
In my last blog, I talked about why cloud is the natural choice for implementing new age data lakes. In this blog, I will try to double click on ‘how’ part of it.
At Persistent, we have been using the data lake reference architecture shown in below diagram for last 4 years or so and the good news is that it is still very much relevant.
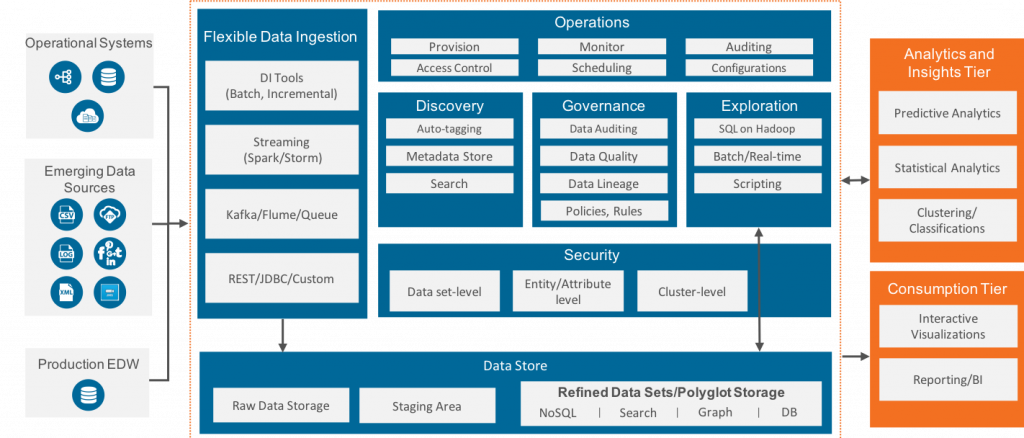
The key point of this architecture lies in the blue box which explains the importance of the 6 building blocks of a data lake,
- Flexible data ingestion
- Data Organizations in various suitable data stores
- Dataset discovery
- Governance
- Data Exploration
- Operations Management
The AWS cloud (and its ecosystem) provides technology options to each of these data lake components as explained in below diagram.
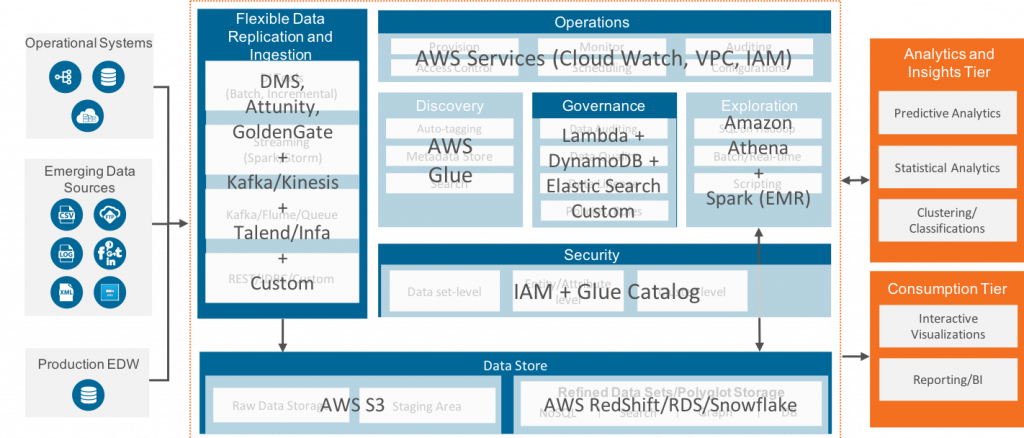
Here’s a quick list of the Salient Features of Data Lake Architecture on AWS:
- The tools like AWS DMS, Attunity & GoldenGate provide excellent mechanisms to replicate the data from Relational Databases in near real-time. All these tools are based on redo-log based change data capture (CDC) mechanisms, putting almost no-pressure on your OLTP databases.
- Kafka or Kinesis – both available as a managed service on AWS – provides a powerful mechanism to ingest streaming data in the lake.
- We can easily set up Glue Crawlers to automatically discover the schema of newly ingested data and enable metadata search on it.
- S3 is the fundamental block for storing vast amount of data in its native as well as consumable format. It supports all popular formats like CSV, Parquet and ORC. The data can be partitioned, and the storage is durable and relatively inexpensive. Further, the old data can be archived in the even cheaper storage option of Glacier, just by setting policies.
- The combination of Lambda and EMR (Spark) can be used for the standard cleansing, filtering, joining, transformation and preparation of tasks.
- Governance is a bit of a gap in the current AWS stack. The auditing and lineage tracking need to be custom implemented using a combination of Lambda, DynamoDB and Elastic Search.
- Athena is a powerful and fast SQL engine on top of S3 which can help in data explorations. The workloads which cannot be represented using SQL can be scripted in Spark(on EMR).
- Finally, AWS provides a well-integrated framework of IAM, VPC and Cloud Watch to perform the day to day operational management tasks
The good thing about the AWS data stack is that it is very much configurable and very developer friendly. ‘Providing the right tool for your use case’ is their mantra. This essentially gives us a lot of flexibility. However, this flexibility gives lot of tool choices and design options which need to be well thought through while architecting the Data Lake that suits ‘your data’ and ‘your needs’. For instance:
- Data organization on S3 has several aspects. We need to answer several questions like
- Should I use one S3 bucket for all my data or should I use multiple buckets. If using multiple bucket, what should be my split strategy?
- How should I partition the data? Do I need to manually setup partition key?
- Data Lake should support schema-on-read mechanism. How do we fully utilize it?
- How should I setup archiving scheme? What about cross region replication? Do these things play important role while deciding the S3 structure?
- Should I give S3 access to my end users? Or should I ask them to always connect through hive metastore/glue catalog
- Similarly, data transformations can be done through Lambda (serverless), Spark on EMR or using Athena. Defining which tool should be used at what place is important
- Data replication is one of the important use cases of Data Lake. Since S3 does not support updates, handling such data sources is a bit tricky and need quite a bit of custom scripting and operations management
We at Persistent have developed our own point of view on some of these implementation aspects. We call it AWS Design Patterns. My colleague utilized the slow holiday season to write these down as a series of blog articles. I am excited about this series and will share the blogs on my LinkedIn. Please watch out this space. And most importantly, please share your experiences which help all of us become smart.



Find more content about
Cloud (12) Cloud Technologies (4) Data Lake (7) AWS cloud (5) Amazon cloud (4) modern Data Warehouses (4)











