In our previous blog, we introduced you to MANAV: The Human Atlas initiative, a scalable platform for the curation of scientific literature. As MANAV’s technology partner, Persistent Systems has built a robust platform with innovative methodologies for structured and comprehensive knowledge base creation.
The MANAV project uses a hybrid annotation approach in which it generates system curated Knowledge Graphs (KGs). While the automated process can curate scientific articles faster, the outcomes require manual review to minimize errors without losing important scientific information. However, to review/curate the massive number of research articles (KGs), MANAV needs a large number of scientifically skilled manpower. Therefore, upskilling the students (graduate/post-graduate) is one of the major objectives of the MANAV project. The automated evaluation of student-curated KGs plays a crucial role in this entire upskilling pipeline. Read this blog to get a detailed insight on the automated evaluation approach of student-curated KGs.
Challenges with Manual Data Curation
Currently, curation of scientific literature has become a popular approach to source valuable information out of the corpus available in the public databases. This collective information is used to generate new insights, validate work and simulate hypotheses without spending much time and effort on experiments.
However, curation quality, in terms of accuracy and integrity, is of prime importance in order to get confidence on the data. In case of manual curation, the quality is directly proportionate to the knowledge and expertise levels of the curators. Therefore, it is essential to evaluate curators’ skill through review.
What is Knowledge Graph?
A Knowledge Graph is the network representation of entities illustrating the semantic relationship between them. Knowledge Graphs are widely used to capture the structured form (and context) of the curated data. While manual evaluation of any curation is exhaustive and highly time consuming, KG provides us a way to perform it faster computationally.
Decoding the Structure of Knowledge Graphs
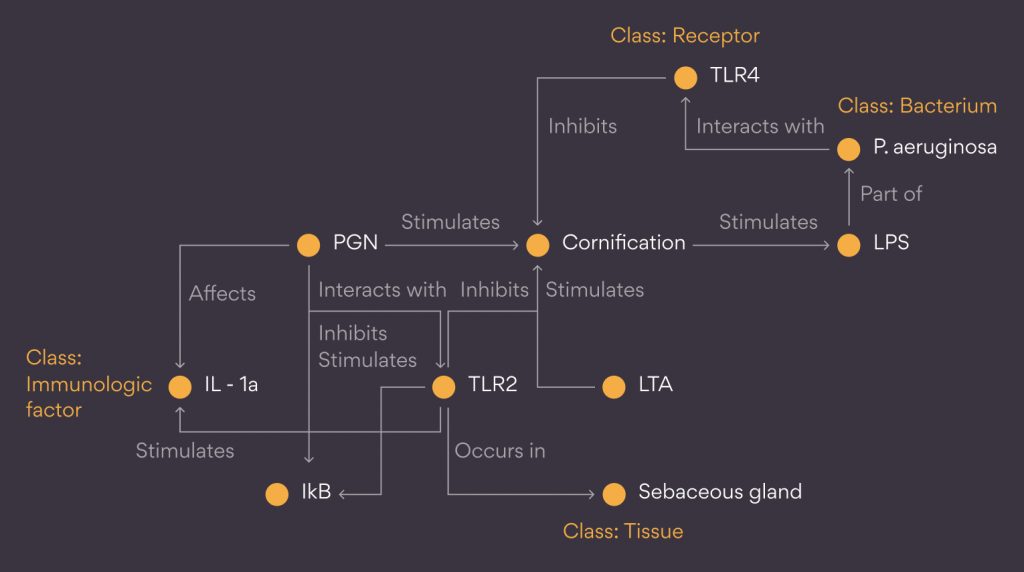
In the manual curation approach (developed on the MANAV Platform), the scientific research articles are curated sentence by sentence, basically by capturing the following critical components:
- Entity1 (e.g., P. aeruginosa)
- EntityClass1 (e.g., bacterium)
- Relation (e.g., interacts_with)
- Entity2 (e.g., TLR4)
- EntityClass2 (e.g., receptor)
Out of these components, the following are:
- Selectable from the pre-loaded list – EntityClass1, Relation and EntityClass2
- Need to be captured from the actual article text – Entity1 and Entity2
To help the reader understand better, here’s a graphical representation depicting the structure (a portion) of a Knowledge Graph.
Our Evaluation Methodology
The evaluation of manually curated Knowledge Graphs is quite subjective and may vary based on the source of the articles. To standardize the evaluation, we have developed a methodology to evaluate manually curated KGs, with the help of our in-house designed algorithm.
To define a standard of measurement, we follow the concept where the samples are compared to the Gold Standard. With the help of the domain experts, several full-text articles are curated to generate Gold Standard Knowledge Graphs.
A curator, whose curation needs to be evaluated, is assigned article(s) to perform manual, curation using the specially designed MANAV platform. The curated Knowledge Graphs are then compared to their respective Gold Standard Knowledge Graphs to generate scores.
Gold Standard KGs v/s Curated KGs – Key Parameters for Comparison
First, we have identified a set of key parameters that are logical, feasible to compute and comparable between two Knowledge Graphs. Following are the 4 key parameters for comparison:
1. Overall Network Similarity: To estimate the overall similarity between the Gold Standard KG and curator’s KG, we have computed the overlap of these two network graphs.
The Jaccard’s Similarity Index is calculated (Gold v/s curator) separately for the nodes (entities) and the edges (relations) and they are later combined. Please note, as the KGs are directed graphs, we must take care of the direction of the edges while comparing.
2. Capturing Important Entities: The ability to identify important entities is considered as a significant skill of the curator. First, we must mark the important entities in the Gold Standard KG.
To process it computationally, we calculate topological parameters (degree centrality, eigenvector centrality and closeness centrality) of each node of the Gold Standard KG. Further, we perform multivariate k-means clustering (k=2). We then tag the cluster with higher centroids and consider those nodes as important.
Finally, we compare how many nodes (entities), marked as ‘important’ in the Gold Standard KG, have been captured in the curator’s KG.
3. Identifying Correct Entity Class: Entity class helps to classify the entities in a systematic manner. Therefore, the understanding of correct class mapping is an essential curator skill. Please note, it is possible that one entity falls under more than one class. For example, TLR2 can fall under two classes ‘receptor’ as well as ‘protein’ depending on the context.
First, individual entities, present in both the KGs, are picked and their classes are listed down. Then, a similarity index is calculated considering the commonality in between the two sets of classes (Gold & curator) for that entity.
This process gets repeated for all the entities present in both the Knowledge Graphs. Finally, the average of their similarity index is considered as the output score.
4. Capturing Important Relations: Like important entities, capturing important edges with relations is also essential to present a Knowledge Graph accurately. The important edges are defined as the link between two key entities in the Gold Standard KG.
While comparing the edges with the curator KG, three key features – connectivity, relation and direction are taken into consideration. Finally, we compare how many such important edges have been captured in the curator’s KG.
Collating the Final Score: All the 4 scores (mentioned above) are combined for evaluation through one single metric that ranges from 0 to 5, where 0 is the lowest and 5 is the highest in terms of accuracy. This metric reflects the overall performance of a curator on a single article (Knowledge Graph).
Enterprise Knowledge Graph Curation & Evaluation Solutions
Our designed approach can not only to be used for evaluating curators’ skills, but also to perform a systematic review or quality check on curated KGs. With fine tuning, this algorithm is also able to perform a structural analysis on any type of curated Knowledge Graphs for enterprises.
At Persistent, we have an expertise in Knowledge Graph-based solutions for the Health Care & Life Sciences industry. We design & develop customized KG curation & evaluation platforms and methodologies to ensure your enterprise makes highly accurate data-driven decisions. To learn more about Persistent’s comprehensive Life Sciences Innovation & Engineering solutions, connect with us.














