
Machine Learning (ML) is often thought to be either supervised (learning from labeled data) or unsupervised (finding patterns in raw data). A less talked about area of ML is Reinforcement Learning (RL) — where we train an agent to learn by “observing” an environment rather than from a static dataset. RL is considered more a true form of Artificial Intelligence (AI) — because it’s analogous to how we, as humans, learn new things by observing and learning through trial and error. In this article, we explore a peculiar RL problem formulation called multi-armed bandits and understand how it can be applied to a wide variety of things — from improving the design of websites to making clinical trials more effective for patients.
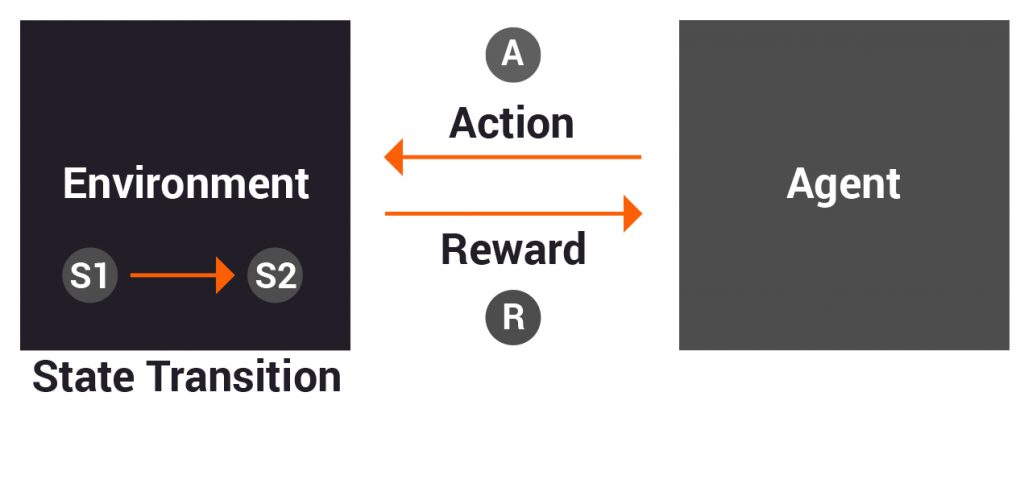
As shown in the figure below, a classic RL problem is modeled as an environment with a state (S1) which is observed by our agent and changed to state (S2) by taking an action (A). The action transitions state of the environment from (S1) to (S2) and in return the agent gets reward (R). The reward may be positive or negative. Over a series of such trials and errors the agent learns an optimal policy to take actions based on state that maximize the long-term rewards.
An example of this could be a game of chess where actions taken by the player change the state of the board and there may be immediate rewards like capturing or losing a piece and a long term reward of winning or losing the game. RL is heavily used in the gaming industry and you can imagine these agents and environments becoming more and more complex.
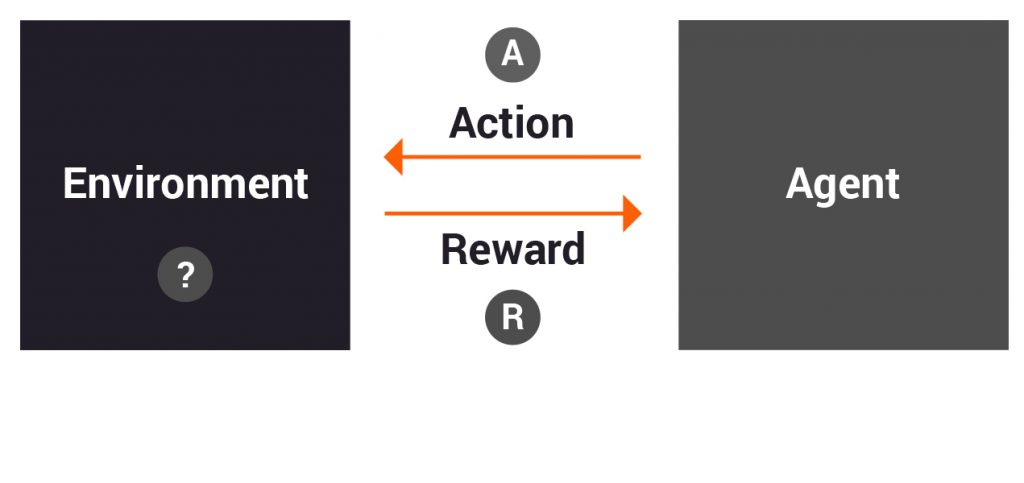
A simpler abstraction of the RL problem is the multi-armed bandit problem. A multi-armed bandit problem does not account for the environment and its state changes. Here the agent only observes the actions it takes and the rewards it receives and then tries to devise the optimal strategy.
The name “bandit” comes from the analogy of casinos where we have multiple slot machines and we have to decide if we should continue playing a single machine (exploitation) or moving to a new machine (exploration) — all with the objective of maximizing our winnings. We don’t know anything about the state of these machines — only the actions we take and rewards we get. Here we need to decide between multiple choices purely by taking actions and observing the returns. These algorithms ultimately try and do a trade-off between exploration and exploitation to identify optimal strategy.
We can better understand multi-armed bandit algorithms using the example of website design. Say, we have a new version of our website and need to decide how well it performs compared to the older version. Let’s assume that we have an effective feedback mechanism by which we know the version the user liked or disliked (reward). Our action here is to present the user with option A or B of the website. Our environment is the user visiting the website. Our reward is the feedback received.
The most obvious strategy will be to divide the users into two groups randomly and show website A to one group and B to other. So if we have 100 users, we show a random group of 50 options A and other 50 option B. Then based on which website is liked more, we decide on a design. This is the approach of pure exploration. The drawback of this is that we wait until all 100 users have seen the website to make a decision. So if option B is really bad — we waste our valuable users’ time on that option. The effect of this can be really bad when you consider this approach for a medical clinical trial. If we have two tablets A and B for a cure to a disease and drug B is low-quality — using this approach we are exposing more patients to a low-quality drug only to collect more data.
An alternate approach will be to continuously balance between exploration and exploitation. Say for 20% of users we randomly show website A or B to get an idea of which is more preferred and rest 80% we show the preferred website design. The 20% number can be tweaked based on how much exploration you want to do. Also, you may decide to explore. Further after exploiting for a while and continuously monitor the feedback. For each option. Here we are trying to balance between exploration and exploitation. Many types of such algorithms exist for solving multi-armed bandit problems, but in essence, they manage the exploration vs. exploitation trade-off and develop a strategy for taking actions.
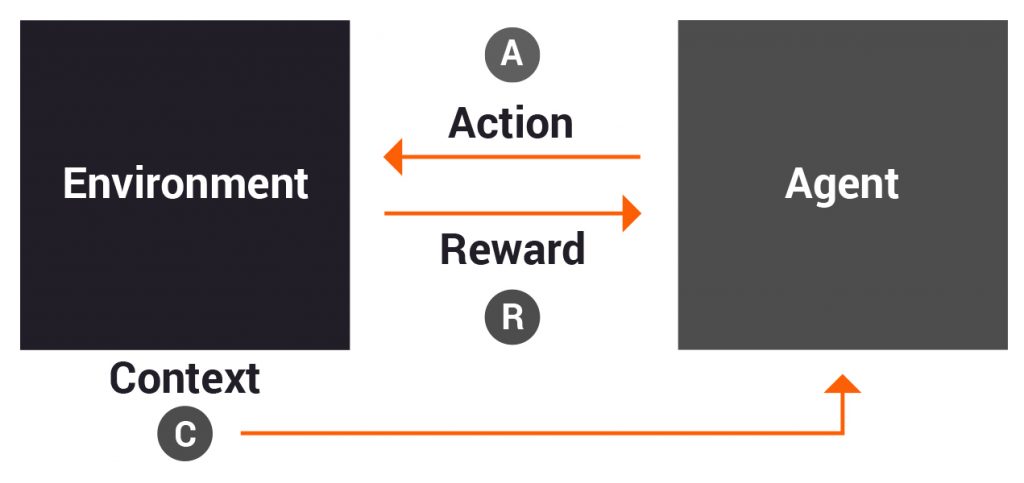
Another methodology that is gaining interest in the research community is called contextual bandits, shown in figure 3 below. Here, instead of randomly managing the exploration vs exploitation trade-off, we try and obtain some context about the environment and use that to manage the action. Context here is different than the state we talked about for a traditional RL problem earlier. Context is just some knowledge that we have of the environment that helps us take an action.
For example, if the website B uses design elements that are known to be preferred by people under the age of 30, then for users under 30 we may choose to “exploit” this context information and always show the website B. Contextual bandits are extensively used in areas like personalized advertisement to show relevant ads to consumers. We can see that in areas like website design and clinical trials also, and having the right context can go a long way in making our actions more effective. Contextual bandits are also being extensively used in recommendation systems where using explicit or implicit feedback, we try to get list of items to recommend for a user.
Traditionally if we want to recommend items to users, it is done by using methods like content and collaborative filtering. Context filtering tries to cluster similar items based on several factors and recommends similar items to ones that users have liked before. Collaborative filtering uses a “wisdom of the crowd” approach where ratings by users to items is used to provide recommendations. Both methods need extensive data before starting to provide meaningful recommendations. Using contextual bandits can correlate context to recommendations and can work well on new items and new users. These methods are used by Amazon for product recommendations and Netflix for movie suggestions. Having user context is an invaluable asset that can help provide very relevant recommendations.
At Persistent AI Research Lab, we have seen a lot of innovative uses of RL with enterprises across the banking, healthcare and industrial verticals in order to better understand user behavior and come up with advanced ML systems that capture relevant user context. We believe that the right mix for next-generation cognitive systems is to augment insights from data with context obtained from domain knowledge. Reinforcement Learning provides a significant opportunity to build learning machines that are context-aware and can tune their actions based on the environment they work in.
This article was originally published on The New Stack.



Find more content about
machine learning (13) Artificial Intelligence (11) AI (4) ML (3) Reinforcement Learning (2) Multi Armed Bandit (1) RL (1)











