Building Reliable AI Systems with Guardrails: Part 2 – Implementation Guide
Blog by Shivam Gupta, Abdul Aziz Barkat, posted on August 29, 2025 in Persistent.AI
Introduction
Previously, we explored the theoretical foundations of guardrails and their importance in ensuring AI systems operate safely and effectively. We now take a practical approach, walking through the AI implementation process with code examples and best practices.
Using the guardrails.ai framework, we will demonstrate how to take guardrails from concept to reality, providing actionable steps to enhance the reliability, safety, and compliance of AI applications. These techniques can be used to establish robust boundaries for AI systems while maintaining functionality and performance.
Overview of the Guardrails Implementation Process
Implementing Guardrails involves a structured approach:
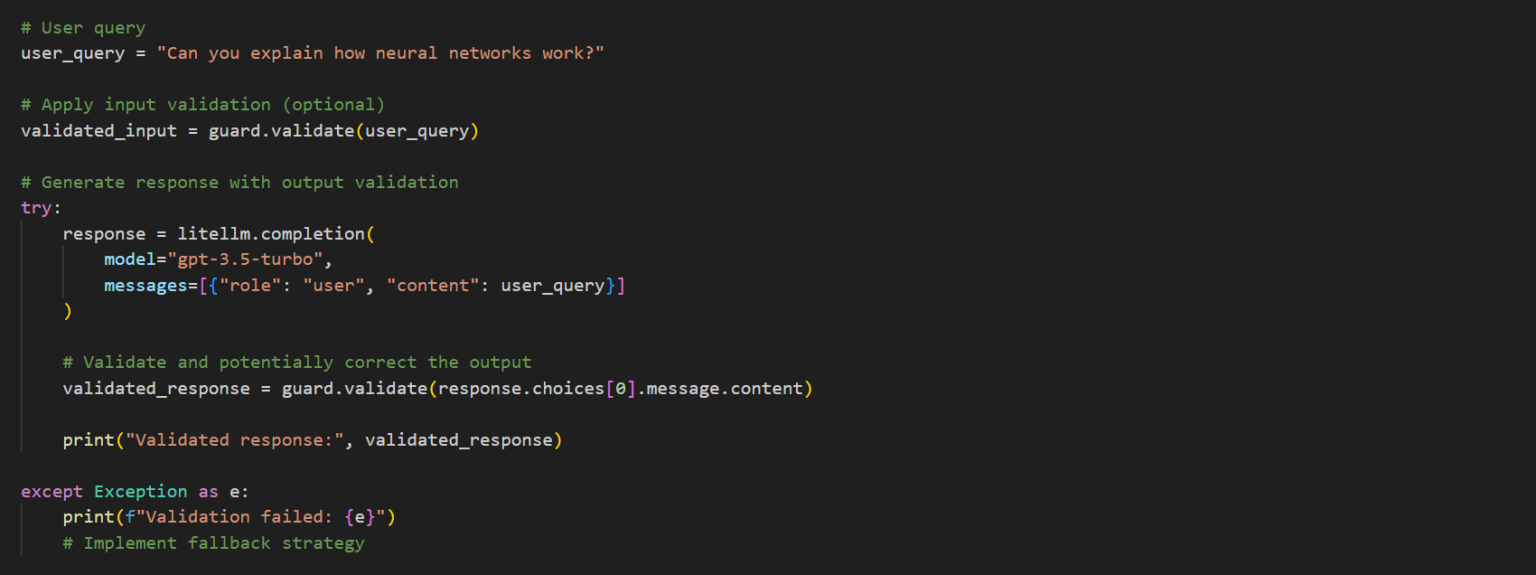
Step 1: Setting Up Your Environment
Before implementing guardrails, install the required packages. The guardrails.ai framework provides a flexible foundation that works with popular LLM interfaces, such as LiteLLM, Langchain, and direct API calls to providers like OpenAI.
Installing Required Packages
To get started, install the core guardrails package and any validators you’ll need:
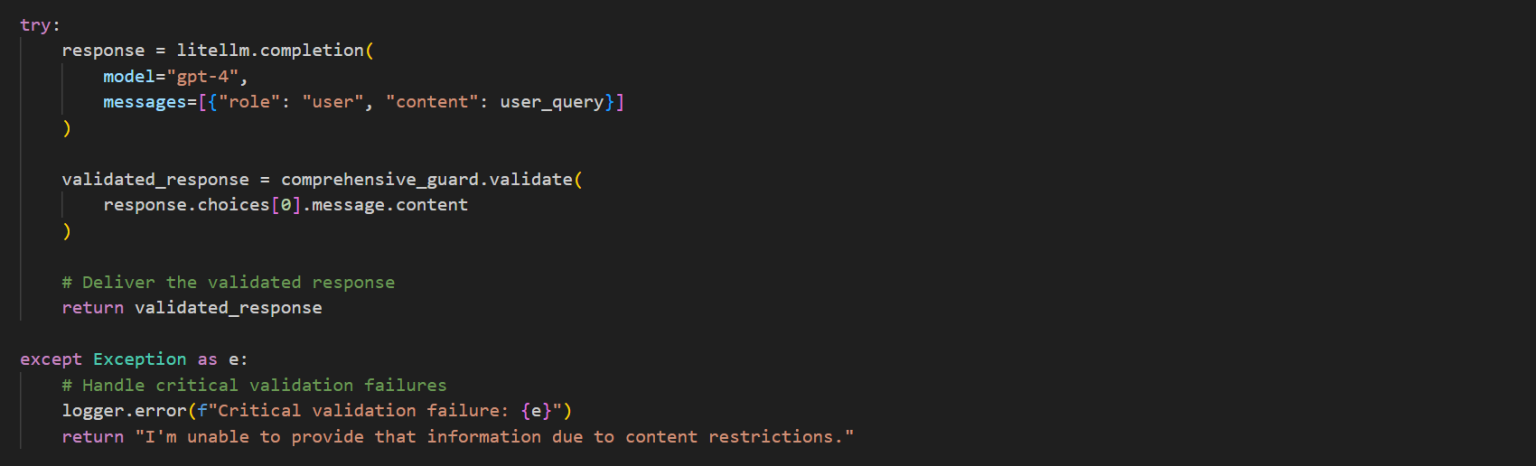
Provides final safety checks before delivery to users
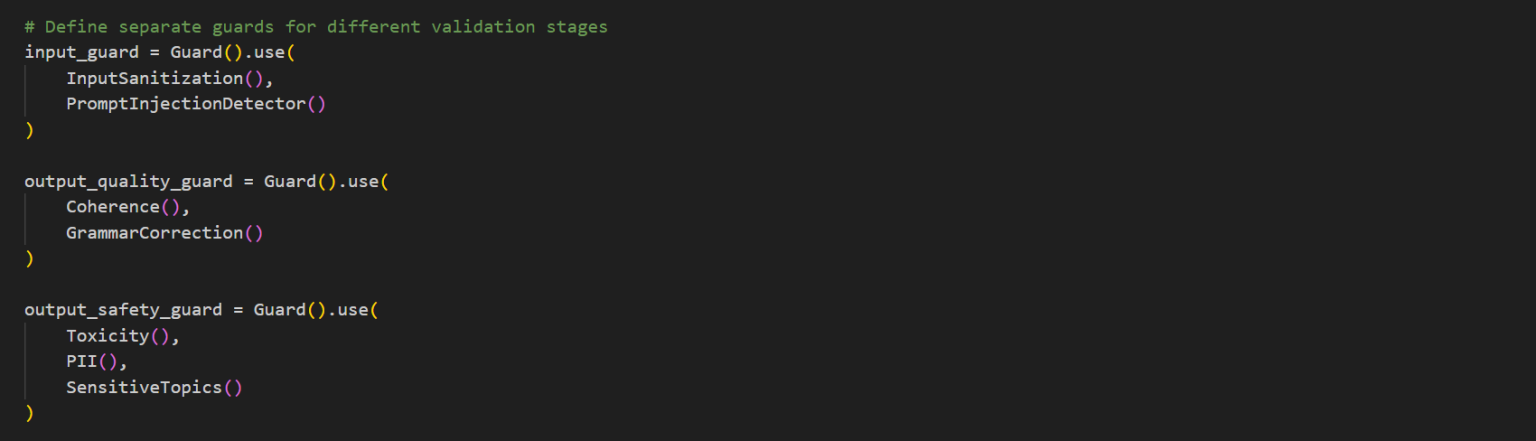
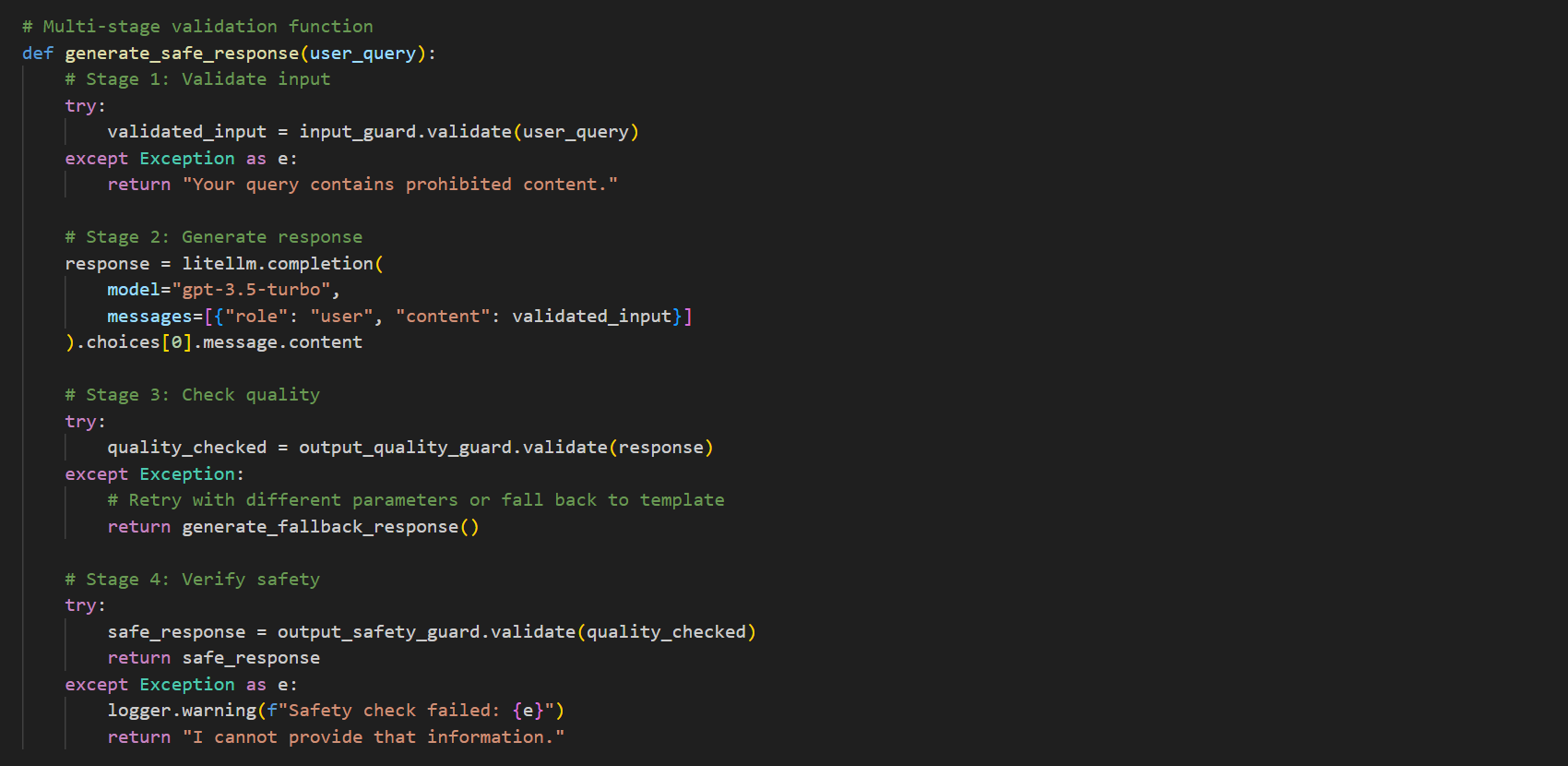
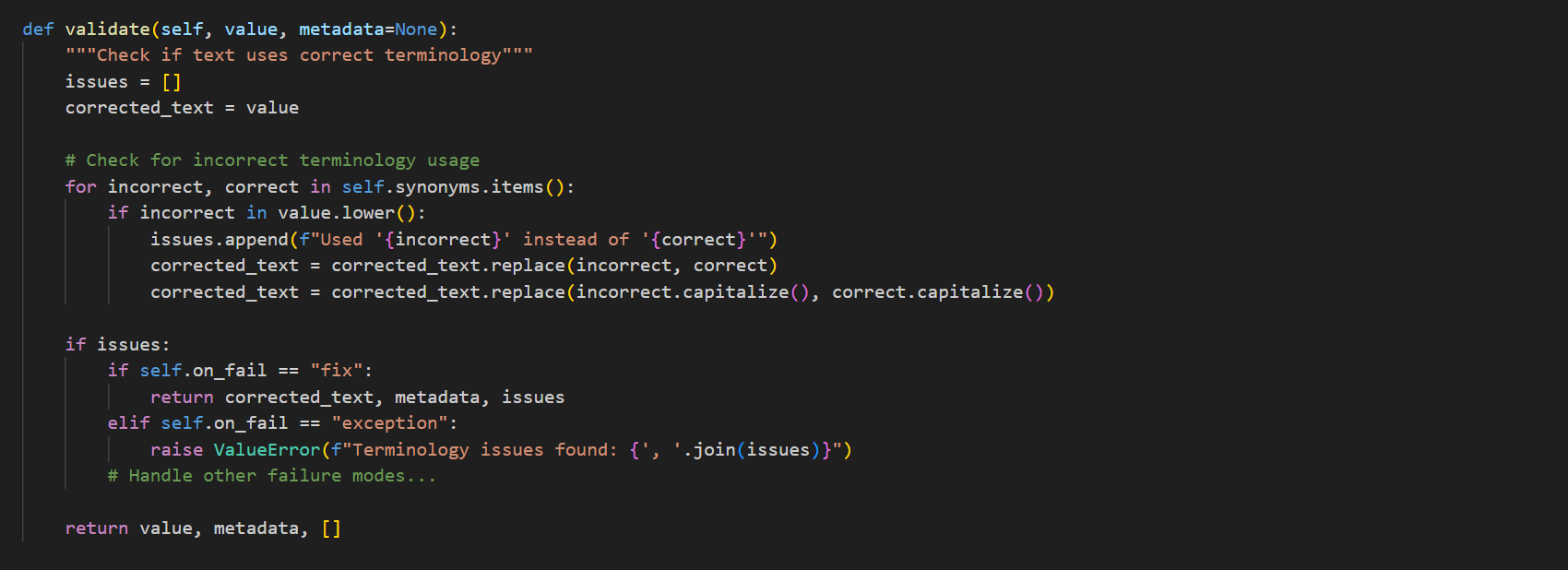
Creating Custom Validators For domain-specific requirements, you can easily create custom validators:
Fig9. Custom Validators – Creating Custom Validator (Source: Persistent)Fig10. Custom Validators – Defining Validation rule (Source: Persistent)Fig11. Custom Validators – Validation (Source: Persistent)
Custom validators enable you to enforce organization-specific standards, industry requirements, or specialized knowledge domains.
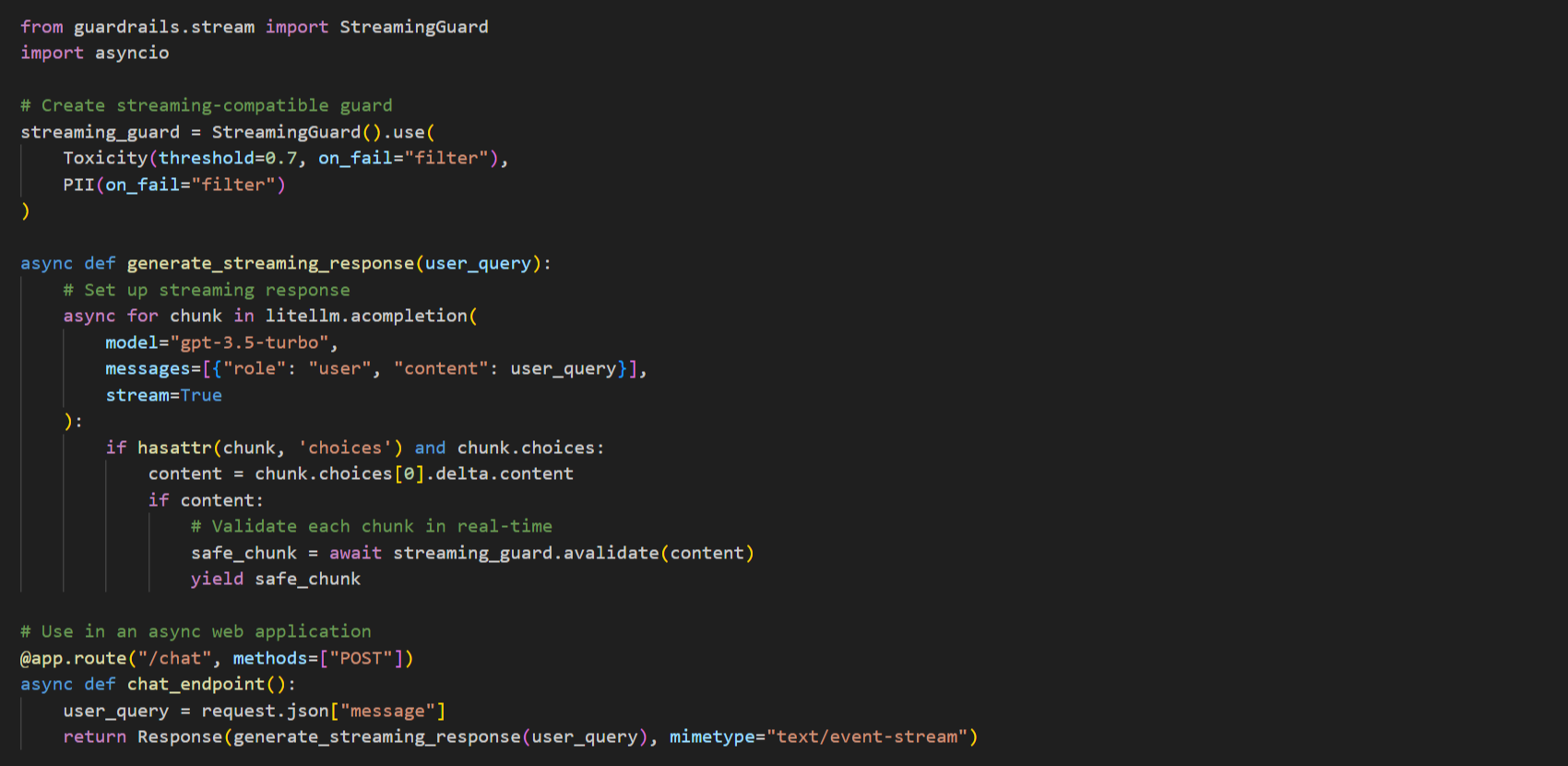
Implementing Streaming Validation for Real-Time Applications For chat applications or other real-time interfaces, streaming validation is essential: Fig12. Streaming Validation (Source: Persistent)
Streaming validation ensures each token is checked as it’s generated, maintaining low latency while still enforcing safety guardrails.
Beyond these implementations, organizations often need to optimize performance and strengthen AI risk management as their AI applications scale. This typically involves caching validation results, using tiered validation approaches, and implementing robust monitoring systems. Additionally, as AI systems handle more requests, proper observability becomes critical for detecting emerging issues and maintaining system reliability.
Conclusion
Implementing guardrails transforms AI systems from potentially unpredictable tools into reliable, trustworthy solutions. Effective implementation requires systematic validation, strategic handling of failures, and multi-layered protections tailored to specific domains and use cases. For instance, in collaboration with a financial services company, we successfully implemented robust guardrails through our GenAI Hub product. This included validators such as PII detection, topic restriction, and regex-based filtering. These measures not only ensured compliance with industry standards but also enhanced the reliability and security of their AI systems, enabling them to confidently leverage AI for critical business operations. By following the patterns outlined in this guide, organizations can responsibly deploy AI while effectively managing AI security risks. As LLM technology evolves, those who invest in robust guardrails today will be well-positioned to meet tomorrow’s standards for safe, reliable AI.
Authors’ Profile
Shivam Gupta
Software Engineer, Corporate CTO Organization BU
Shivam Gupta, an IIT BHU Varanasi graduate, is part of the Generative AI team within Persistent’s Corporate CTO R&D organization. He contributes to the design and development of practical AI solutions, supporting research-driven initiatives and helping integrate emerging technologies into real-world applications.
Abdul Aziz Barkat
Lead Software Engineer, Corporate CTO Organization BU
Abdul Aziz Barkat is part of the Generative AI team within Persistent’s Corporate CTO R&D organization, where he focuses on the development of innovative solutions.