix; it’s a different cost curve. Research suggests that agentic AI can reduce L1 support ticket volumes by up to 90% and deliver annual savings of $250 to $ 1,200 per employee.
Why push for this now? Because AI is not a side feature; it is an economic and operating-model lever. Reliability and change velocity sit right in the middle of that value pool. When incidents consume senior engineer time, every other transformation slows down: cloud migration stalls, product roadmaps slip and security backlogs grow.
Architectural Groundwork
But autonomy is earned, not installed. Before agents can resolve tickets, they need:
- High-fidelity signals: Standardized telemetry (logs, metrics, traces) with consistent service tags, SLOs and a clear definition of “healthy”
- Enterprise context: A trustworthy CMDB/service graph that reflects real dependencies, ownership and business criticality, because an AI that can’t see blast radius can’t act safely
- Integration fabric: Event pipelines to ingest alerts and secure connectors to the tools that change reality (CI/CD, Kubernetes, cloud APIs, feature flags, identity platforms)
- Governance as code: Explicit policies that define what actions are allowed, when approvals are required, how rollbacks work, what must be logged and when to escalate to humans
- LLMOps discipline: Evaluation harnesses for accuracy and safety, prompt/version control, red-teaming and runtime monitoring so the system improves without becoming unpredictable
A pragmatic rollout follows a crawl–walk–run pattern. Start with agentic assist: the Case Resolution Agent de-duplicates alerts, drafts the incident narrative, recommends owners and retrieves the most relevant runbooks, with humans still executing.
Move to agentic execute in low-risk domains, where predefined, reversible actions (restart, scale, cache flush, config revert) are taken with automated verification against SLO signals.
Then expand to agentic change, where the agent can open, justify and implement a controlled change (with approvals) to permanently remove recurring causes, effectively turning incident response into continuous improvement.
Over time, the ITSM metrics shift from tickets closed to incidents prevented, autonomous resolution rate, MTTR for top services and reduction in alert noise and cognitive load.
Strategic Partners as Catalysts
Strategic partners like Persistent can shorten the path from concept to production by delivering the foundations and engineering rigor required for safe autonomy, across ServiceNow-led ITSM/ITOM design, enterprise integrations, platform engineering and governed AI agent delivery.
With deep platform engineering expertise, Persistent helps convert fragmented operational data and tooling into a reliable control plane for agents. This includes standardizing observability (logging/metrics/tracing conventions, service tagging, golden signals), defining and instrumenting SLOs that agents can use as success criteria and normalizing monitoring/APM events into consistent incident signals. Persistent also strengthens the “truth layer” by reconciling CMDB data with runtime discovery and service mapping, so dependency graphs reflect reality. Finally, Persistent builds secure API and event-driven integrations between ITSM and execution platforms (CI/CD, Kubernetes, cloud, identity, feature flags) and implements bounded, testable runbook automation with approvals, rollbacks and audit trails, so agents can act safely and measurably in production.
With home-grown accelerators and IP to govern the technical foundations for agentic ITSM, Persistent helps set the ball rolling:
- Persistent Intelligent Cloud Service Management (PiCSM)on ServiceNow is a plug‑and‑play ServiceNow ITSM foundation (prebuilt processes, data model, workflows, dashboards and common integrations) that accelerates standardization, useful when agentic capabilities need a clean, consistent system of record
- Persistent GenAI Hub is an enterprise platform for building and running GenAI/agentic apps, with a Trust Layer (security/guardrails), an Evaluation Framework and FinOps-style cost visibility, helping with governed agent deployment and ongoing monitoring
- Agent Studio (on GenAI Hub) is a no-code agent builder/orchestration layer for SMEs, with reusable tools/APIs and MCP integration, plus ROI/outcome tracking; useful for operationalizing multi-agent workflows for triage, diagnosis and remediation without heavy custom engineering
- Ops(AI)Pilot is an agentic AIOps capability positioned for cross‑tool operations (vendor‑agnostic), moving from “fixing” to “preventing” via predictive analytics and automated RCA/auto‑resolution; relevant to reduce alert noise and accelerate MTTD/MTTR in hybrid environments
- Now Assist Enablement accelerators are packaged patterns around ServiceNow Now Assist (summarization, generative search and custom skills via Now Assist Skill Kit) that can improve knowledge capture, ticket quality and analyst productivity; often the quickest “crawl” step before bounded autonomy
The next time checkout latency spikes at 2:07 a.m., the most valuable outcome is not a heroic recovery, it’s a quiet one. Agentic ITSM turns operations from a manual, attention-limited process into a governed, continuously learning system with faster reflexes than the systems it protects.
The choice is strategic: either accept a reliability ceiling defined by human bandwidth or invest in the architectural foundations that let software run itself, under enterprise rules, with audit trail and humans focused on what only humans can do.
Author’s Profile

Dilip Peswani
Principal Consultant, Persistent Systems

Dattaraj Rao
Senior Vice President – Corporate CTO Organization, Persistent Systems














