
This blog is part of the technical blog series initiated by my colleagues at Persistent. Here are the quick links of previous blogs
One of the most common usage of the data lake is to store the data in its raw format and enabling variety of consumption patterns (analytics, reporting, search, ML) on it. The data being ingested is typically of two types:
- Immutable data like twitter feeds, log files, IoT sensor data etc
- Mutable data, or the data which sees deletes and updates like ERP data or data from OLTP sources
We have seen that Amazon S3 is perfect solution for storage layer of AWS Data Lake solution. In fact, S3 is the one of the most primary reason why Amazon is most sought-after technology for building the data lakes in cloud. However, one noticeable difference is that S3 is object store which does NOT support updates. This makes the storage of Mutable data sources really challenging. The specific challenge with mutable data sources are:
- How to capture the changed data (CDC) from source system considering the security and performance penalty aspects
- How to ingest this changed data in continuous manner on S3
- How to perform near real-time synchronization of data (Sync initial load as well as Change Data Capture or change Set) with the central data store on S3
- How to manage schema detection, and schema changes
Let’s tackle these questions one by one.
Question 1: How to capture the changed data (CDC) from source system considering the security and performance penalty aspects?
As the eco-system is getting more and more mature, fortunately there are bunch of options available. Some examples are AWS Data Migration Service, Attunity Replicate, Informatica Power Center, Talend, Apache NiFi, and last but not the least, Apache Sqoop.
At Persistent we had evaluated and implemented these tools for our customers based on their ingestion requirements. Below are some key criteria’s we generally consider before choosing these tools: —

Please get in touch with us for the detailed comparison of these tools on above evaluation criteria that supports your needs.
Question 2: How to ingest this changed data in continuous manner on S3 ?
Here we are taking data coming from multiple data sources and putting it in S3 based data lake.
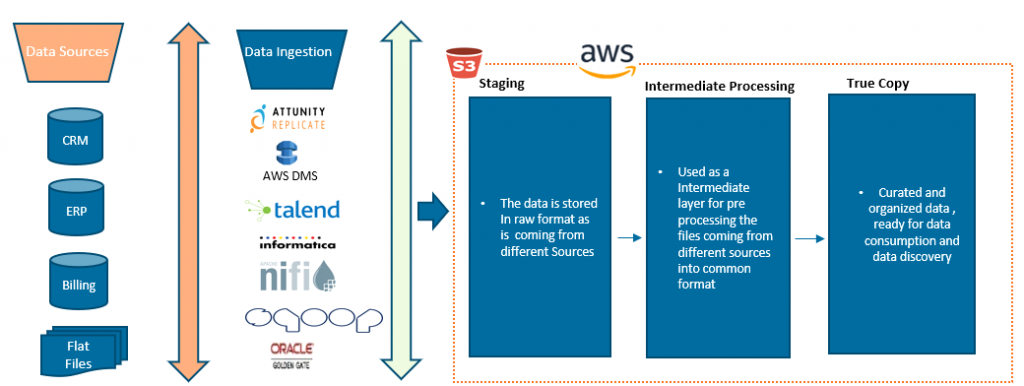
Staging area will be used to Ingest and stores the raw data in native format as it is coming from different tools (like Attunity replicate, talend, informatica, Apache NiFi, Sqoop etc.)
Intermediate processing layer: The focus is to convert data collected in staging layer to common format, apply data quality or validity checks that are necessary before data can be landed in the True Copy Zone. Data Pre-processing can be done using AWS Lambda and Spark.
True Copy area will have curated data that is ready to query for business users. I have covered the working of this layer in more detail in next question
Question 3: How to perform near real time synchronization of the data (CDC Merge)?
Once the raw data started coming on data lake and getting stored on Landing area, the next major task is to do near real time CDC (Change data capture) merging for change data coming in near real time from Source systems and merge it with current snapshot in Data Lake.
Let me brief first about what is Change Data Capture
It is a process of capturing data changes instead of dealing with the entire table data. It just captures the data changes made to source systems and apply them to the Data lake to keep both of your databases in sync. Here is a table which shows the change data capture for Table X at a given time
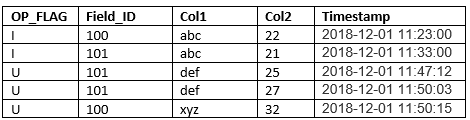
Table X has 5 columns: —
- a OP_FLAG indicating which type of change (I/U/D (insert /update/delete)),
- a Field_ID column is a primary key (uniquely identifies the record)
- Col1 and Col2 are columns that changes when record get updated, and
- a TIMESTAMP indicating when the change on record happened.
In Table T, Field ID 100 was inserted and updated (first and last row). For Field ID 101 was inserted and updated 2 times (row 2,3 and 4)
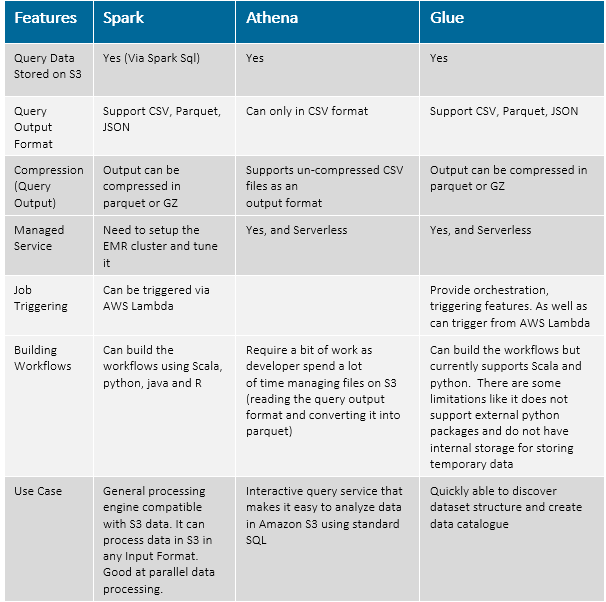
The Preferred Technology options to do CDC Patching on AWS Data Lake are:
- Spark
- AWS Glue
- Athena
Here is the brief comparison among them to choose the right technology at right place
We recently implemented these CDC patching techniques using Spark for data coming from different data sources and ongoing data replication is also frequent in nature. The key challenges that we had to handle are:
- The incremental data captured by CDC tool was in different format based on the CDC tool
- There can be multiple change records for same row within one incremental data-file
- The incremental-data file can have insert followed by update for same row
- The incremental-data file can be very small or very large (depending on the table)
- The base table can be very small (dimensional table) or very large (transaction tables)
- There can be several hundred tables being constantly merged in CDC Merge job
We used approach similar to 4 step strategy for incremental updates in Apache Hive. However, we had to add several enhancements as discussed below to address above challenges.
Partitioning at S3 level also helped us to process every change set along with columnar formats and data compression. For more information, we are going to cover it in our next blog “S3 File organization for Data Lake”
Important points of this pipeline: —
- Persistent developed this pipeline not only helps existing CDC pipelines but also accelerates time to use this pipeline for other sources as this is generic code written using Spark 2.0 that can be deployed easily for other sources with minimum configuration changes
- Using the concept of Mapping files, we are using the YAML based configuration files that stored the attributes like Partition key, Query for Insert, Update and Delete that spark SQL can easily use for CDC patching.
This is one of the AWS design pattern we can use across different customers to solve the common CDC patching problem for S3 based data Lake.
Typical Architecture for this design pattern: —
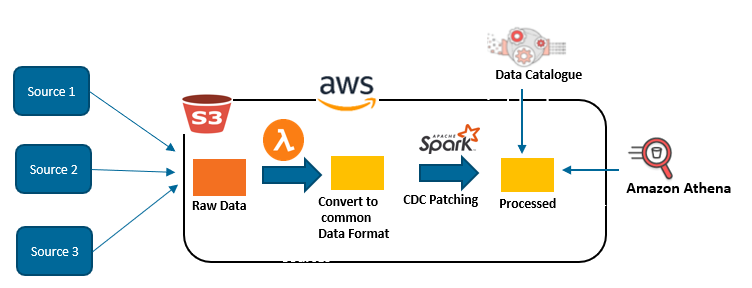
In the above figure, Raw data is ingested from different sources. The data is then converted into common data format to make it available for CDC patching for each table. In this case, the raw delimited files are CDC merged and stored into Apache Parquet for use by Amazon Athena to improve performance and reduce cost. In this example, an AWS Lambda function is used to trigger the pipeline every time a new change set is added to the Raw Data S3 bucket. This whole process is a design pattern that can be used to synchronize data in data lake and at the same time business users can derive business value from a variety of data quickly and easily.
AWS Glue crawler creates a table for processed stage based on a job trigger when the CDC merge is done. The tables can be used by Amazon Athena and Amazon Redshift Spectrum to query the data at any stage using standard SQL.
Question 4: How to manage schema detection, and schema changes
Changes applied to the schema at source systems must be propagated continuously. The ingestion process must be generic enough so that schema evolution are automatically detected and propagated to target systems. Here are scenarios related to schema changes at source side: —
- Add column
- Drop column
- Rename column
- Change column data-type
Couple of approaches we can follow here to manage this: —
- Option 1 (Automate metadata capture): – Use Tools like Attunity replicate which automatically detect the changes in metadata for source systems and propagate to target systems and use Attunity compose to update the schema as your metadata changes.
- Option 2(Custom framework): – Keep the metadata information on Data Lake and compare it with new change set enters the data lake. In that case, framework can automatically generate the new mapping file with metadata and CDC patching starts applying the schema changes for new change set. Although in this case we must run the utility manually one time to apply the schema changes on existing data set.
- Option 3 (Avro File format): – Avro is also one of the option here that supports backward and forward evolution. As Avro is the only format as of now that supports maximum schema evolution, it made sense for me to recommend a format that can be modified as the source modifies its schema. Below is a small description on what level of schema evolution is supported in Avro format.
- Avro supports addition and deletion of columns at any position.
- Avro supports changing column names via changing the aliases.
- Avro does not support data type changes.
Final notes:
In this blog, I have presented a design pattern for handling Change data capture from different OLTP sources, converting the change data sets into common data format and merging change set using Spark into True Copy snapshot. In upcoming blogs, I’ll focus on how business user can smoothly access this data and get meaningful insights out of S3 based DataLake.
Want to get your first data-driven business use-case in 2 weeks? Talk to us now!



Find more content about
Cloud (12) Cloud Technologies (4) Data Lake (7) AWS cloud (5) Amazon cloud (4) modern Data Warehouses (4)











