
In the ever-evolving landscape of data platforms, one pattern that is gaining rapid acceptance as a modern approach is the “Lakehouse pattern,” centered around the powerful Delta Lake. At Persistent, we’ve been actively collaborating with numerous customers, assisting them in constructing robust data platforms based on this revolutionary pattern.
In this two-blog series, I am thrilled to share a treasure trove of invaluable insights and best practices acquired through extensive observation and experience. By closely studying the diverse teams’ interactions with Databricks and the hurdles they encountered, I’ve garnered essential knowledge to help you navigate the challenges and maximize your Lakehouse-based data platform endeavors. So, let’s dive in and uncover the secrets to success!
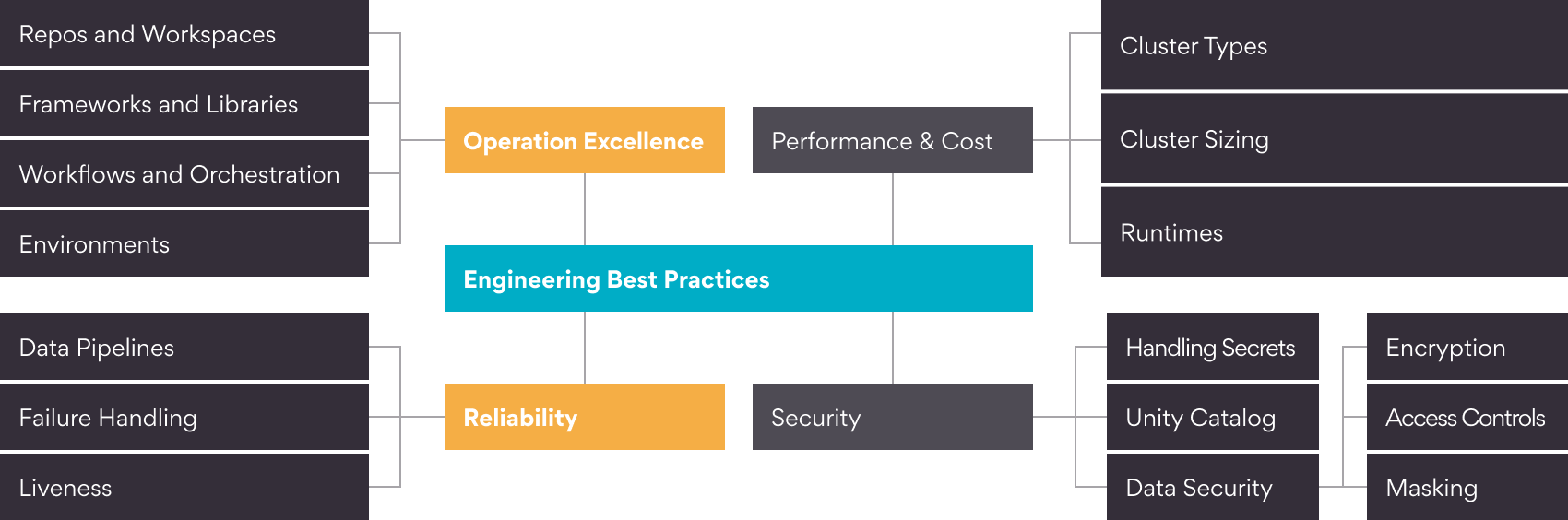
I have aligned the best practices to the following high-level areas – Operation Excellence, Reliability, Performance and Cost Optimization and Security. We will delve in to the first two areas in this blog and I will follow with a second one covering the other two areas. For this post, I will assume the implementation of a Data Lakehouse on AWS, using S3 as the storage solution and Databricks as the compute engine. However, these best practices can also be applied in scenarios not limited to AWS and Databricks.
Operational Excellence
Depending on the complexity of the transformations and the data pipeline, you may have multiple notebooks in a project executing various steps or everything in a single notebook. Here are some of the best practices to incorporate.
Use Repos and discourage the use of user workspaces
Utilize Databricks Repos for project development and effectively manage your code within the repo. It’s hard to govern if developers are using notebooks from their user workspaces. Code duplication and standards can’t be enforced, increasing dependency on individuals. My top recommendation would be to use Databricks Repos, which has excellent support for Git, Bitbucket, AWS CodeCommit, Azure DevOps support, and more.
Develop common frameworks, libraries
Encourage the teams to build common libraries. Typically, a platform team or Databricks COE can own the common libraries and frameworks and offer them to individual project teams or users. As with traditional Java, the Scala project ensures standardization, code reuse, and quick adoption of the platform. Individual project teams can focus on their specific requirements instead of common concerns such as ingestion, transformation, logging, and monitoring. Moreover, the availability of these common frameworks for data transformation, like moving from the silver to the gold layer, drives the rapid adoption of the data platform amongst various project teams.
Workflows
Databricks workflows are very powerful, and you can create a workflow in Databricks and orchestrate the same by creating dependent tasks. A Databricks Job consists of multiple tasks and each task can run a notebook, Delta Live Tables pipeline, jar, etc. You can define the cluster you want each task to use General Purpose or Job cluster and define dependencies between the tasks to orchestrate the entire pipeline. One can also set up email notifications based on job successes and failures. For a complex pipeline which is triggered by external events and not time-based, I recommend creating each step as a Job in Databricks and then using tools like Airflow to do the orchestration, which is more powerful and provides more flexibility. A hybrid model is possible where part of the pipeline is orchestrated as tasks in Databricks Jobs and part in an external tool like Airflow; however, from an operations and maintenance point of view, having it in one place is recommended.
Development environments
It is a common practice to set up separate environments and CI/CD pipelines for development, UAT, and production for traditional projects. In projects following a notebook-style approach, it’s noticeable that developers tend to create separate notebooks for each table and specific functionality. These notebooks are then executed independently in the production environment. While adopting this approach might be reasonable for AL/ML workloads due to their diverse nature, it becomes a maintenance nightmare in the case of data engineering tasks. Managing one notebook per table in such scenarios can be highly cumbersome and impractical. Ensure to write environment-aware code and common frameworks to easily promote code from one environment to another and discourage writing individual notebooks unless for a very specific task.
Reliability
With the Databricks Delta Table ACID guarantees, Delta Tables increases the data pipeline reliability many folds. Workloads are seldom a single job writing to a single delta table; they are much more complex with multiple Jobs and Delta Tables involved with interdependencies. Workloads succeed if everything in the dependency graph succeeds; in other cases, monitoring, logging, and alerting are very important to take timely actions.
Reliable data pipelines
Ensure to set up dependencies between the Databricks Jobs. I recommend using Databricks features to set up email notifications at the job or task level. However, beware of setting up email notifications for everything to everyone because then the notifications start getting treated as spam with no one monitoring them. I suggest identifying mission-critical jobs and configuring notifications for failures.
Don’t fail silently!
In various instances, developers create jobs that don’t report failures. That is where the Databricks job will show that it succeeded, but the job might have encountered failure with some exception which is caught and not propagated at the job level. This issue can lead to incredibly challenging debugging situations, particularly when dealing with a substantial number of Databricks jobs that are critical dependencies but not actively maintained. Fail-fast is always a good principle to identify problems early, and Databricks Jobs is no exception.
Concurrent writes
Databricks Delta Tables implementation supports writing to the same delta table on AWS S3 from the same or different Databricks clusters. Databricks runs a commit service in the control plane which helps guarantee consistent writes across multiple clusters on a single table. Occasionally you might run into ConcurrentAppendException or other exceptions triggered by the conflicting writes. These exceptions are retriable, and in most cases, retry will succeed, so implement exponential retries while writing to Delta tables concurrently, and it will help in reducing the Job/Pipeline failures.
Optimize, Vacuum, Generate Symlink manifest
Time the optimize, vacuum, and Symlink manifest generation for delta tables so that they are executed after your data refresh completes. Better yet, use it as a last step in your Data Workflow or Airflow DAG to ensure these operations are not executed when data write is happenings. Creating a separate Databricks job to execute housekeeping steps like optimize, vacuum, and Symlink manifest generation and execute it as the last step of your DAG is highly recommended. The common pitfalls associated with the VACCUM operation were already discussed earlier.
Conclusion
Databricks has changed the way we build data pipelines and projects, and it has unified Data Engineering, Ad-hoc Querying, and Data Governance aspects together in an easy-to-use environment that can be used by developers and data consumers alike. As with any tool, we need to play along with the prescribed and learned best practices. In this blog I have covered a best practice for Optimal Performance and Cost and touched upon Security aspect of Operational Excellence and Reliability that I’ve learned over time. Stay tuned for the Part II where I will cover the other two areas.














