
Real-time data analytics is a critical component in today’s business world, as it enables organizations to make informed decisions quickly and stay ahead of the competition.
With a projected CAGR of 26.5 % , the real-time data analytics market is estimated to be USD 50.1 Billion by 2026 as per a MarketsandMarkets report.
Real-time data analytics is widely used across various industries, including IT, financial services, healthcare, transportation, and others, to deliver improved products and services to their customers. To effectively utilize real-time data analytics, organizations need to adopt a new data infrastructure framework that can handle the collection, storage, processing, and analysis of large and diverse data sets.
Databricks Lakehouse, in conjunction with other technologies, provides a centralized cloud data store that offers the necessary compute and flexibility to analyze data in real time.
Common real-time analytics use cases
There are a variety of use cases for real-time analytics across different industries. Here are a few common examples:
- IT InfoSec teams use real-time data processing to quickly detect, investigate, and report on cyber threats and fraudsters.
- Financial services organizations analyze billions of transactions to detect and prevent fraud. If a transaction is deemed suspicious, the system can automatically send a text to the end-user for confirmation.
- Retail companies use real-time customer analytics to personalize the customer experience and provide the right information at the right time.
- Logistic companies use real-time traffic and weather information to eliminate inefficient routes, reduce costs and improve customer experience.
Streaming data analytics architecture
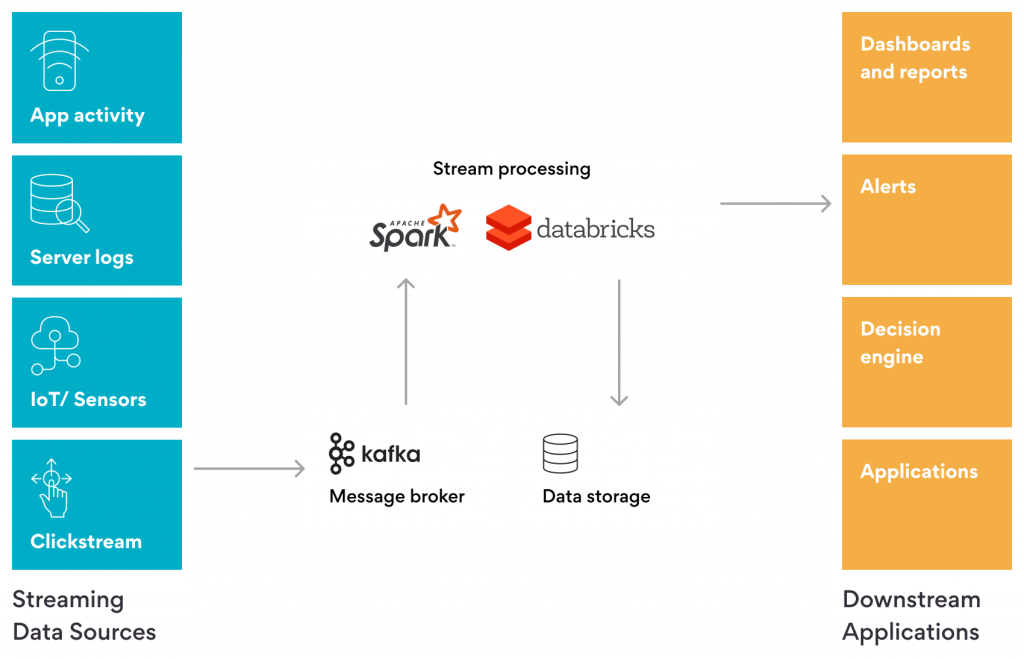
A successful real-time data analytics system must be architected to address core capabilities. Here are some building blocks and some examples and advice for execution.
Your system must be able to collect and process a continuous stream of data from various sources in real time. This can be achieved using various platforms, frameworks, tools, and programming languages, depending on the processing requirements and latency constraints.
Apache Kafka is a widely used tool for capturing data from sources such as social media, IoT sensors, web logs, and others, in the form of messages. The Kafka protocol allows multiple services to read the same messages and keep track of the amount of data read. Its storage mechanism, coupled with horizontal scaling capability, makes it fast, enabling you to process data at speed. Kafka guarantees message delivery and ordering and provides fault-tolerant, exactly once behavior.
Once the data is collected, you need the ability to correlate and process the data to provide context. This is where ELT (extract, load, transform) or ETL (extract, transform, load) tools come in handy to aggregate and transform the data consistently and in a timely manner. Apache Spark is one of the most popular tools for stream processing.
Building a production-grade real-time streaming application can be challenging, as it requires overcoming several obstacles. Long-running data processing pipelines must be resilient to failures and perform complex transformations without adding latency. When dealing with real-world scenarios, late or out-of-order data is a fact of life, and aggregation and other computations must be continuously revised as new data arrives. Watermarking is a useful mechanism for dealing with lateness.
Databricks, built on the strong foundation of Apache Spark, offers the speed and scale required to manage real-time applications in production. Its structured streaming APIs allow for easy building of production-grade streaming ETL (extract, transform, load) pipelines, helping organizations meet their service-level agreements.
The core building block in the real-time data streaming analytics architecture is the ability to make use of the processed data to gain business insights. The data processed in a consistent and timely manner can be fed to a downstream application or dashboards via a data warehouse. The data can also be visualized in the form of charts and graphs to help identify trends and patterns, which can be useful for making informed decisions.
Additionally, as data projects continue to grow, data management becomes increasingly complex. The need for broader data management to ensure reliability and security across all moving pieces is vital. This is where data governance comes into play. Data governance is the process that organizations use to maintain the quality, consistency, and security of their data. By executing a well-planned data governance strategy, organizations can ensure that their data is trustworthy and used for its intended purpose. This helps organizations make informed decisions, meet regulatory requirements, and maintain the reputation of their brand.
In conclusion, real-time data streaming applications can maximize business value by providing valuable insights and enabling quick decision making. By utilizing the right tools and data infrastructure, businesses can efficiently collect, process, and analyze data in real time, providing a competitive edge in today’s fast-paced business landscape.














