
Problem statement
With the amount of data that gets generated every day, it is difficult in an organization to have a single SQL based system. Depending on use case, the data can be in varied data sources like Hadoop data warehouses, RDBMSs, NoSQL systems, stream processing systems and so on. Furthermore, some of the data can be present as part of Data Lake and some can be present inside Data warehouse.
As a result, it becomes cumbersome to query data present in different data sources. Even if we query using different tools, the amount of time and resources needed to collect and aggregate the data is large. There can be lots of business processes/decisions that depends on running analytics on top of this data.
Solution
Presto is trying to address above mentioned problems to certain extent. It’s an Opensource distributed SQL based query engine. Presto is designed to be adaptive, flexible, and extensible. It supports a wide variety of use cases with diverse characteristics. These range from user-facing reporting applications with sub second latency requirements to multi-hour ETL jobs that aggregate or join terabytes of data. Biggest advantage of Presto’s design is that engine is kept separate from data source, which makes it ideal for decoupling engine with data. That way, same engine can be used to query from different data sources.
Presto’s design provides in-memory pipelined execution, a distributed scale-out architecture, and massively parallel processing (MPP) built in.
Presto’s Connector API allows plugins to provide a high performance I/O interface to dozens of data sources, including Hadoop data warehouses, Iceberg tables, RDBMSs, NoSQL systems, stream processing systems and so on. This connector API provides capability to add more data sources, which are not supported yet.
Presto Architecture
In a typical Presto production deployment, following components are deployed
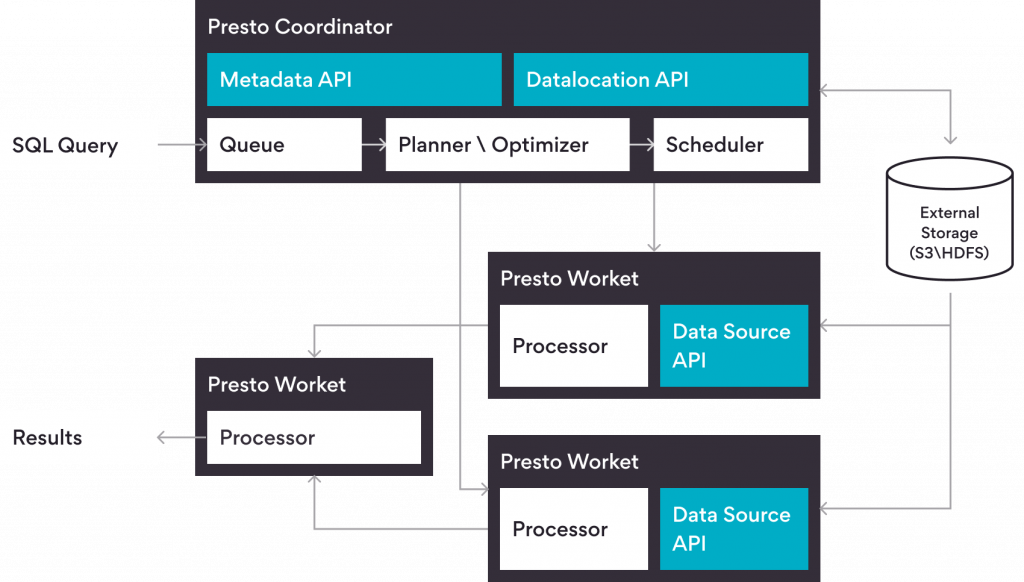
Coordinator
Coordinator is responsible for query planning and scheduling. Once a query is submitted, the coordinator splits it into multiple sub-queries and then assigns it to different workers. There is a discovery server also running inside coordinator, which listens to requests from worker nodes for registration.
Workers
Workers are responsible for executing tasks assigned by Coordinator. Once a worker is up, it uses the discovery URL provided inside config file and registers itself with the coordinator.
Resource manager
Resource manager supports Disaggregated Coordinator setup for Presto. In this setup, a single RM can manage multiple coordinators. The resource manager aggregates data from all coordinators and workers and constructs a global view of the cluster. Each cluster can have more than one resource manager. Few advantages with Resource manager.
- In single coordinator setup, coordinator is single point of failure which is handled here
- A single coordinator can get overburdened by keep on adding worker nodes
Find below list of Presto major features
- Interactive & Federated: Presto supports querying multiple data sources and provides capability to combine different data sources
- Scalable: Presto is an adaptive multi-tenant system capable of concurrently running hundreds of Memory, I/O, and CPU-intensive queries, and scale to thousands of worker nodes while efficiently utilizing cluster resources
- Extensible: Presto provides way to extend the Data sources by writing custom connectors for those. This helps in querying data from those sources which are not supported yet
- Compatible: Presto helps in querying data where it lives, so that we do not have to migrate the data from its original location
- Secure: Presto supports connections over HTTPS which provides security and encryption for data in motion. Authentication mechanisms supported are Kerberos and LDAP. In addition, connections between coordinator and workers can be secured using SSL. Presto supports access control for different users using RBAC (Role based access control)
- Opensource: Presto is maintained by Apache foundation and is backed by strong developer community
Common use cases
These are some of the common use cases that organizations are using Presto for –
Federated query across various data sources
A single SQL query can be used to query from different data sources and then aggregate the results
Querying a Lakehouse
Both structured and unstructured data Present in Lakehouse can be queried by Presto engine
Writing custom connector and managing DBs not supported by Presto yet
Add existing DBs being used by customers to the Lakehouse and develop custom connectors as required e.g., DB2, Netezza
Commercial Offerings
There are lots of commercial offerings in the market today, which are based on Presto
- Trino is a fork from Presto and was earlier known as PrestoSQL. It claims to support more and different use cases
- Ahana provides Ahana Cloud for Presto as a SaaS offering for SQL Lakehouse and Data Analytics
- Starburst Enterprise is a fully supported, production-tested and enterprise-grade distribution of open-source Trino
- AWS Athena is an interactive query service based on Presto that makes it easy to analyse data in Amazon S3 using standard SQL
Summary
Throughout this article, we have seen lots of advantages and benefits of moving towards Presto. There are some limitations too e.g., lots of data sources are not supported yet and connector needs to be developed, known limitations while using Presto SQL query for DML/DDL, no Mid query fault tolerance if something happens while executing a long running query and more.
Despite these limitations, some of the biggest organizations using it in production are Uber, Netflix, Airbnb, Bloomberg, LinkedIn, and many more. Facebook has developed and using Presto in production since 2013, with daily data average of the order of Petabytes.
In conclusion, we can see that the advantages of Presto outweighs the limitation by huge margin and provides a compelling case for Organizations moving towards Data Lakehouse to address their ever-growing data querying needs.
Originally published at https://medium.com/@guptaanurag/presto-unified-sql-based-engine-to-query-from-different-data-sources-23c984ecdd53.














