
Data Lake is becoming a natural way to architect large datasets and processing around it. As we saw in our earlier blog, Data Lake hosts enormous amount of data. Hence organizing this data is of utmost importance. If not organized, it can become the dreaded Data Swamp in no time. By definition, the data lake stores data in its most natural form. Hence it may seem that there is no need to organize this data! However, that is not true. Even in Data Lakes, we need to be well organized with respect to the data.
AWS provides a classic way to organize such data. In this blog, we will see ways and patterns to organize data in data lakes using AWS S3. When it comes to Data Lake storage on AWS, S3 becomes a natural choice. Amazon S3 is designed to provide 99.999999999% durability, scalability and performance.
This blog is a part of series of blogs on design patterns while setting up a data lake on S3. As a part of this blog, we answer many of the questions raised in the earlier blogs. The other blogs that are published are as below:
- Data Lake in AWS Cloud
- Data Lake Architecture in AWS Cloud,
- To Data Lake or to not Data Lake
- Data Replication and Change Data Capture in AWS Data Lake
Organization of data in S3
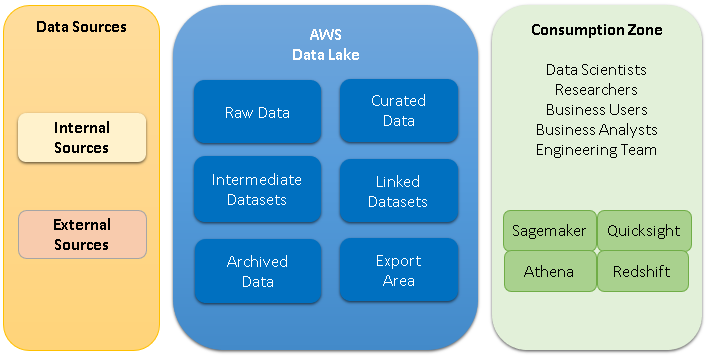
Let us refer to the below architecture diagram for the concepts. All the data coming in from various sources will be organized into the following sections.
- Raw Data, is the section where the data from the source, is stored as is.
- Curated Data, is the section where all the data is cleansed using data quality rules and is available for the analysis.
- Intermediate Datasets store the datasets and tables required for transformations to run.
- Linked Datasets are the denormalized or summarized aggregated datasets derived from the original data that are useful for multiple use cases.
- Archived Data, is the section where unnecessary or less often referred data is moved into. This may be moved into Glacier or such storage system, that is available for less cost.
- Export Area is the place where the datasets are created for moving the data to external area like indexes or data marts.
For all Data Lakes implementations, we will at least have raw data section and the linked data sections. All the raw data with the incremental changes will be maintained in the raw data section. The linked and intermediate data sections may be added as needed to provide the data that is most optimal for the users. The archived data can be made into a separate section if archiving is enabled.
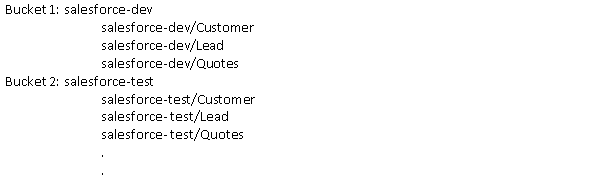
The data organization problem is the most complex with storing raw data. The mechanisms discussed below can also be applied to other sections too. In the raw data section, one way to organize the data will be to store it in the buckets that are identified by the data source names. For example, for the data coming in from the CRM you can have one bucket identified with CRM as the name. In that bucket, create objects with appropriate names to identify the tables uniquely. Object and bucket names should also indicate the environment in which they are getting created. For example, salesforce-dev for development environment and salesforce-test for test environment.
A second way to organize this data is to have one bucket per table. However, there is a default upper limit on number of buckets per account (100) in S3. This can be increased by requesting AWS but is a maintenance overhead. If you have too many tables, then there would be too many buckets.
Other considerations
Storing Incremental data and history data
We will need to store and merge the incremental data per table in the Lake. We can create objects having full qualification for the exact timestamp for which the changes are stored. The object names should be written so as to optimize the performance. As shown in the picture below, we usually store an object that has complete data for the table and multiple objects that have the incremental data per date or timestamp.

Partitioning large tables
When the data in a single table is very huge, it makes sense to further partition it into multiple objects. By partitioning, we can restrict the amount of data scanned by each query. This results into improvement in performance and cost reduction. Often the data is partitioned based on time or date – that is dependent upon how the data is grouped for access or how the data arrives and at what frequency etc. Partitioning can be manually added using alter table statements or can be done in an automated way (provided object keys follow a specific pattern).
Optimizing for access patterns
Data over time, may not be used frequently. However, it needs to be made available for analysis when needed. We need to plan a strategy and automate it such that the data that is used very frequently (hot) can be kept on Hadoop layer or can be kept into Redshift. Data that is used more often can be kept on S3 (warm) and least frequently used data (cold) is moved to cold storage like Amazon Glacier. Performance for retrieval will vary based on the storage system that is used so would be the cost that is paid for each.
File formats to consider
There are multiple formats in which the data can be stored on S3. To decide on format, think about file sizes, data type support, schema changes over time, performance you need for write and read and the integration with other systems. The formats available are CSVs, Avro, Paruet, ORC etc. Avro format stores data in row-wise format. Parquet and ORC file formats store the data in columnar way. The basic difference between and Parquet and ORC is that ORC use snappy for data compression, so the data is more compressed in ORC compared to Avro.
Data Processing
Now that the data is into the Data Lake, how is this data used? Like I mentioned in my previous blog, the trend in data warehouse architectures today is to diversify the portfolio of data platforms. Users can choose just the right platform for storing, processing, visualizing data sets. Users like data scientists who are techno-savvy would like to access it using tools like Athena or Python. They would run machine learning algorithms to derive deep insights. BI tools like Tableau also provide connectivity to the data through Athena. Spectrum is another tool that is provided by Redshift where analytics can be run across Redshift and S3. The datasets that are needed for dashboards and everyday analysis, can be pushed to Redshift or such database system on which BI tools can be run for scheduled reports.
Conclusion
The most important aspect while designing the data lake file organization is to design it such that it is optimized for both, data retrieval and simplicity of organization. In this blog we explored various ways to organize data in S3 buckets and naming of objects within them. Further we looked at other considerations like partitioning and storing aggregates.
Start your data-driven journey with Persistent Data Foundry today



Find more content about
Cloud (12) Cloud Technologies (4) Data Lake (7) AWS cloud (5) Amazon cloud (4) modern Data Warehouses (4)











