
There are two key ingredients for a successful data lake implementation. The first, obvious one, is to ingest (all) the data relevant to the business process the lake will be supporting, and to secure and govern it based on the organization’s policies. The second is to explore this data, using a set of tools and guidelines, to discover actionable insights to get real business benefits.
In our very first post in this series, my colleague Avadhoot introduced the roles of Data Producers and Data Consumers in an organization, talked about the mismatch between the need of data producers for control and that of data consumers for flexibility, and positioned the notion of a Data Lake as a means to satisfy the needs of both roles. In the other prior posts in this series, we talked about Flexible Data Ingestion, Data Security and Data Governance, all of these mainly dealing with the needs of Data Producers.
What Data Consumers are looking for is a quick and effective way to explore the vast amount of data lying in the Data Lake. Mataprasad in his blog talked about metadata tagging to support dataset discovery, a step preceding data exploration. In this blog, I talk about the need for Data Exploration, what Data Consumers expect from Data Lake in terms of Data Exploration and how do you go about implementing the same.
With this context in mind, let’s dive (we like our metaphors!) into the details, starting with the need for data exploration.
Back in 2009 when I started my Big Data journey, organizations were trying to solve specific business use-cases. The key objectives were to manage ever-increasing amounts of multi-structured data, to reduce cost and to extract insights improving the business outcome. In many cases, there were multiple Big Data deployments in the organization focused on their individual and specific needs. Data sharing across the units was minimal. Even technology (e.g. Apache Hadoop) was not ready to support Data Producers’ needs at that time. In this setup, the datasets were typically few and, mostly, well known to the Data Consumers who were working with this data, and for the same reason, exploration needs were not that critical.
Today, organizations understand that in order to remain competitive in the market and serve their customer well, they need to analyze each and every possible event that might impact the relationship (both positively as well as negatively) with their current and their target customers. This obviously requires access to all sorts of data in one place for deeper analysis.
As discussed in our prior posts in this series, Data Producers are now comfortable sharing their data with other users within the organization – now it is possible to get all this data in one place – in a Data Lake. But does it solve all the problems? The key challenge is how to enable different kinds of users (programmers, data scientists, and business users) to explore and consume this vast amount of data the way they want. Many times, consumers of the Data Lake are not even aware of what data exists in it and what problem it can help solve. There are times when exploration results in new use cases being identified. In this scenario, Data Exploration becomes more critical.
Let’s now look at the key features the data exploration component needs to provide to satisfy consumers’ needs and help them extract some real insights from the vast amount of data stored in Data Lake.
In the last couple of years, I’ve had the opportunity to interact with many organizations to discuss their Data Lake strategy. We now have the collective experience of successfully setting up Data Lakes in multiple organizations. Based on these interactions and with the experience gained through the usage of these real deployments, we believe that for a Data Lake to be successful, Data Exploration needs to provide the following key features:
-
- Flexible Access -The mind-map below introduces the main topics to consider for Flexible Access from the Data Exploration point of view:
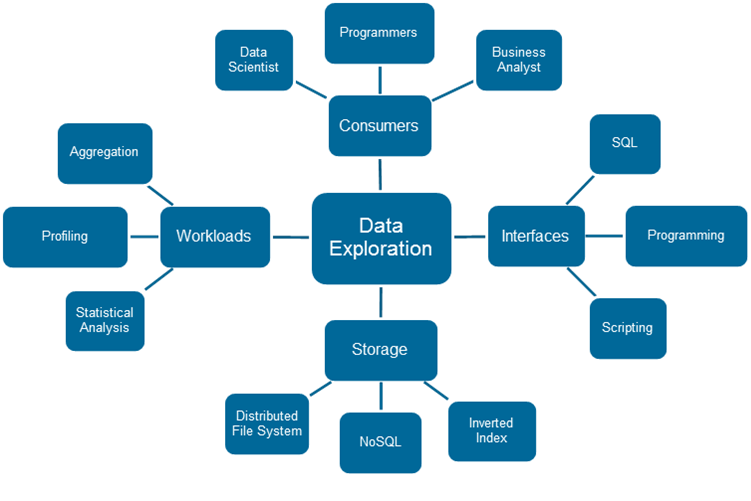
Data Lakes are expected to support each type of Data Consumer in the organization – whether they are programmers, data scientists, or business users. It is interesting to note that each one has different requirements and expectations on what data they want to consume and how they want to consume it.
Here are the key points that a Data Lake design team needs to consider when thinking about data access:
- Interfaces: Conduct Data Consumer surveys to find the tools and technologies being used in the existing environment, if any. Consumers have different skill sets and prefer to access the data stored in Data Lake using their favorite mechanisms and/or tools (e.g. SQL, scripting, programming, tools with friendly GUIs such as dashboards). All these different interfaces must be supported by the Data Lake.
- Workloads: Different consumers put different kinds of loads on the system. For example, data scientists might do ad hoc or statistical analysis to understand the data types (binary, categorical, ordinal, binomial, etc.) and identify the key attributes from these data sets, or prove a thesis about the data they see to derive value from it. Business users might interact with the system by browsing, filtering, profiling, aggregating, etc. These workloads need to be supported irrespective of the format the data is in, as the ingestion process accepts all data from all possible sources in raw format.
- Storage: To accelerate various workloads mentioned above, data needs to be stored appropriately. For example, data stored on a file system in raw format is good for scans, but needs to be indexed to support text search queries. Similarly, for key based lookups, data needs to be stored in key-value stores like some of the NoSQL databases.
- Self-service: Data Consumers should be able to work with the system (explore the data) with minimal dependency on the IT organization.
Business users and data scientists are the consumers ultimately responsible for deriving value out of the data they can explore in the lake. Exploration is a necessary, albeit not sufficient condition for being able to derive value from it. Indeed, if the data has no lineage metadata associated with it (so its origin is uncertain), or has bad quality (i.e., is incorrect, incomplete, inaccurate, inconsistent or duplicated), little or no value can be derived from it. IT is generally involved in validating and cleansing data, and new self-service data preparation tools that can be used by less technical users are also now entering the market. One way or the other, data consumers should be able to tell by themselves the quality of the datasets they discover before they explore them.
Data consumers also have preferences of how they’d like to consume the results of their analysis. Many prefers in the form of graphical reports, whereas some users would want to consume it programmatically, through APIs. Data Lake needs to take into account this requirement as well.
- Team work – Given that the Data Lake contains vast amounts of data in raw form coming from multiple sources, it might take a significant amount of time to find the correlation between data sets previously unknown. Data Lakes need to provide a collaborative team environment so that analysis and findings of one user (or group) can be shared with other users (or groups), to avoid duplicate effort and improve the overall business outcome.
To summarize: Data Consumers want Data Exploration to be F.A.S.T. 🙂
Let’s now have look at some of the options (tools and technologies) available to support a powerful Data Lake exploration environment.
Most of the Data Lake deployments today are based on Apache Hadoop. Hadoop 2.x supports different access patterns (batch, real time, lookup and graph-based to name a few) and also provides various tools like Hive (SQL), Pig (scripting), Spark (programming) and many others to query the data.
The preamble for Data Exploration, as highlighted by Mataprasad in his blog, is Metadata discovery. Once this is done, users can start exploring the data using their favorite tools like Hive, Pig and Spark to name a few.
Apache Zeppelin, a recent open source product, is getting lot of traction as a Data exploration tool. It is a web based tool that enables interactive data analytics. Zeppelin already supports many interpreters like Scala (with Apache Spark), Python (with Apache Spark), SparkSQL, Hive, Markdown and Shell. It also supports data visualization and collaborations, two of the import aspects of Data exploration.
Data Scientist prefer to use tools like R, Weka, Spark ML and other machine learning tools for statistical analysis as part of data exploration. Spark ML is preferred for BigData exploration.
Traditional Business Intelligence tools such as SAP BO, Qlik Sense, Tableau, TIBCO Spotfire, IBM Cognos also provides connectivity to (Hadoop based) Data Lake, provide easy to use exploration capabilities, and are preferred by many business users (to leverage their existing skills) for Data Exploration.
Conclusion:
The main benefit sought by a Data Lake implementation is to get some real business value out of the data it stores. This is not possible without having a flexible and powerful data exploration environment for the data consumers to explore the data way they want without depending on the IT folks. You really want to involve your Data Consumers and understand their requirements well when designing Data Exploration environment for your Data Lake.
Do you already have a Data Lake deployed in your organization? Are you facing any challenges to decide the right platform for your organization given your needs and constraints? We would be happy to discuss your organization’s Data Lake strategy and help you achieve the benefits of a successful Data Lake implementation – feel free to reach out to us @ ‘datalake [at] persistent.com’.
Here’s to a very happy ‘data exploration’ journey!
Image Credits: http://siberiantimes.com/



Find more content about
Data Ingestion (4) Data Governance (5) data security (5) Datalake (3) Data Exploration (1)











